TiSpark 4.0 用户指南
TiSpark 4.0 是什么
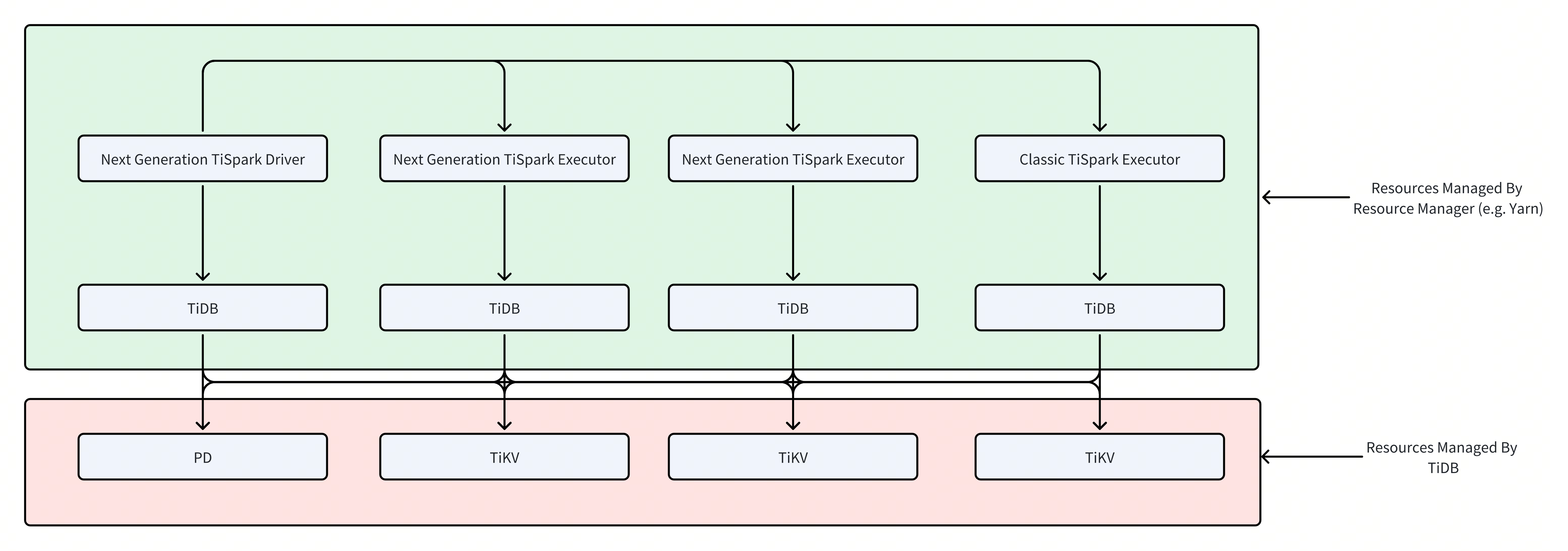
TiSpark 4.0 架构进行了重构,不再直接依赖于 TiKV 集群和 Placement Driver (PD),而是通过标准的 JDBC 接口与 TiDB Server 进行通信。这使得 TiSpark 成为 TiDB 的一个标准客户端,极大地简化了部署、运维和安全管理。
TiSpark 深度整合了 Spark 的 Catalog 机制,在提供标准数据源体验的同时,通过向 TiDB 查询系统表 TABLE_REGIONS 来获取表数据的 Region 分布信息。基于这些信息,TiSpark 能够将查询任务智能地拆分为多个子任务,并分发到 Spark Executor 执行。每个子任务仅负责一个数据分片 (Split),从而实现了高效的并行数据读取,从根本上解决了传统 JDBC 数据源在读取大数据表时常见的数据倾斜问题。
通过 JDBC 协议,TiSpark 将计算下推到 TiDB 执行。这充分利用了 TiDB 强大的分布式 SQL 引擎和内置的统计信息,由 TiDB 优化器选择最优的查询计划,从而减少了 Spark 需要处理的数据量,提升了整体查询效率。
注意
TiSpark 4.0 通过 TiDB 进行所有的数据访问,因此 TiDB Server 使用的访问控制和权限管理机制完全适用于 TiSpark,提供了统一且可靠的安全保障。
版本要求
- TiSpark 支持 Spark 3.0 或以上版本。
- TiSpark 需要 JDK 1.8 以及 Scala 2.12 版本。
- TiSpark 需要 TiDB v7.1.8-5.4 或以上版本(需要 TiDB 支持系统表 TABLE_REGIONS)。
- TiSpark 可以运行在任何 Spark 模式上,如
YARN、Mesos以及Standalone。
推荐配置
TiSpark 作为 Spark 的 TiDB 连接器,需要 Spark 集群的支持。本文仅提供部署 Spark 的参考建议,对于硬件以及部署细节,请参考 Spark 官方文档。
由于 TiSpark 4.0 的计算下推至 TiDB Server,在进行大规模数据分析时,可能会对 TiDB 集群造成较大压力。建议评估 TiSpark 的查询负载,并为 TiDB 集群预留充足的计算资源,或部署专门用于承载分析负载的 TiDB Server 节点。
对于独立部署的 Spark 集群,可以参考如下建议配置:
- 建议为 Spark 分配 32G 以上的内存,并为操作系统和缓存保留至少 25% 的内存。
- 建议每台机器至少为 Spark 分配 8 到 16 核 CPU。起初,你可以设定将所有 CPU 核分配给 Spark。
可以参考如下的 spark-env.sh 配置文件:
SPARK_EXECUTOR_MEMORY = 32g
SPARK_WORKER_MEMORY = 32g
SPARK_WORKER_CORES = 8获取 TiSpark 4.0
TiSpark 是以第三方 jar 包的形式提供给 Spark 使用的。
获取 mysql-connector-j
由于 GPL 许可证的限制,TiSpark 不提供 mysql-connector-java 的依赖。在使用 TiSpark 时,需要你手动下载 mysql-connector-java-8.0.29.jar 或更高版本,并使用以下方式引入:
-
将
mysql-connector-java.jar放入 Spark 的jars目录下。 -
在你提交 Spark 任务时,通过
--jars参数引入mysql-connector-java.jar,详见以下示例:spark-submit --jars /path/to/spark-tidb-connector-<version>.jar,/path/to/tidb-jdbc-core-<version>.jar,/path/to/mysql-connector-java-8.0.29.jar
选择 TiSpark 版本
你可以根据 TiDB 和 Spark 版本选择相应的 TiSpark 版本。推荐使用 TiSpark 的最新稳定版本。
| TiSpark 版本 | TiDB 版本要求 | Spark 版本 | Scala 版本 |
|---|---|---|---|
| (TBD) | >= v7.1.8-5.4 | 3.x | 2.12 |
Note
旧版 TiSpark(直接连接 TiKV)与 TiDB v6.5 及之后版本不再保证兼容。强烈建议升级到 TiSpark 4.0 以获得更好的稳定性和功能支持。
获取 TiSpark jar 包
联系客户经理获取软件包。
快速开始
本章节将以 spark-shell 为例,介绍如何使用 TiSpark。请保证您已安装并配置好 Spark 环境。
配置并启动 spark-shell
在 Spark 的配置文件 conf/spark-defaults.conf 中添加如下 TiDB Catalog 相关配置:
# 指定使用 TiSpark 的 Catalog 实现
spark.sql.catalog.tidb_catalog io.tidb.bigdata.spark.TiDBTableCatalog
# ========== TiDB Catalog 连接配置 ==========
spark.sql.catalog.tidb_catalog.type jdbc
# 替换为你的 TiDB 连接地址、端口和目标数据库
spark.sql.catalog.tidb_catalog.url jdbc:mysql://127.0.0.1:4000/test?rewriteBatchedStatements=true&defaultfetchsize=-2147483648
spark.sql.catalog.tidb_catalog.user root
spark.sql.catalog.tidb_catalog.password # 留空或填写你的 TiDB 密码
spark.sql.catalog.tidb_catalog.driver com.mysql.cj.jdbc.Driver
# 替换为你的 TiDB 目标表 (TBD)
spark.sql.catalog.tidb_catalog.dbtable t1警告:
如果你的 TiDB 用户没有设置密码,请确保
spark.sql.catalog.tidb_catalog.password配置项被注释或值为空。提供不正确的密码或为一个没有密码的用户提供password配置项,可能会导致连接失败。
配置完成后,使用如下命令启动 spark-shell,需将 TiSpark 的 jar 包、TiDB JDBC Core 的 jar 包和 MySQL Connector/J 的 jar 包通过 --jars 参数传入。
# 替换为你的 tispark-assembly jar 包实际路径
spark-shell --jars /path/to/spark-tidb-connector-<version>.jar,/path/to/tidb-jdbc-core-<version>.jar,/path/to/mysql-connector-java-8.0.29.jar使用 TiSpark 读取数据
通过 Spark SQL 和配置好的 tidb_catalog 从 TiDB 读取数据:
// 读取 tidb_catalog 中 test 数据库下的 t1 表
spark.sql("select count(*) from tidb_catalog.test.t1").show()TiSpark 配置
TiSpark 4.0 的主要配置都集中在 Spark Catalog 的定义中。你可以在 spark-defaults.conf 中配置,或在提交任务时通过 --conf 选项传入。
| Key | Default value | Description |
|---|---|---|
spark.sql.catalog.tidb_catalog | (无) | 必需。 指定 Catalog 的实现类,固定为 io.tidb.bigdata.spark.TiDBTableCatalog。 |
spark.sql.catalog.tidb_catalog.type | jdbc | 必需。 指定 Catalog 类型。 |
spark.sql.catalog.tidb_catalog.url | (无) | 必需。 TiDB 的 JDBC 连接字符串。格式为 jdbc:mysql://<host>:<port>/<database>。 |
spark.sql.catalog.tidb_catalog.user | (无) | 必需。 TiDB 用户名。 |
spark.sql.catalog.tidb_catalog.password | (无) | 连接 TiDB 的密码。如果用户没有密码,请勿设置此项。 |
spark.sql.catalog.tidb_catalog.driver | com.mysql.cj.jdbc.Driver | JDBC 驱动类名。通常无需修改。 |
spark.sql.catalog.tidb_catalog.dbtable | (无) | 连接 TiDB 的目标表。设置此项无作用。 |
注意
所有旧版的
spark.tispark.*配置参数(如spark.tispark.pd.addresses)均已废弃,不再生效。
FAQ
问:为什么要用 JDBC 架构替换掉原来直连 TiKV 的架构?
答:这是为了提升 TiSpark 的长期可靠性、可维护性和用户体验。旧架构与 TiKV/PD 内部协议耦合过深,导致 TiDB 内核升级时 TiSpark 难以兼容和维护。新架构通过标准的 JDBC 接口与 TiDB 解耦,使 TiSpark 成为一个普通的 TiDB 客户端,从而获得以下好处:
- 高可靠性:利用成熟稳定的 TiDB Server 处理事务和请求,避免了 TiSpark 客户端逻辑的复杂性。
- 易于维护:TiSpark 不再需要跟随 TiKV/PD 的内部协议变化,可以独立迭代。
- 更好的兼容性:可以轻松与任意新版本的 TiDB 以及云上的 TiDB 服务(如 TiDB Cloud)集成。
- 统一的安全模型:所有权限都由 TiDB 统一管理,更加安全、简单。
- 可观测性:所有查询都会经过 TiDB Server,可以使用 TiDB 的监控和日志工具进行追踪和诊断。可以通过 SQL hint 获取 Spark 进程,以便在 TiDB SQL 运行异常时及时 Kill Spark 进程。
问:新架构如何解决普通 JDBC 数据源的数据倾斜问题?
答:TiSpark 并非一个普通的 JDBC 数据源。它通过查询系统表 TABLE_REGIONS 从 TiDB 获取表的 Region 分布信息,每个 Region 对应 TiKV 上的一个数据范围。TiSpark 以此信息为依据,将 Spark 的任务(Task)与 TiDB 的 Region 做一对一或多对一的映射,确保每个任务处理的数据量大致均衡,从而实现了高效的并行读取并避免了数据倾斜。
问:旧版本的 TiSpark 还能继续使用吗?
答:已发布的旧版本 Classic TiSpark 在其对应的 TiDB 版本生命周期内会继续提供支持。但新功能开发和对新版本 TiDB(v6.5 之后)的兼容性适配将只在新架构的 TiSpark 上进行。我们强烈建议用户迁移到 TiSpark 4.0。
问:迁移到新架构需要注意什么?对资源有什么影响?
答:主要的变化是计算负载的转移。原先部分在 Spark Executor 中完成的解码和计算工作,现在完全下推到 TiDB Server。因此,你需要确保 TiDB Server 集群有足够的计算资源来处理来自 Spark 的分析型查询。你可能需要增加 TiDB Server 节点的数量,或将其与在线的 OLTP 负载进行物理隔离。