

当数据库的主要用户不再是人类,而是每秒创建数千个实例的 AI Agent,你的数据底座准备好了吗?
2026年4月,PingCAP 联合创始人兼 CEO 刘奇在 AI Summit London 抛出一个震撼行业的观点:“The primary users of databases are no longer humans.” 这句话并非危言耸听。在 Kimi、Manus、Dify 等头部 AI 平台的生产环境里,超过 90% 的数据库实例已经由 AI Agent 自动创建、查询和销毁。传统的单机数据库在这种"Agent 风暴"面前不堪一击,而 TiDB,正成为先进 AI 团队的首选数据底座。
01. Kimi 的选择:头部 Agent 平台为什么放弃 Supabase 选择 TiDB
2026年初,月之暗面 Kimi K2.6 的 Agent 建站服务正式上线。这是一个完全由 Agent 接管端到端应用构建的场景:用户只用文字描述需求,Agent 自动生成前端、后端、数据库 schema,并直接托管上线。这种"零代码建站,发布带数据库的网站"模式的用户门槛极低,但基础设施挑战极大。
Kimi 团队最初也调研过 NeonDB、Supabase 等名气更大的 Serverless 数据库方案,但最终选择了 TiDB Cloud。原因很现实:如果每个 Agent 配一个真实的 PostgreSQL 实例,在上百万个站点并发创建的场景下,成本会直接爆炸。Kimi 团队甚至实测过用单个大型 PostgreSQL 实例配合多 Schema 做租户隔离,结果在万级规模时就扛不住了,更不用提流控、故障半径控制和数据隔离问题。
TiDB Cloud 的虚拟数据库架构彻底改写了游戏规则。
传统 Serverless 数据库(如 Supabase)的架构是"一个 Sandbox 分配一个真实的数据库实例",为了成本控制,冷却时会被回收,很难保证 7x24 永远在线。而 TiDB Cloud 引入了一层虚拟数据库界面:Agent 看到的仍然是完整的独立数据库,但物理层面只有一个常驻的 DB Session Gateway 服务负责维持连接,其他所有资源都是弹性的,底层由封装了对象存储的分布式 KV 提供存储服务。
这种架构转变带来了三个核心收益,也是 Kimi 团队最终拍板的关键:
| 维度 | 传统 Serverless DB (Supabase/Neon) | TiDB Cloud 虚拟架构 |
|---|---|---|
| 实例成本 | 每个 Agent 一个真实实例,百万级实例成本爆炸 | 无真实实例,仅虚拟界面,成本数量级下降 |
| 冷启动 | 实例休眠后需唤醒,Agent 需写 retry/poll/wait 逻辑 | Warm Pool + Scale-to-zero,1 秒内拿到 fully prepared 实例 |
| 技术栈统一 | Agent 需适配多种数据库方言 | 统一 MySQL 协议,LLM 生成代码成功率大幅提升 |
| 弹性上限 | 单实例万级租户即出现瓶颈 | 分布式 KV 底座,天然支撑千万级虚拟租户 |
Kimi 对 TiDB Cloud 的评价非常精准:选 TiDB 的核心原因不在某一个单点指标的极致,而在于"per-tenant 多租隔离、统一栈、即时弹性"这三件事同时做到位时,它是少数几个把每一项都"够用且顺手"的系统。
02. Manus:从 200 万 waitlist 到每秒数千次 Agent 迭代
“Manus 1.5 uses TiDB X to let agents ship full-stack apps at scale.” (Manus 1.5 采用 TiDB X,助力代理大规模交付全栈应用。)
如果说 Kimi 代表了"Agent 建站"场景,那么 Manus 则代表了"通用 Agent 执行"场景的极限压力测试。
Manus 的 viral 爆发期极具戏剧性:两周内积累超过 200 万 waitlist 用户。其"Context Engineering"模型要求每个任务支持数千次状态迭代,每次迭代都需要独立的存储空间进行实验。传统架构下,如果每个 Agent 创建一个 5 美元/月的数据库实例,三个月内近 100 万个租户的成本将直接击穿商业模式。
Manus 迁移到 TiDB Cloud 后,两周内完成基础设施切换。其工程团队给出的评价是:“TiDB’s elastic architecture enabled us to migrate in two weeks, supporting users and massive ‘Context Engineering’ workloads for viral success.” (TiDB 的弹性架构使我们仅用两周时间便完成了迁移,从而有力支撑了用户群体及海量的“上下文工程”工作负载,助力我们实现了病毒式传播的巨大成功。)
更关键的是 Manus 1.5 引入的 Agent Swarm 架构。当用户要求"搭建一个现代电商网站"时,Manus 不会只走一条路径,而是同时派出多个 Agent 并行探索 React+Node.js、Next.js+Serverless、Vue+Python 等多种技术栈。每个探索路径都需要独立的数据库 schema 和测试数据,避免冲突和污染,最终合并最优结果。
TiDB 的 Serverless Branching 能力在这里发挥了决定性作用。通过 Copy-on-Write 快照技术,Agent 可以在秒级 fork 出独立的数据库分支,随意建表、删表、跑实验、写垃圾 SQL,而不会影响主库或其他 Agent。这种"分支即隔离"的架构,让 Manus 得以支撑数千个并发 Agent 的"Wide Research"集群,实现真正的并行智能探索。
从第三方视角看,这不是孤例。过去 12 个月,国内外 AI Agent 团队的基建选型正在收敛到同一个范式:one agent, one sandbox, one storage, one database。
03. Dify:50 万个数据库容器的整合之路
“Dify consolidated hundreds of thousands of containers onto TiDB.” (Dify 将数十万个容器整合到了 TiDB 上。)
Dify 是 GitHub 上 7 万+ Star 的 LLM 应用开发平台,定位是帮助开发者快速构建生成式 AI 应用。它的数据层需求极其复杂:既要存储文档块和向量嵌入,又要保存对话历史、用户配置、工作流状态,还要支撑运营分析。
在迁移到 TiDB 之前,Dify 的数据层是一个令人头疼的"大杂烩":近 50 万个数据库容器分散在不同系统中,工程师不得不花费大量精力在数据库运维上,而非构建 Agent 功能本身。
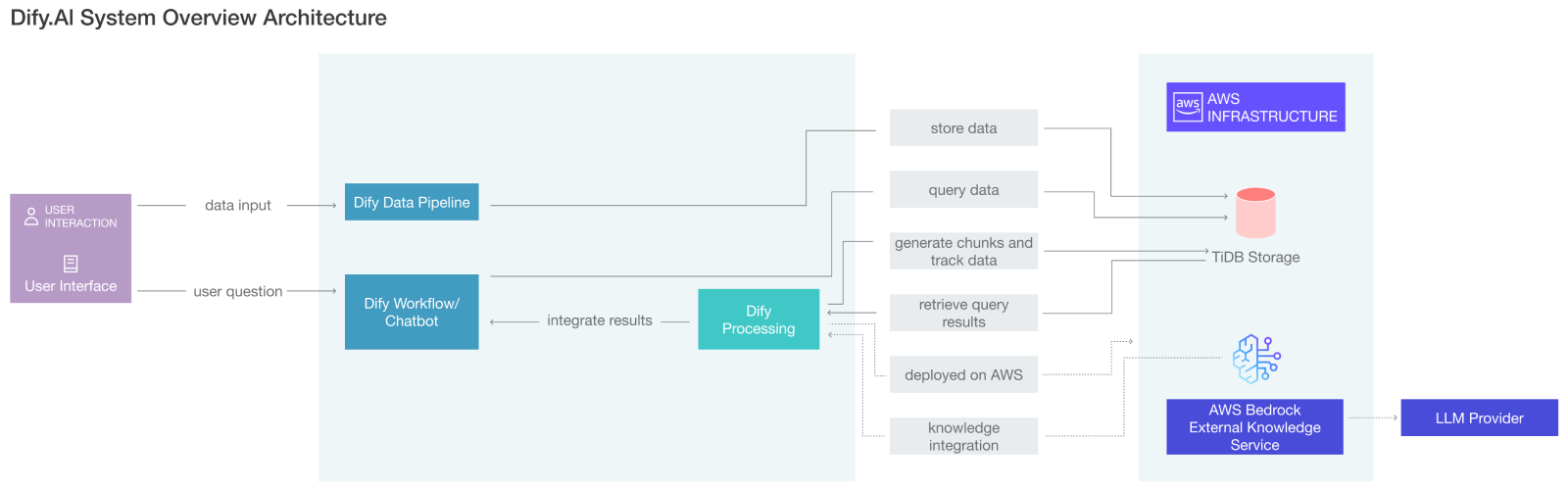
迁移到 TiDB 后,Dify 将这 50 万个容器整合为统一系统。TiDB 的 HTAP 能力(TiKV 行存 + TiFlash 列存)让交易型数据和分析型数据在同一集群内实时处理,无需构建复杂的 ETL 管道。最终的结果是:基础设施成本降低 80%,运营开销减少 90%。
Dify 的案例特别能说明一个问题:AI 应用的数据层不再是简单的"增删改查",而是向量、全文、关系、时序、JSON 的多模态融合。TiDB 的统一查询引擎让 Dify 无需维护向量库+图数据库+关系库的三件套堆栈,一套系统解决所有问题。
04. Atlassian:750 个 PostgreSQL 集群的极限整合
Atlassian 的 Forge 插件平台是一个更"传统"但规模更极端的 SaaS 场景。它采用单 schema 单租户模式,需要在一个系统中托管超过 300 万张表。在此之前,Atlassian 维护着 750 个独立的 PostgreSQL 集群。
迁移到 TiDB 后,Atlassian 获得了几项关键提升:DDL 吞吐量提升 6-7 倍,单集群验证 50 万并发活跃连接,节点初始化时间从 20 分钟缩短至 2 分钟。

Atlassian 的案例对 AI 团队有特殊的参考价值:它证明了 TiDB 不仅能支撑 Agent 的"轻量级、短生命周期"实例,也能承载传统 SaaS 的"重量级、长生命周期"多租户负载。当 AI 应用从原型走向商业化,从实验走向企业级交付,这种"从小到大"的无缝扩展能力至关重要。
05. 先进 AI 团队为什么都选择了 TiDB
把 Kimi、Manus、Dify、Atlassian 四个案例放在一起看,能提炼出一些超越具体场景的共性优势。这些优势解释了为什么 TiDB 正在成为 Agent Infra 的共识选择。
优势一:虚拟化架构带来的成本数量级下降
这是 Kimi 案例中最突出的发现。传统 Serverless 数据库按实例计费,在 Agent 场景下边际成本线性增长。TiDB Cloud 的虚拟数据库界面让"百万级实例"变成"一个 Gateway + 弹性 KV 后端",成本结构从 O(n) 降到接近 O(1)。对于商业模式还在探索期的 AI 创业公司,这往往是“斩杀线”。
优势二:MySQL 协议降低 LLM 的"认知摩擦"
Kimi 团队提到,统一技术栈对 LLM 来说直接关系到生成代码的成功率。少跨一个系统就少一类 bug,多用 Skill 中写好的技术栈和最佳实践,而不是每次靠思考和抽卡。TiDB 完整兼容 MySQL 协议,市面上所有主流 LLM(GPT-4、Claude、Kimi 自身)的训练数据中都包含了海量的 MySQL 代码,故而生成正确 SQL 和 ORM 配置的概率远高于小众数据库。
优势三:秒级生命周期匹配 Agent 的"脉冲式"工作模式
Agent 不是人类,它不会"登录数据库客户端、谨慎地写 SQL、提交事务、优雅退出"。Agent 的工作模式是脉冲式的:突然创建 1000 个实例、疯狂写入、查询几次、然后销毁。TiDB 的 Warm Pool + Scale-to-zero + Branching 让这种脉冲变得顺滑,Agent 无需在代码里写 retry、poll、wait 那一套防御性逻辑。
优势四:多租隔离与故障半径控制
Kimi 实测 PostgreSQL 大规模 Schema 方案时,万级租户就遇到瓶颈。TiDB 的分布式架构天然支持 per-tenant 隔离,每个 Agent 看到的是一个逻辑上独立的数据库,但物理上共享同一个高可用集群。这种隔离不仅体现在数据层面,也体现在资源配额、流控策略和故障半径上。
优势五:HTAP 统一数据层避免"数据孤岛"
Dify 案例很好体现了这一点。AI 应用既需要低延迟的 OLTP(对话状态、用户配置),又需要实时的 OLAP(行为分析、模型效果评估)。传统架构需要两套系统加 ETL,TiDB 的 TiFlash 列存引擎让两者在同一集群内实时完成,数据新鲜度从"小时级"变成"秒级"。
06. 真实问题:TiDB 在 AI 场景下的挑战与局限
说了这么多优势,从第三方视角也必须坦诚地讨论 TiDB 在 AI 场景下面临的真实问题。这些不是"黑料",而是选型时需要权衡的技术债务。
问题一:分布式事务的"兼容性陷阱"
TiDB 虽然兼容 MySQL 协议,但毕竟是分布式架构。某些边缘场景下的事务行为与单机 MySQL 存在差异,比如悲观锁的实现细节、自增 ID 的连续性保证、以及部分系统变量的支持范围。对于由 LLM 自动生成的代码,这些差异可能导致难以调试的 bug。Kimi 团队选择 TiDB 的前提之一,就是 Agent 生成的是相对标准化的 CRUD 代码,避开了这些边缘场景。
如果你的团队正在寻找替换 MySQL 的单机版数据库,不妨试试 平凯数据库(TiDB 企业版)敏捷模式。
问题二:对象存储 backbone 的延迟敏感性
TiDB X 将对象存储作为平台 backbone,这带来了极致的弹性和成本优势,但也引入了冷数据访问的延迟问题。对于 Agent 的"热路径"(高频查询、实时对话状态),如果数据被下沉到对象存储,响应时间可能从毫秒级跳到百毫秒级。因此,TiDB 的冷热分离策略需要仔细调优,不能"一刀切"。
问题三:大规模 DDL 的稳定性边界
Atlassian 案例提到 DDL 吞吐量提升 6-7 倍,这反过来也说明"大规模 DDL"曾是 TiDB 在陪跑客户成长时遇到的实际痛点。在 Agent 场景下,Agent 会频繁创建和删除表、索引、数据库,DDL 的并发执行能力直接影响体验。虽然 TiDB 最新版本有了显著改善,但在极端场景下,仍需要谨慎的资源管控和队列管理。
问题四:从传统数据库迁移的学习成本
对于已经深度绑定 PostgreSQL 或 MySQL 生态的团队,迁移到 TiDB 并非零成本。虽然协议兼容,但运维范式完全不同:TiDB 的 Region 调度、TiKV/TiFlash 混合部署、PD 调度器调优等,都需要 DBA 重新学习。Atlassian 能两周完成迁移,很大程度上得益于 PingCAP 团队的贴身支持,这不是每个团队都能复制的条件。
国内用户可以试试 平凯数据库云服务,新内核,易运维。平凯数据库云服务何以不同?新一代内核带来全新代际的云服务
07. 业界参考价值:Agent Infra 的范式转移
这些头部 AI 团队的实践,对整个行业有什么参考价值?笔者认为至少有五点值得深思。
价值一:从"实例计费"到"请求计费"的成本哲学
Kimi 和 Manus 的案例揭示了一个残酷的现实:Agent 时代的数据库成本结构完全变了。传统数据库按实例/节点/容量计费,在 Agent 场景下会线性爆炸。TiDB 的虚拟架构本质上是一种"请求计费"模式:只有真正发生读写请求时才消耗资源,空闲的虚拟实例几乎零成本。这可能倒逼整个云数据库行业重新定价。
价值二:LLM 友好型数据库的定义
过去评价数据库的标准是 TPS、QPS、延迟、容量。但在 Agent 时代,"LLM 友好"成为新的核心指标:协议是否主流(影响代码生成准确率)、冷启动是否够快(影响 Agent 工作流顺畅度)、技术栈是否统一(影响系统复杂度)。Kimi 选择 TiDB 的理由中,“统一栈"的权重甚至高于"极致性能”。
价值三:"一核三态"适配混合云+信创双重要求
平凯数据库的"一核三态"架构(敏捷模式、标准模式、聚能模式)对国内 AI 企业特别有参考价值。很多国企和金融机构在探索 AI 应用时,既要满足信创合规(国产化替代),又要支撑 AI 工作负载的弹性伸缩。TiDB 的三种部署形态让同一套技术栈既能跑在私有化环境(聚能模式),又能扩展到公有云(标准模式),还能快速原型验证(敏捷模式),避免了"信创一套、AI 一套"的技术栈分裂。
价值四:RAG 架构的"去复杂化"趋势
Dify 的案例说明,AI 应用的数据层正在从"最佳工具组合"走向"统一平台"。过去构建 RAG 应用需要向量库(Milvus/Pinecone)+ 图数据库(Neo4j)+ 关系库(PostgreSQL)+ 缓存(Redis)的组合拳。TiDB 的向量+全文+HTAP 三位一体能力,让一套系统替代了原来的四件套,不仅降低运维复杂度,也减少了 LLM 在多系统间协调的失败率。
价值五:从"人类用户"到"Agent User"的数据库设计哲学
刘奇在 AI Summit 上的判断值得所有数据库从业者深思。当数据库的主要用户变成 Agent,设计哲学需要根本转变:人类用户需要漂亮的 GUI、详尽的文档、友好的错误提示;Agent 用户需要毫秒级的冷启动、原子化的隔离、可预测的成本、以及无需重试的确定性。TiDB 的 Branching、Warm Pool、虚拟数据库等特性,本质上都是在为"Agent User"重新设计交互界面。
08. TiDB X 与平凯数据库:企业级 AI 底座的技术演进
2026年1月22日,平凯星辰正式发布平凯数据库(TiDB 企业版)全新"一核三态"架构,基于同一内核衍生出三种部署形态,破解数据库选型中"水平扩展、业务透明、极致性能"难以兼得的"不可能三角"。
| 部署模式 | 适用场景 | 核心特征 | AI 场景匹配度 |
|---|---|---|---|
| 敏捷模式 | 开发测试、边缘业务 | 存算聚合,一键部署 | 适合 Agent 快速原型 |
| 标准模式 | 生产级 OLTP/OLAP | 3~∞ 节点存算分离,水平扩展 | 支撑大规模 Agent 集群 |
| 聚能模式 | 高并发核心交易 | 存算聚合+亲和调度,接近单机性能 | 适合 AI 金融级关键业务 |
2026年4月23日,PingCAP 凭借 TiDB X 荣获美国商业奖金 Stevie Award 大数据与报表分析解决方案类金奖。TiDB X 的核心突破在于将对象存储作为平台 backbone,实现根据工作负载模式、业务周期和数据特征自动伸缩。
对于 AI 团队而言,TiDB X 提供的统一查询引擎在单一分析层中融合向量、知识图谱、JSON 和 SQL 数据,支持多跳推理、长期记忆和版本化分支存储。AI 开发者工具包(TiDB AI SDK、TiDB Reasoning Engine、TiDB MCP Server)原生集成 OpenAI、Hugging Face、Cohere、Gemini、Jina 和 NVIDIA,是目前最开放的分布式 SQL AI 构建平台之一。
在国产化替代和信创合规的背景下,平凯数据库已经在国内金融、电信、政务等关键行业大规模落地。协议兼容降低迁移风险,HTAP 消除数据孤岛,云原生适配混合云战略。平凯数据库云服务 已开启免费试用。
结语
从 Kimi 的百万级 Agent 建站服务,到 Manus 的 Swarm 集群,再到 Dify 的 50 万容器整合和 Atlassian 的 300 万表超大规模 SaaS,TiDB 已经用生产级案例证明了自己在 AI 时代的架构优势,并且正在成为先进 AI 团队的数据底座首选。
数据库的 AI 原生时代已经到来,选择 TiDB,就是选择了一个能与 Agent 共同进化的数据底座。
BTW, 小道消息,5月20日,特别的日子 TiDB 会带来特别的“AI 产品”,期待一下。
Have a nice day ~ ☕
🌻 TiDB 往期内容 ▼
- TiDB Radio | 平凯宇宙新鲜事儿 (2026.03.31)
- Manus:TiDB是其数据存储基座
- TiDB X: 以对象存储为核心要素构建全新AI原生数据库
- 时隔三年我又冲了一次TiDB专家认证
- 使用 Navicat Premium 连接平凯数据库(TiDB 企业版)敏捷模式
👉 这里有得聊
如果对国产基础软件(操作系统、数据库、中间件)、AI、Vibe Coding、OpenClaw 、Hermes Agent 等感兴趣,可以加群一起聊聊。关注微信公众号:(少安事务所),后台回复[群],即可看到入口。如果这篇文章为你带来了灵感或启发,请帮忙『点赞、推荐、转发』吧,感谢!ღ( ´・ᴗ・` )~