老鹰506
(Ti D Ber Uhzt Tfx J)
1
【TiDB 使用环境】生产环境
【TiDB 版本】7.5.3
【操作系统】
【部署方式】云上部署
【问题复现路径】
【资源配置】
【遇到的问题:问题现象及影响】
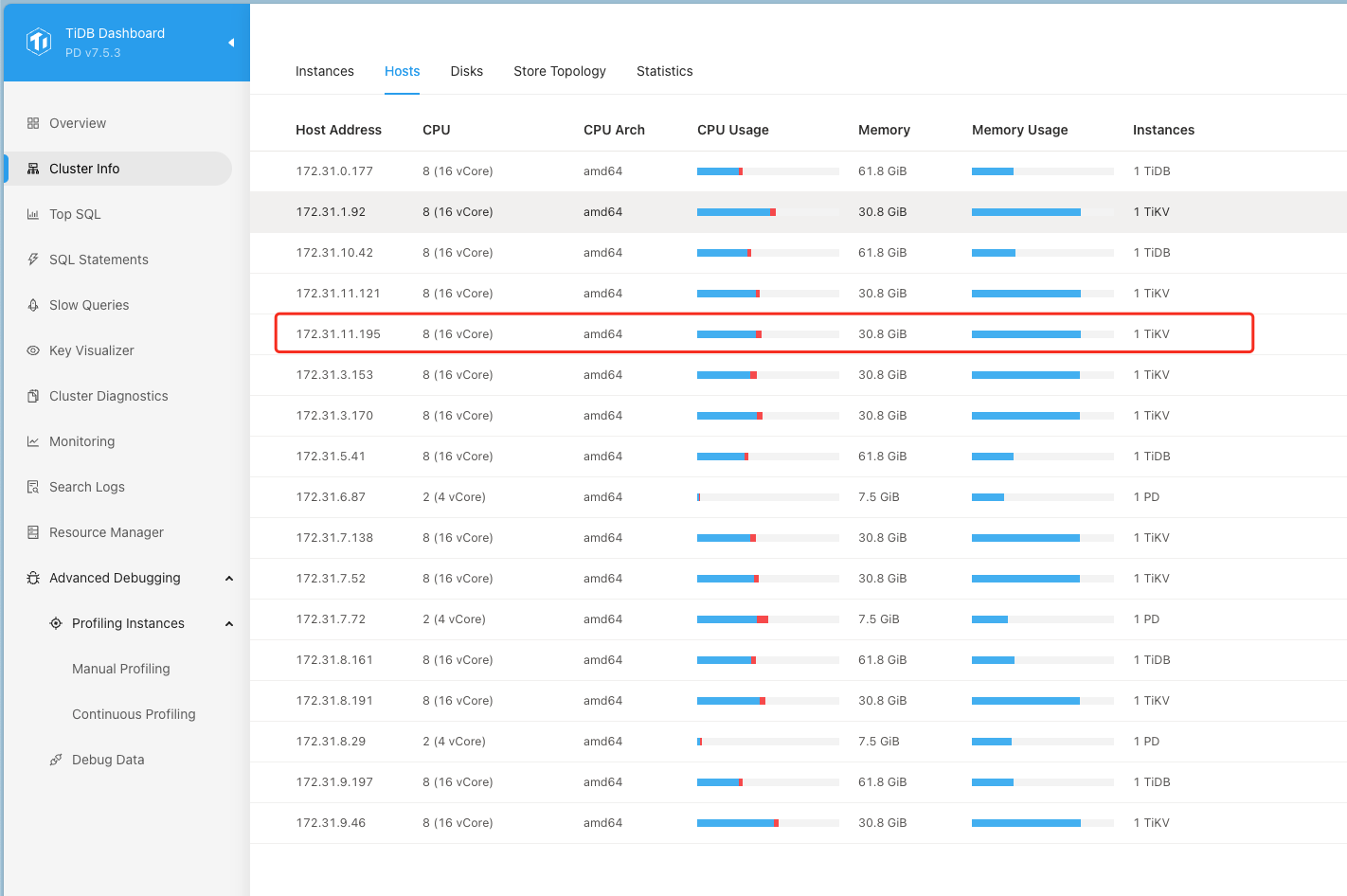
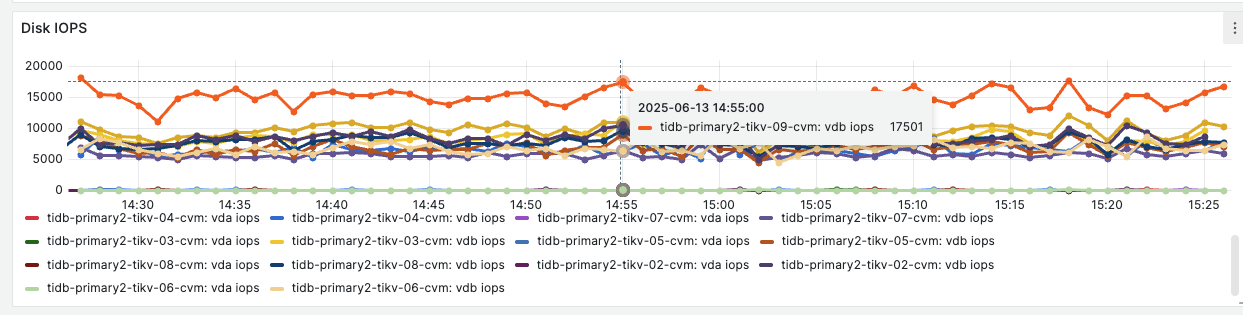
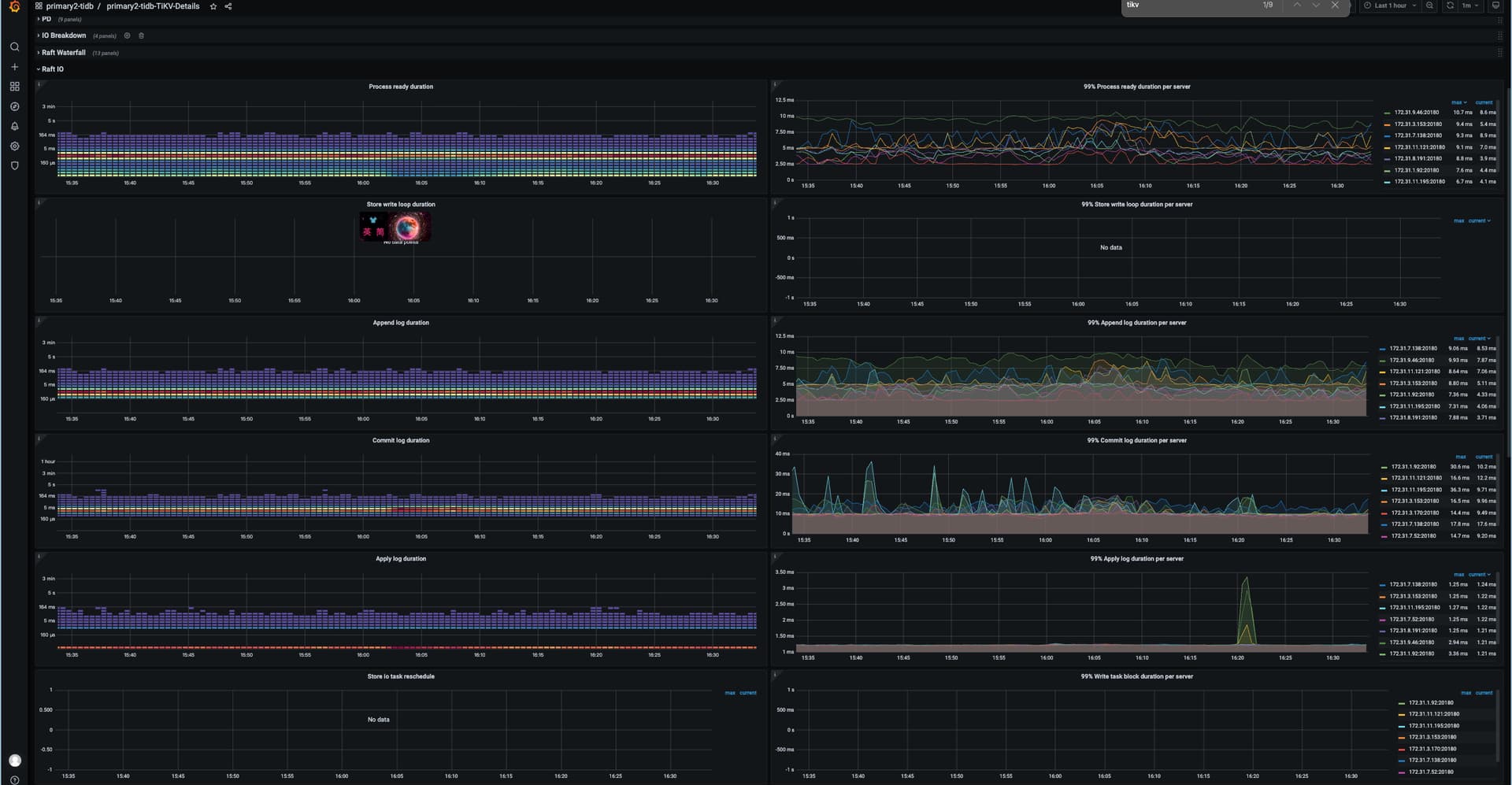
从下面给出来的主机监控发现这个tikv节点的 iops明显比其他的节点要高出来一些。
从TIDB的grafana 的 cluster-tidb-TiDB 页面的 ”kv request" 中看到 store-5也就这里的问题节点 172.31.11.195 (tikv-01-cvm) 节点的 “KV request duration 99 by store" 也明显高于其他节点
然后统计分析了各tikv节点的存储,Leader 、region的情况,分布是基本均衡的
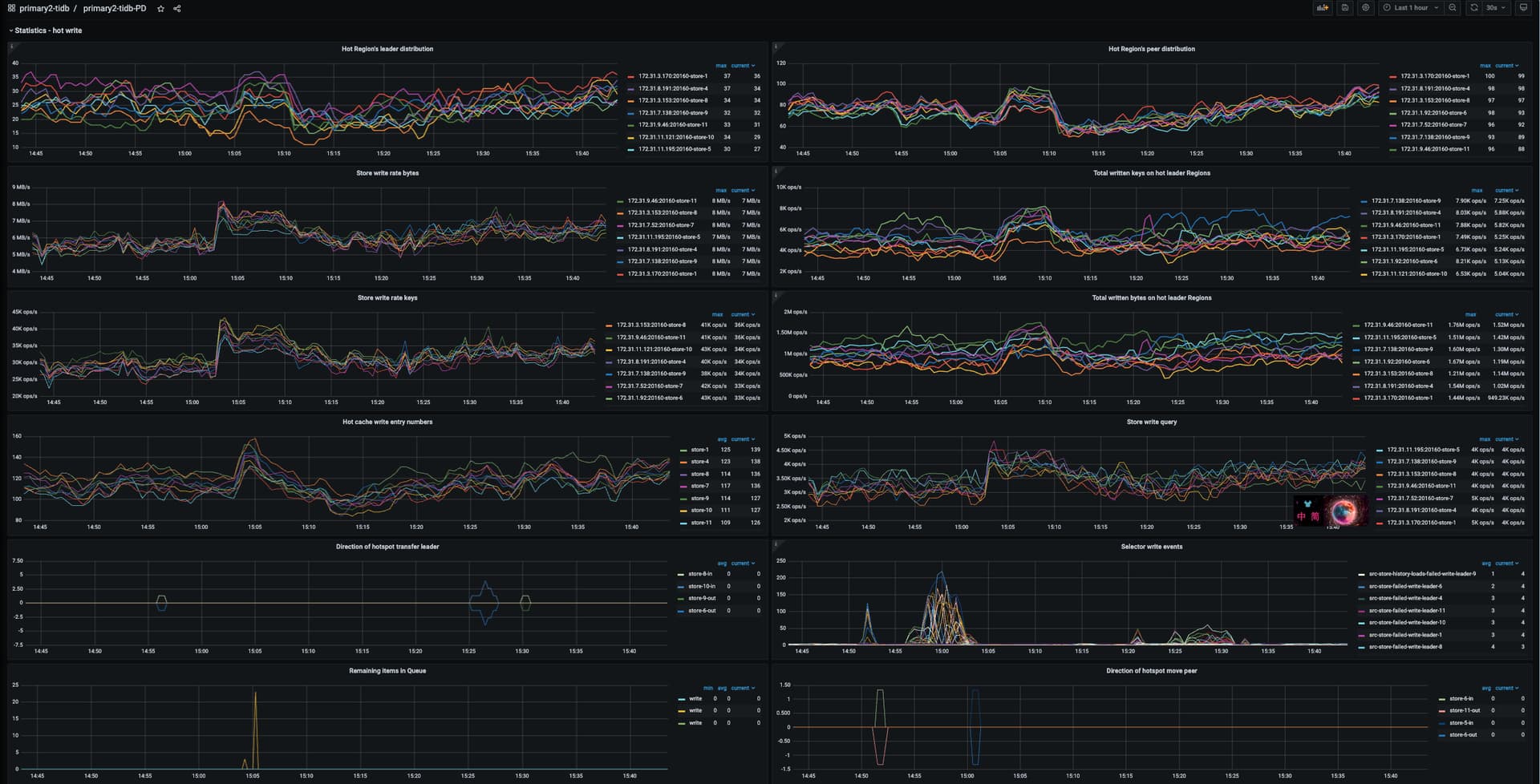
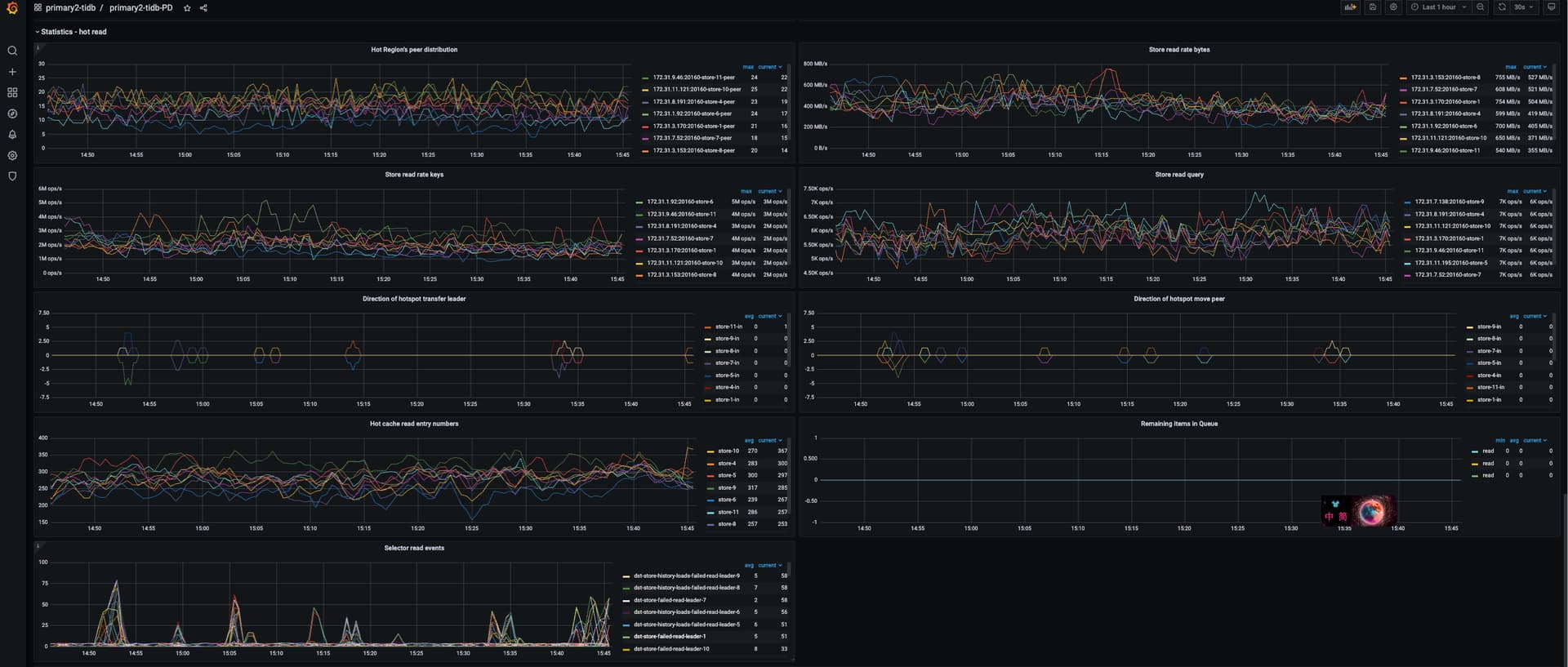
也看了 hot write/ hot read 没有发现这个节点有明显异常
求教还能怎么分析这个节点是什么到只iops 、 kv request duraion 99 比较异常呢?
1 个赞
CC噶勒鸡
(Ti D Ber 0 I Fh E Gc Y)
2
这种情况一般是某张表数据量较小数据集中在这个kv上了,在topsql中看下这个节点有没有全表扫描的执行计划。
2 个赞
CC噶勒鸡
(Ti D Ber 0 I Fh E Gc Y)
5
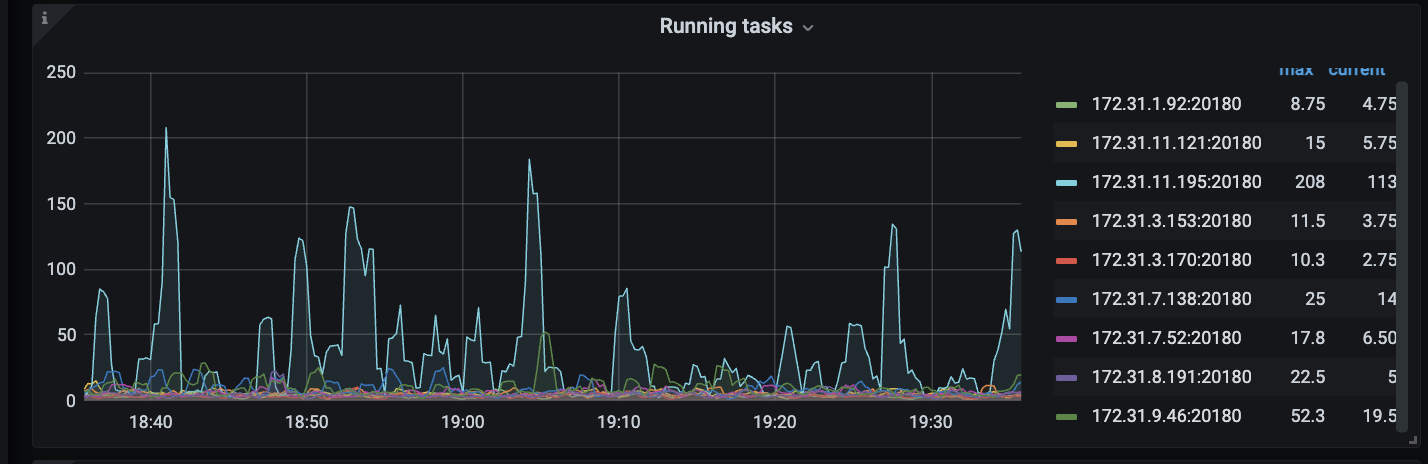
那感觉同时读线程池和pd面板 hotread应该也有突增的情况出现
1 个赞
1、看下store-5节点的磁盘读写延迟是否和其他节点相近,先排查磁盘没问题
2、iops明显高很多,有可能是其他服务在也在大量占用磁盘,用iotop查一下
1 个赞
有猫万事足
7
老鹰506
(Ti D Ber Uhzt Tfx J)
8
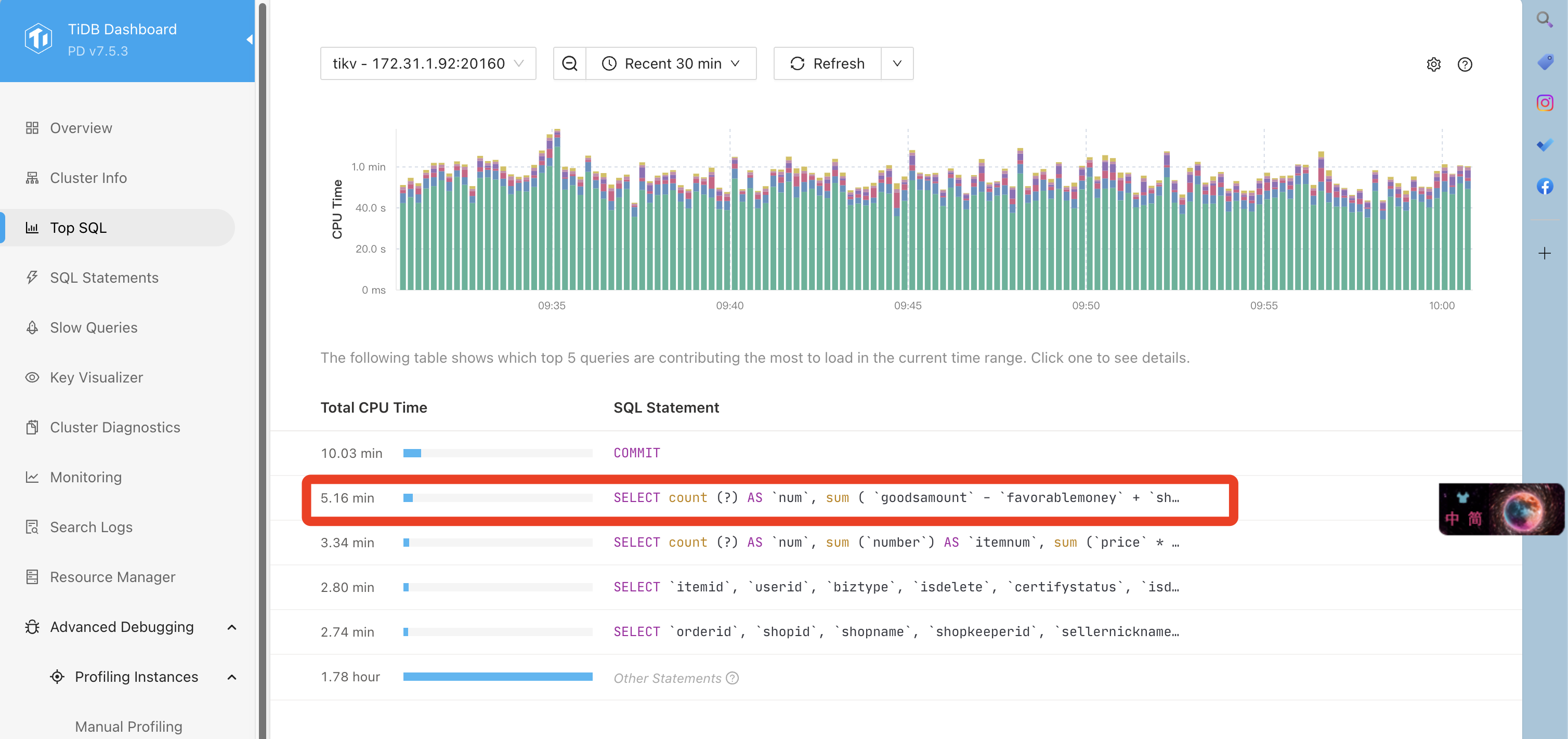
如何确认某张表的查询都集中在这个tikv上呢? topsql 中看到的5个查询SQL没有在其他tikv节点也有,没有办法判定它们影响了这个主机吧
老鹰506
(Ti D Ber Uhzt Tfx J)
10
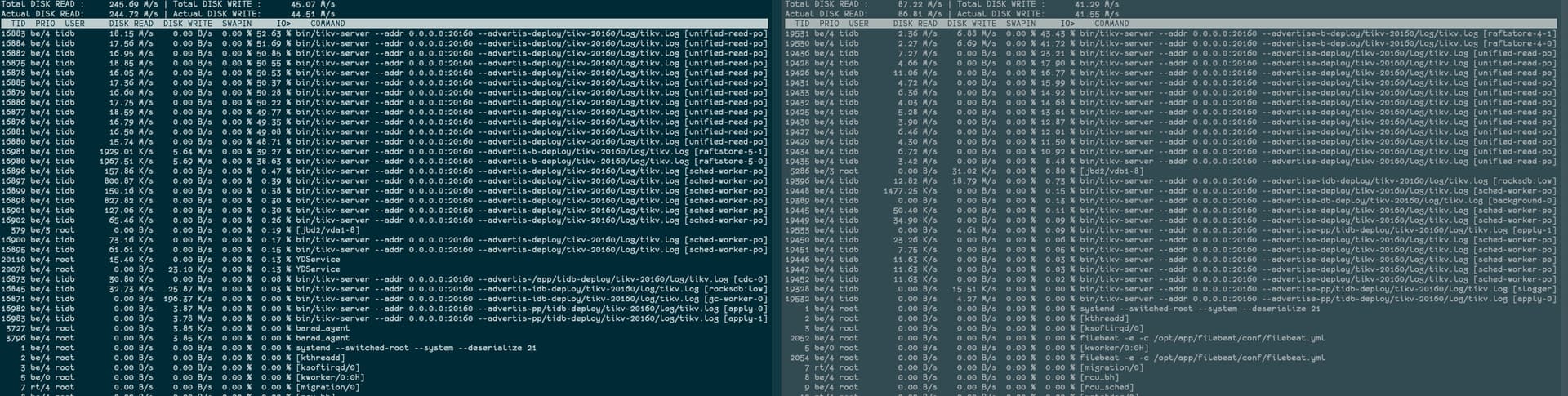
1、磁盘都是云主机统一采购,应该不是磁盘的问题
2、iops明显高很多, 这个确实是,但是iotop看到的都是tikv进程的
左边是问题主机,右面是找了个对比主机,看不来有什么问题
左边的tikv读写流量比右边高不少,感觉还是热点问题。
看下unified read pool的监控
有猫万事足
13
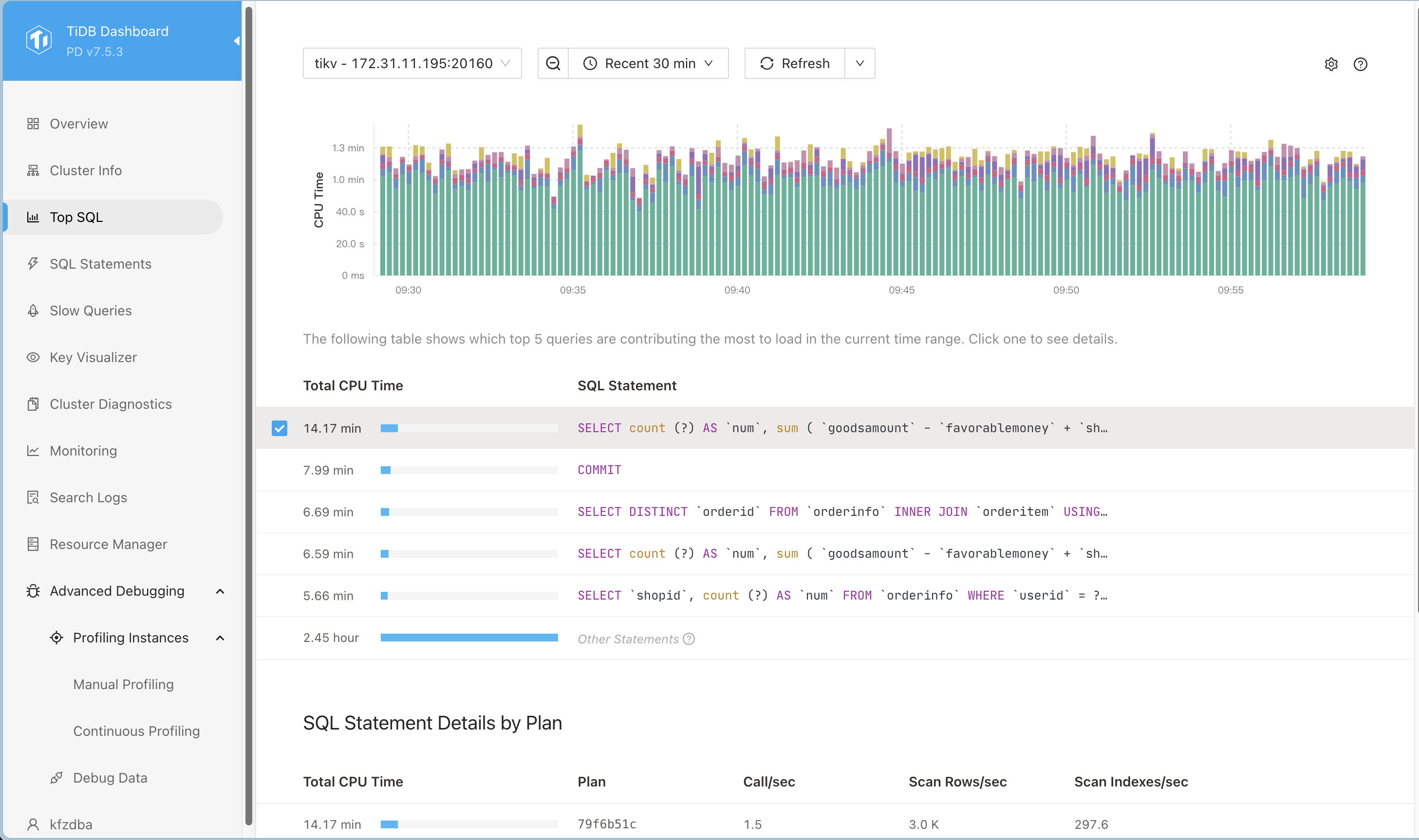
topsql的截图发一个看看。还有就是注意ddl owner的问题。
一般负载不均衡,如果是sql引起的,topsql能看到在运行那些sql。如果不是sql引起的,大概率就是ddl owner在运行统计信息收集之类的任务造成的。
有猫万事足
15
感觉和这个sql是有关系的,cpu时间高出1倍多,这就是两个节点在具体负载上的差异。同样写入commit看上去的差异就比这个sql的差距小。
另外扫描的行数和扫描的索引数差距也大,这个sql大概率没有利用好索引。
https://docs.pingcap.com/zh/tidb/stable/grafana-tikv-dashboard/#coprocessor-detail
看看coprocessor这块的监控,cpu是不是有显著的差异。
如果确定是coprocessor这块有差异,那大概率就是这个sql的问题。
重点优化一下,特别是看看执行计划里面对索引的利用是不是不太好。
总体上,你这个sql,我感觉在tiflash上运行更好。
这几个sql看起来都正常,other的cpu使用率太高了,缩小时间范围看看other里面是什么
lllzd
(时光旅行者)
17
sql看起来都正常,把检查方向放到存储IO上那?看看是不是存储延迟过大,造成CPU过高。