上面的问题解决了吗?
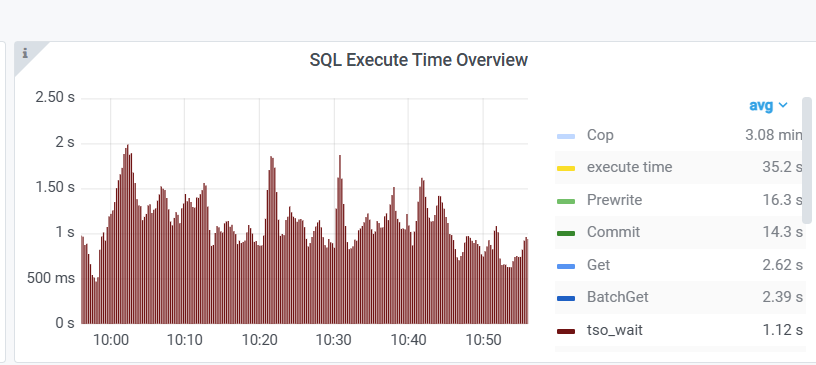
首要问题还是先把tso wait降下来,这个降不下来,瓶颈根本都没到后面。压力没传导过去。当然一直很低。
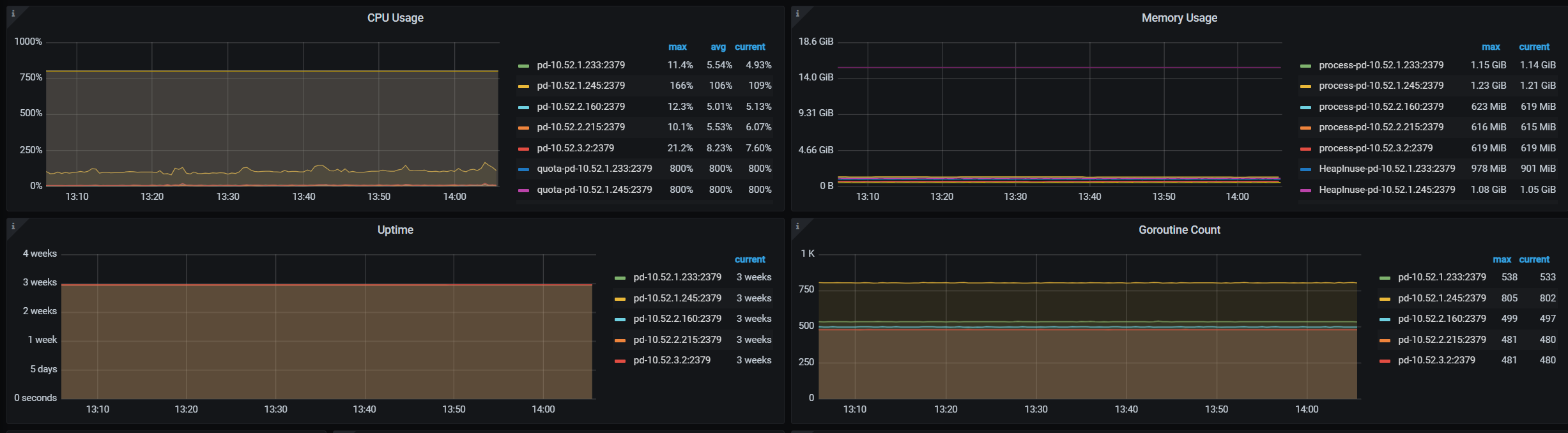
其他的监控不要看了,没有价值,就盯着tso wait优化。
上面的问题解决了吗?
首要问题还是先把tso wait降下来,这个降不下来,瓶颈根本都没到后面。压力没传导过去。当然一直很低。
其他的监控不要看了,没有价值,就盯着tso wait优化。
那问题大了去了,这根本没法用。tso wait 1.12s,到pd的ping值估计都有100ms了。
猫哥 这边有啥建议解决码 我看很多集群都有这个tso上秒的情况
如果你很多集群都是这样。我只能说,从一开始部署的时候就有大问题。
把子网规划好,让同一个集群在同一个子网,ping值最好不要上1ms。想办法用缩容扩容,动态调整一下。
好的收到 我这边动态搞一下
收到 我这边按照您的建议搞一下
这个和到pd ping值是线性关系。只要到pd ping值大了就好不了。
除非是pd的cpu性能不够用了。
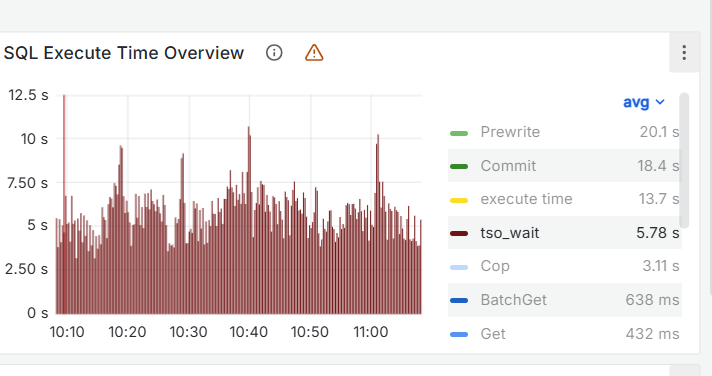
这个速度挺好的,tso wait现在是多少?
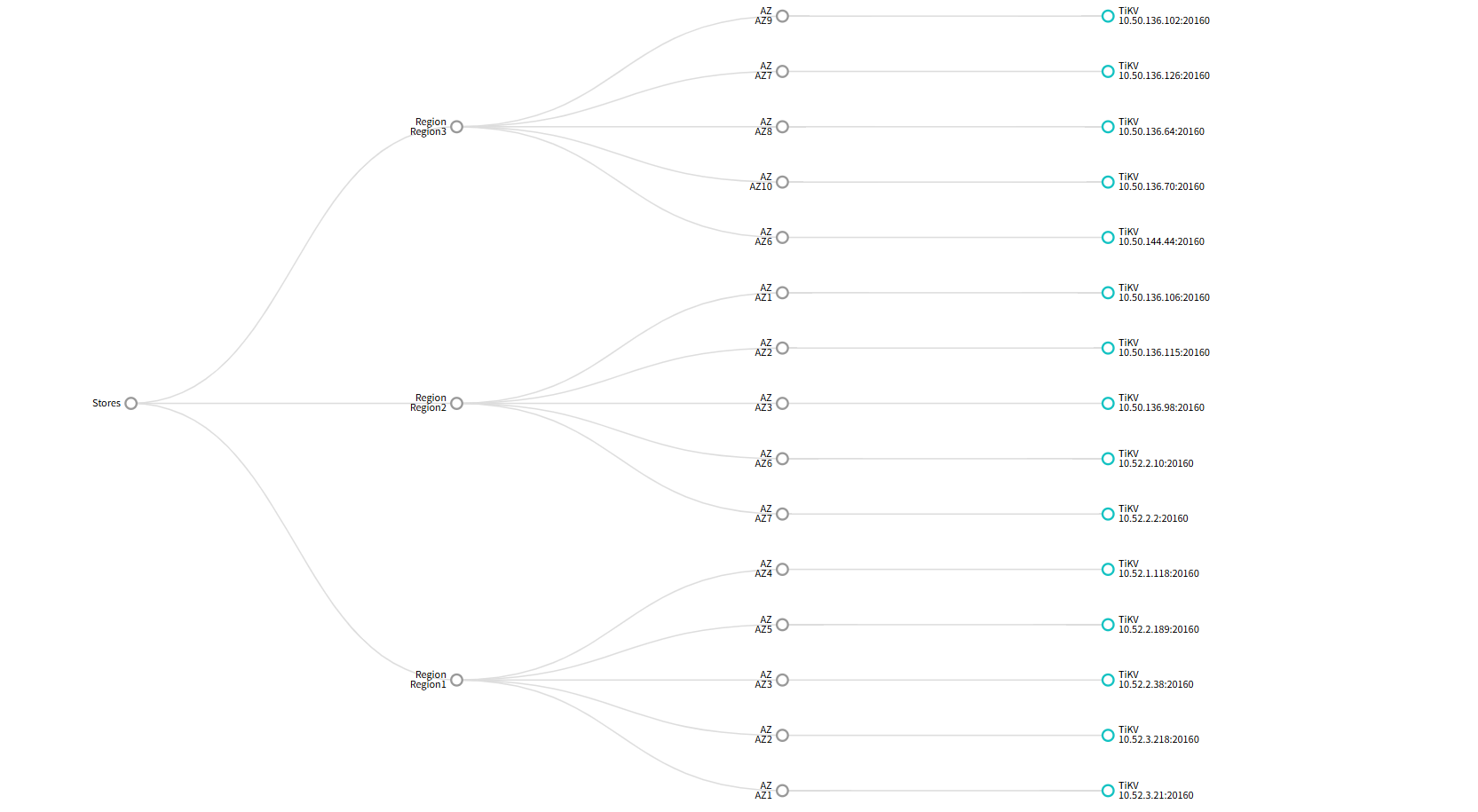
你上面在ping 10.52.2.10这个地址,但是我看下面的图,没有看到这个pd?
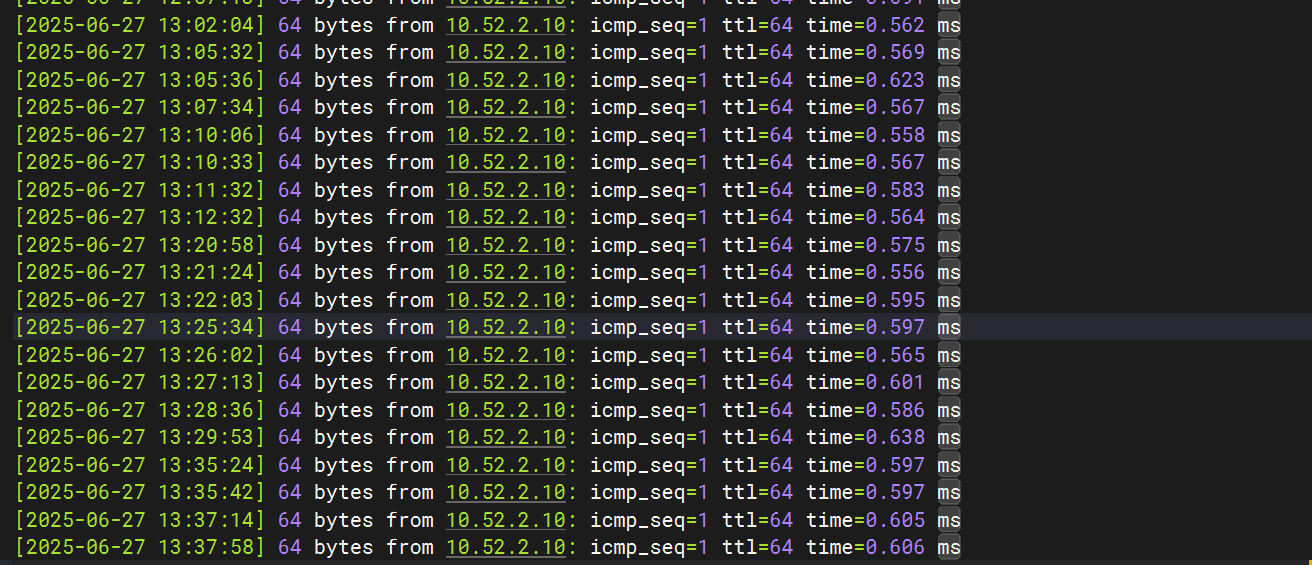
还是几百毫秒 我是pd–ping–tikv—tidb 组件
10.52.2.10,这个地址是pd嘛?你下面的图里面没有它。
需要所有的节点到pd的ping值都小于1毫秒。其他节点到pd的ping值大,这个的节点的tso wait就大。
噢噢 这个是tikv地址
这没用的啊,兄弟。你想啊,这个节点取tso快,其他节点取tso慢,总体还是慢的。
即使有快有慢,要让region leader 和pd leader在一个网段,ping值小于1ms,整体才会快。
简单点,所有节点ping pd小于1ms。这个tso wait就降到2-30ms左右了。
好的 我这边全部测试下节点 ![]()
你要自己验证这个ping值和tso wait是否相关,你可以选几个合适的ping值低的节点,直接部署一套新的。比在老的上面折腾快多了。
老的你现在已经弄得是这个样子,要调整过来,还挺花时间的。
是的 我这边已经准备铲掉 用同子网 网络条件好的机器
我当初是在腾讯云上部署,有一个pd节点跨子网了。然后只要另一个子网的pd成为leader,整个系统全是慢查询。
好在只有这个pd在另一个子网,最后调整了一下优先级,让这个pd只有在其他pd节点全挂的情况下才能成为leader就解决了。