【TiDB 使用环境】生产环境 /测试/ Poc
【TiDB 版本】
【操作系统】
【部署方式】云上部署(腾讯云云)
【集群数据量】 6.7TB
【集群节点数】5 server + 11 tikv
【问题复现路径】
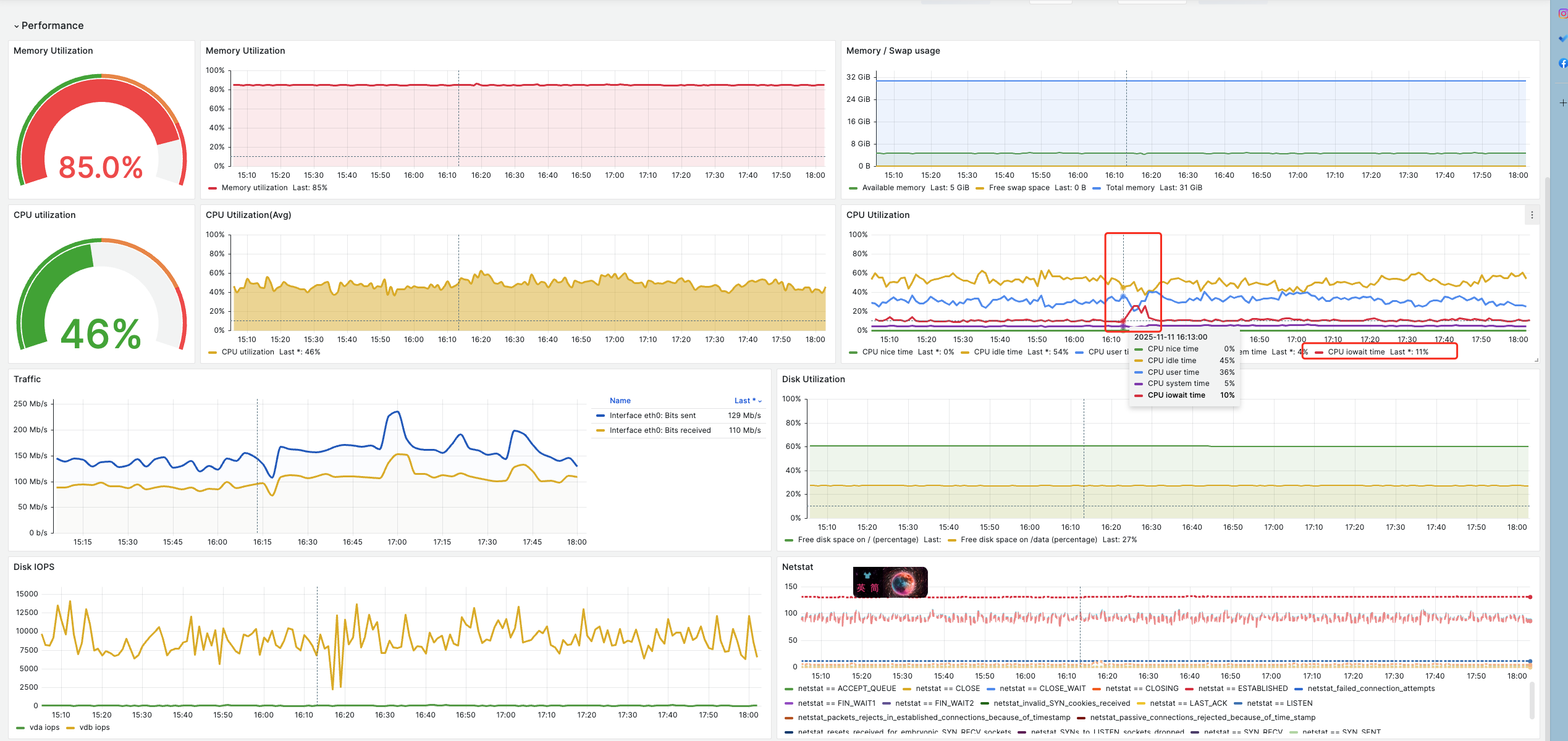
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
kv request 时间突然变得很慢
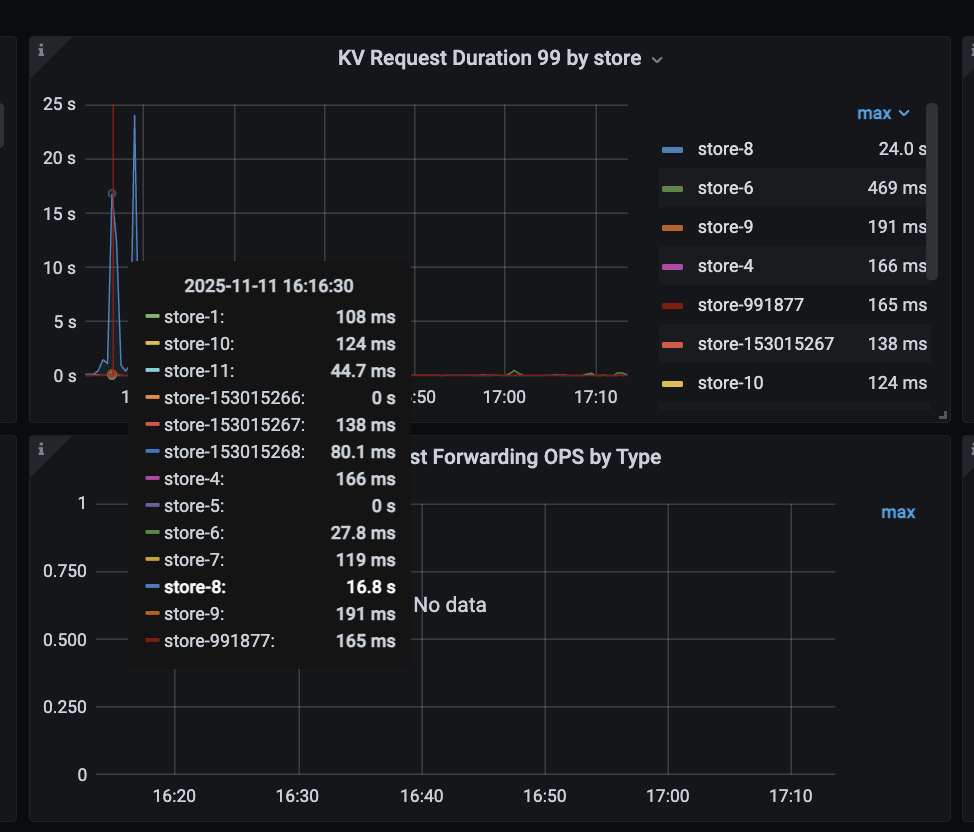
看到store8 的Leader突然下降很多
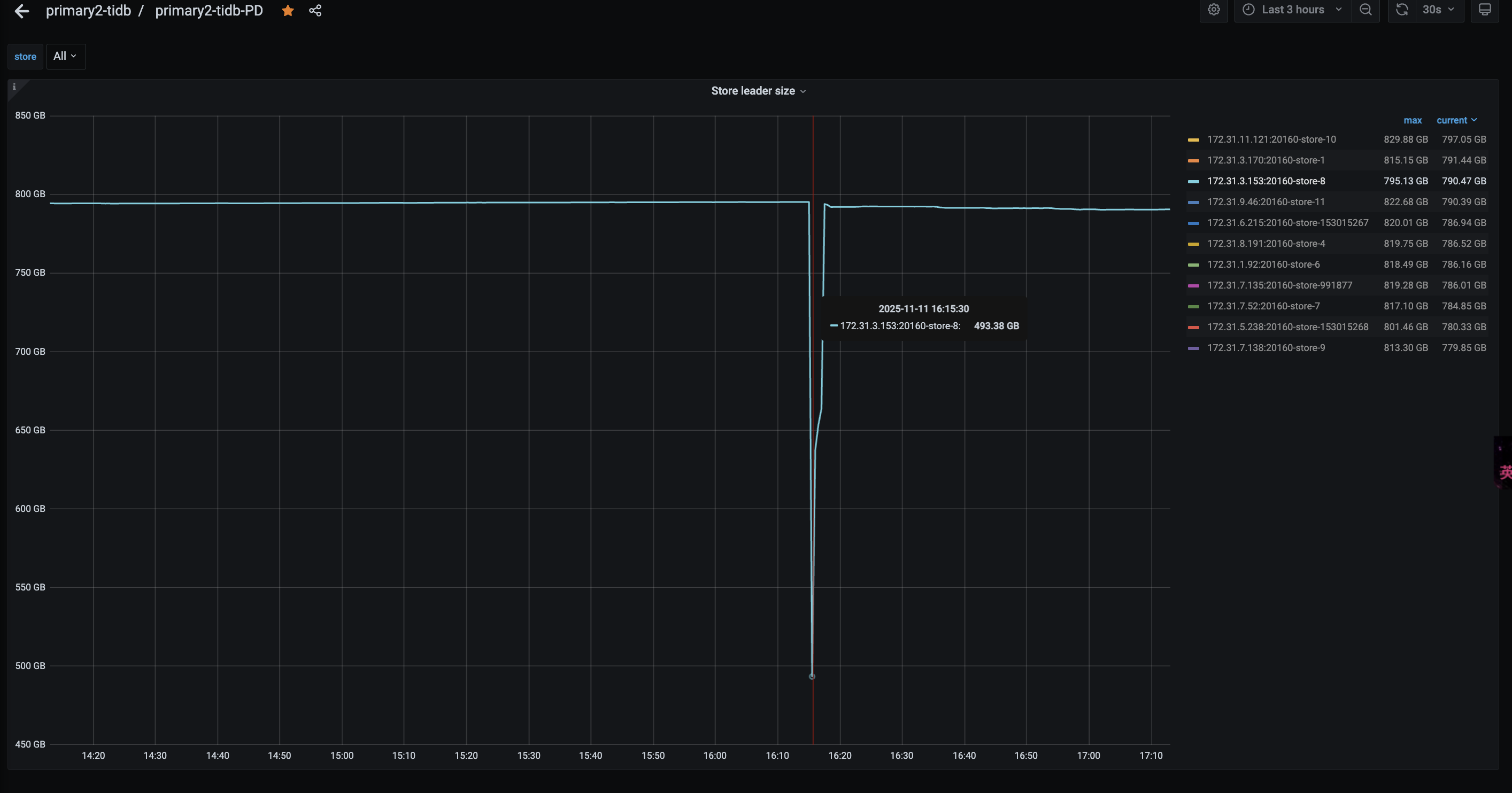
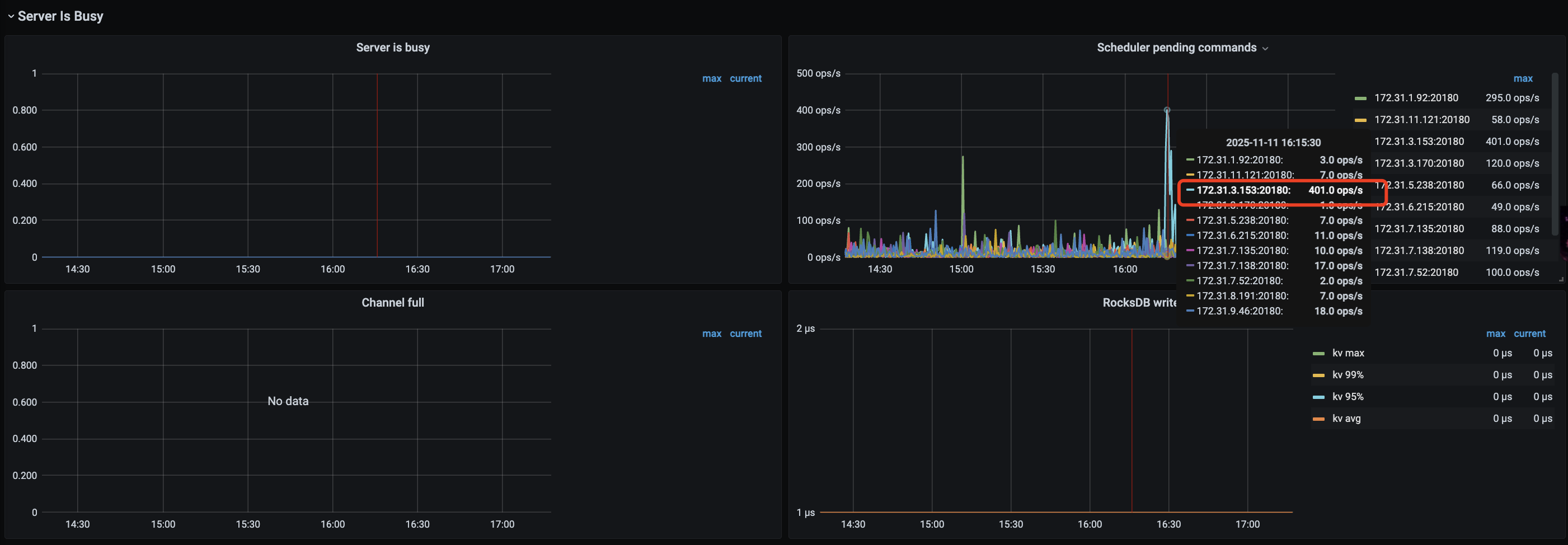
然后检查日志,在pd的日志中看到
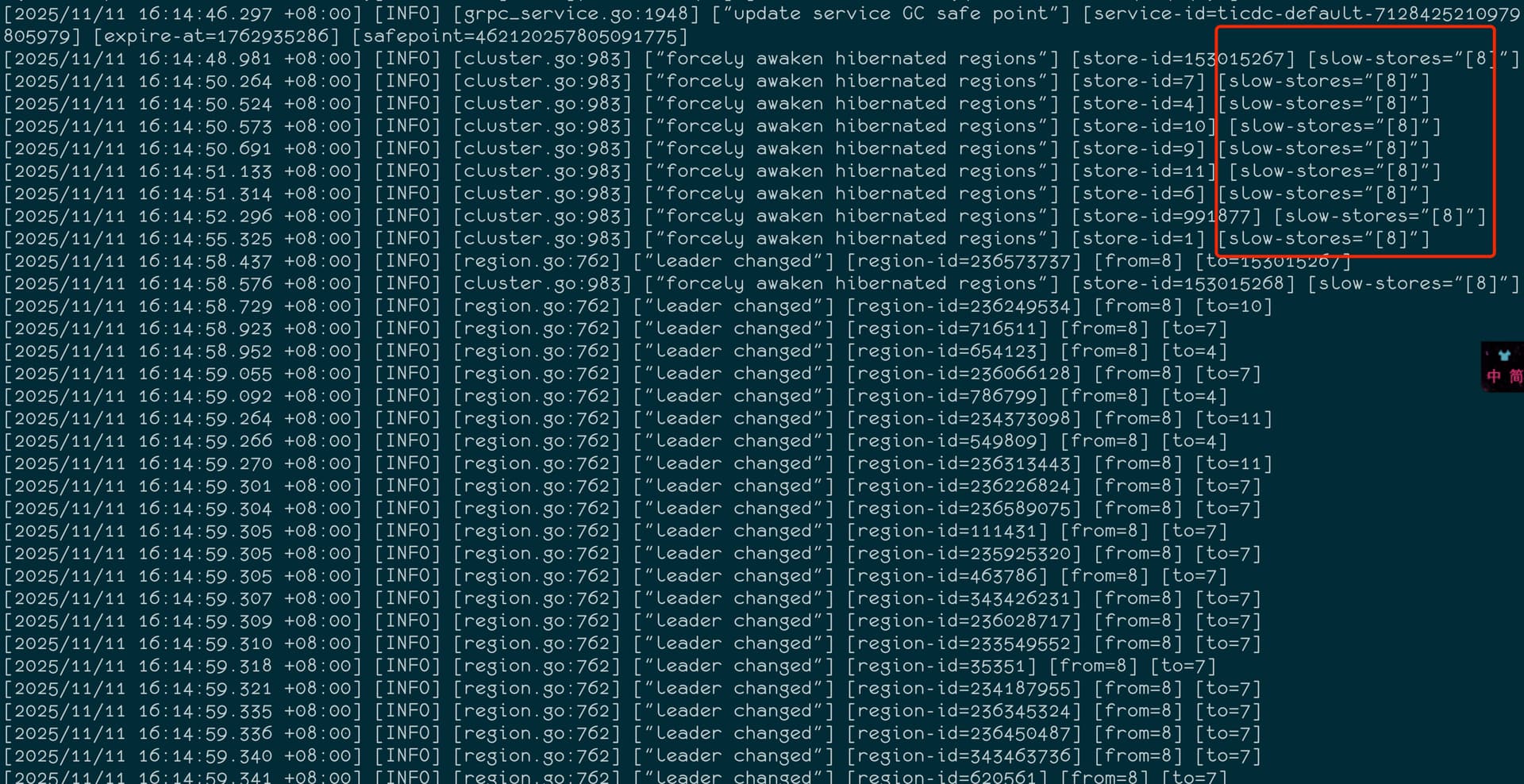
[2025/11/11 16:14:48.981 +08:00] [INFO] [cluster.go:983] ["forcely awaken hibernated regions"] [store-id=153015267] [slow-stores="[8]"]
[2025/11/11 16:14:50.264 +08:00] [INFO] [cluster.go:983] ["forcely awaken hibernated regions"] [store-id=7] [slow-stores="[8]"]
[2025/11/11 16:14:50.524 +08:00] [INFO] [cluster.go:983] ["forcely awaken hibernated regions"] [store-id=4] [slow-stores="[8]"]
[2025/11/11 16:14:50.573 +08:00] [INFO] [cluster.go:983] ["forcely awaken hibernated regions"] [store-id=10] [slow-stores="[8]"]
[2025/11/11 16:14:50.691 +08:00] [INFO] [cluster.go:983] ["forcely awaken hibernated regions"] [store-id=9] [slow-stores="[8]"]
[2025/11/11 16:14:51.133 +08:00] [INFO] [cluster.go:983] ["forcely awaken hibernated regions"] [store-id=11] [slow-stores="[8]"]
[2025/11/11 16:14:51.314 +08:00] [INFO] [cluster.go:983] ["forcely awaken hibernated regions"] [store-id=6] [slow-stores="[8]"]
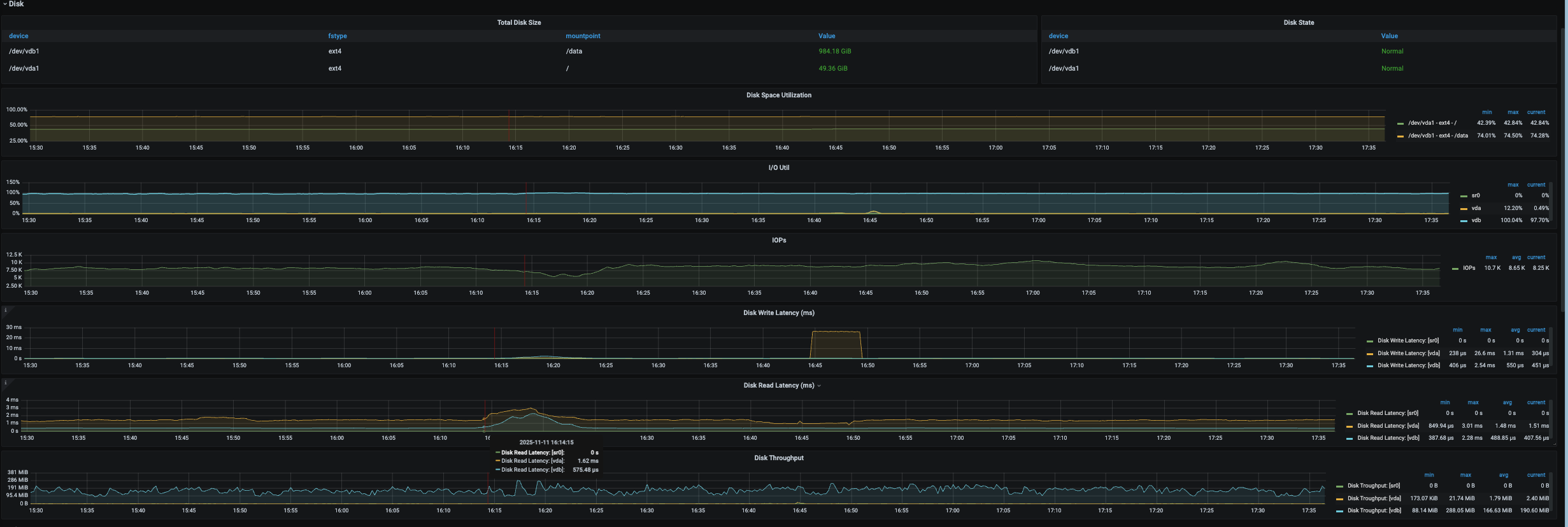
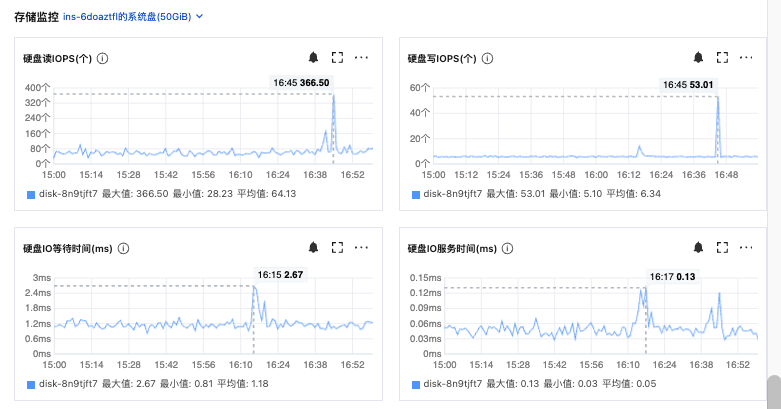
是因为store变成了 slow-store,然后把 该store的Leader给迁移到其他节点了。
那这里的store变成slow-store的根源是什么导致的,怎么排查呢?