这个倒是没有,测试的时候发现这个问题,跟厂商交流的时候提出也没得到解答,以为设计上就是如此。
找时间验证一下这个设置的表现,多谢

确实节点太多了。
1 个赞
开源版什么时候支持?
存储和自定义函数

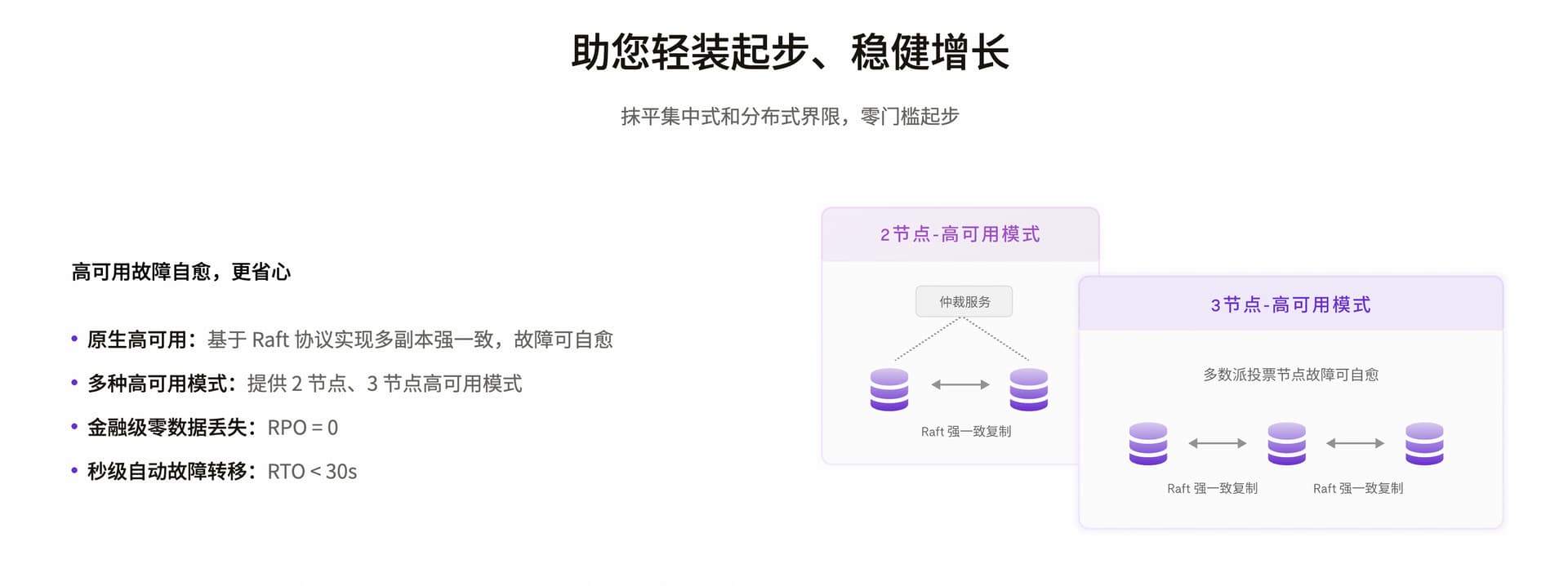
- 核心改进:采用 “多区域部署” 架构,贴合跨部门 / 跨区域数据同步需求
- 部署方案:核心区域(主集群)+ 备份区域(从集群),核心区域按 “PD 3 节点 + TiDB 4 节点 + TiKV 6 节点(3 副本)” 部署,备份区域同步 TiKV 数据,支持故障自动切换
- 价值:满足系统 99.95% 可用性要求,单区域故障时 3 秒内切换,数据零丢失
1 个赞
硬件要求确实有点太高了
我最希望能充分挖掘性能。
用的 cpu 是 mysql 的几倍,性能就要是 mysql 的几倍。
create table as select * 功能
read an write, to file
最优执行计划生成的准确性提升。
读写能力的提升
Hash Join 深度优化
GC 与存储性能提升
最近才遇到的,OR 和 IN 太容易走表扫描,这个影响太大了
tidb 如果减少表扫描? - TiDB 的问答社区
统计信息收集速度能快点
1 个赞
不但慢,我发现生个 tidb 节点都需要单独的 analyze (通过 show stats_histograms 验证)
这种信息希望是能共用的
![]() 这个应该不是吧,执行一次应该整个集群都变了才对啊。
这个应该不是吧,执行一次应该整个集群都变了才对啊。
1、减少资源需求
2、类似MySQL binlog或者Oracle日志挖掘的功能