统计信息不准,更容易规避和排查
分区可以减少
添加组合索引
谢谢分享
很是详细呀
说得很详细
在 TiDB 中减少表扫描(避免全表扫描 / Full Table Scan)的核心思路是 让查询能高效命中索引 ,同时优化数据分布、查询写法和集群配置。
是的,遇到一个就容易拖慢整个系统。
in不能太多。tidb不推荐or。大概是这样
说白了,感觉还是优化器还有优化的空间
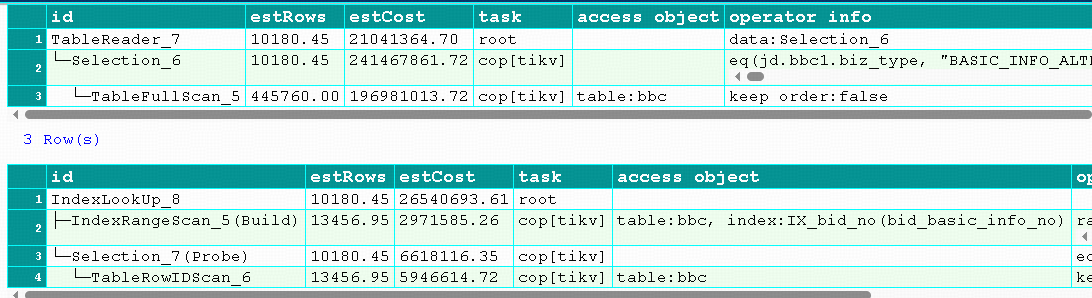
再来一个使用 IN 的图,这个明显看出,虽然索引的成本也比较高,但表扫描的成本是近2亿,索引的成本是按600万,从成本来说,不走索引感觉很奇怪(IN的值接近400,偏多)
(当然,可能会有人说索引不是全覆盖的,但现实业务,如果索引都做到全覆盖,那索引势必会非常多,那样就容易导致数据变更的性能问题了)
explain format='verbose'
SELECT * FROM bbc1 bbc USE index(IX_bid_no)
WHERE bbc.biz_type='BASIC_INFO_ALTER'
AND bbc.bid_basic_info_no in('BBI202209
1 个赞
OR是因为默认设置可能导致 INDEX-MERGE 方案被抛弃,IN 应该主要还是依赖成本评估吧?这明显没有按成本评估来做,所以IN不走索引的原因又是什么? 是不是有什么设置?
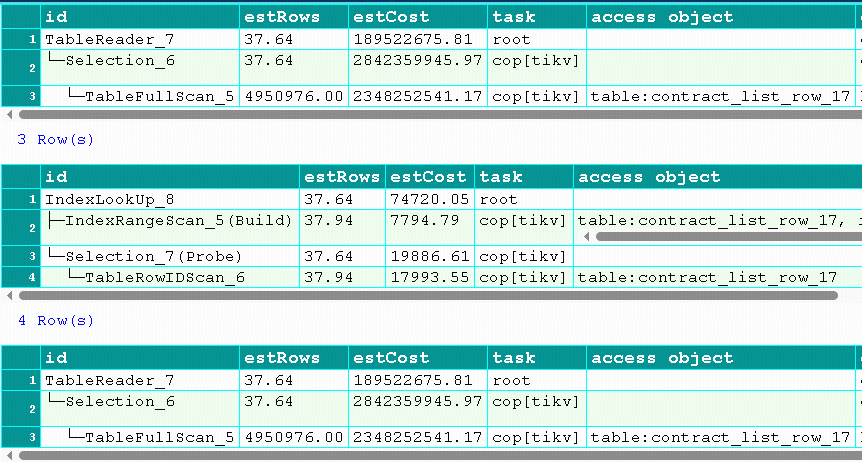
还有一个打死都想不通的情景:如下查询,难道只能是全覆盖的索引?成本评估成摆设了?
EXPLAIN format='verbose'
SELECT * FROM contract_list_row_17 ignore index(idx_contract_sys_no_delete_flag)
WHERE
delete_flag = 0
AND contract_sys_no IN ('18648504362549137')
;
EXPLAIN format='verbose'
SELECT * FROM contract_list_row_17 use index(idx_contract_sys_no)
WHERE
delete_flag = 0
AND contract_sys_no IN ('18648504362549137')
;
EXPLAIN format='verbose'
SELECT * FROM contract_list_row_17 ignore index(idx_contract_sys_no_delete_flag)
WHERE
delete_flag = 0
AND contract_sys_no ='18648504362549137'
;
先确定统计信息是不是正确的,执行计划里面的估计行和实际行对比看看差异大不大?如果不大,就不是统计信息问题,比较棘手。要么改写语句,要么使用hits,但用hits也有风险的,理论上优化器选择的是最优的。
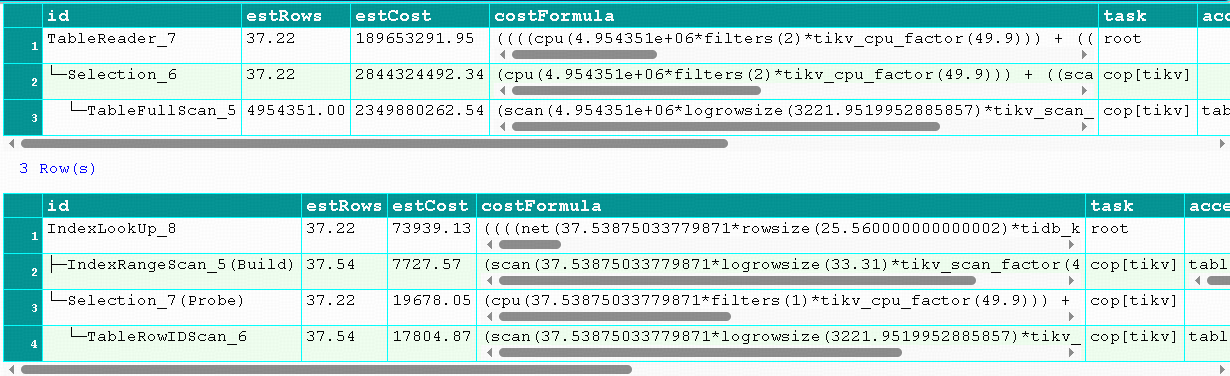
跟 analyze table没有关系,analyze只会导致没有走预期正确的执行计划,我上面给的图,是一次执行得到的结果,也就是基于某个统计信息,那么结果就应该以当时统计信息估计的成本来选择,从给出的执行计划中的成本看,明显表明选择的方案是有问题的
然后,我做了 analyze table,健康度显示为100,我再次执行,得到执行计划仍然是选择了全表扫描
EXPLAIN format='cost_trace'
SELECT * FROM contract_list_row_17 ignore index(idx_contract_sys_no_delete_flag)
WHERE
delete_flag = 0
AND contract_sys_no IN ('18648504362549137')
;
EXPLAIN format='cost_trace'
SELECT * FROM contract_list_row_17 use index(idx_contract_sys_no)
WHERE
delete_flag = 0
AND contract_sys_no IN ('18648504362549137')
;
除查询改写外,控制 TiDB 百万级数据量表扫描的核心手段可总结为两类:
- 优化索引与执行计划:为
OR条件涉及字段建联合索引、为IN查询字段建单列索引,开启tidb_enable_adaptive_index_selection让优化器优先选索引,限制IN值数量(拆分 500 + 为多个小批量IN或JOIN临时表); - 调整参数与资源控制:设置
tidb_max_execution_time防止长时扫描,通过tidb_force_index强制指定索引,关闭tidb_opt_agg_push_down等可能导致全表扫描的优化开关,同时用资源管控限制扫描类查询的 CPU/IO 占用。
estRows和实际的执行返回的row相差大吗?一般执行计划不准确会导致估计行和实际返回行相差较远,统计信息的采样比是多少?
实际返回行数为0,与预估返回记录数差别很小。统计信息方面,前面已经给了再次图,一次是 analyze table之前,健康度90%,后一次是做了analyze table之后
1 个赞
为OR 条件涉及字段建联合索引、为IN 查询字段建单列索引
- 联合索引不可能保证覆盖所有条件字段,这个肯定不现实
- 为IN字段建立单列索引。IN单值的这个示例已经很清楚了,有单列索引,结果走了表扫描,要求联合索引才走索引(我在查询中特意用了IGNORE INDEX,就是因为环境中已经创建了联合索引来解决这个问题)
- IN 限制在500内这个可以做为规则,但具体是500,还是多少,没个定论,我前面的查询示例,IN 近400,和 IN 一个值都走表扫描
tidb_max_execution_time、强制索引
- 这些都是针对明确已知的,已经属于问题发生后的止损的手段了
资源管控
- 有效果,但属于一种有损的手段。比如查询走表索引,无并发时执行时长是2左右,并发导致存储满负载,通过资源管控确实能够把资源负载降低下来,但是资源负载不高的情况有,有并发仍然发现查询时长明显变长,出现阻塞,并导致某些长时间得不到资源的查询中断
1 个赞