老鹰506
(Ti D Ber Uhzt Tfx J)
1
【TiDB 使用环境】生产环境
【TiDB 版本】7.5.3
【部署方式】云上部署
【操作系统/CPU 架构/芯片详情】
【机器部署详情】CPU大小/内存大小/磁盘大小
【集群数据量】
【集群节点数】
【问题复现路径】
【遇到的问题:问题现象及影响】
【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
目前的现象是业务出现报警,追踪提示连接数据库超时。
1、然后根据采集到的慢查趋势来看,那个时间节点慢查变多
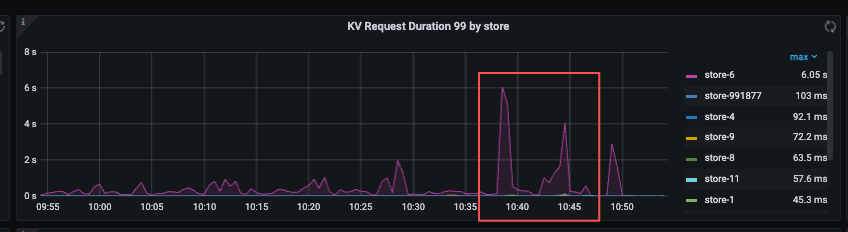
2、对应分析TIDB metric看到某个store节点的 ”kv request duration“ 异常
3、看到也有一些 batchrollback
最终通过重启这个store节点恢复了。
但是什么根源导致这个节点异常的? tidb 慢查对应的 server节点,如何能定位到时哪些SQL影响到了该tikv store节点呢?
求各位大佬解答
老鹰506
(Ti D Ber Uhzt Tfx J)
4
谢谢提供思路,目前根据slowlog表看到了问题节点慢查远远大于其他节点
但是从grafana的 TiKV-Summary 中的QPS中也没有看到这个节点的请求远大于其他节点呢
老鹰506
(Ti D Ber Uhzt Tfx J)
5
嗯,目前在挨个确认这个节点的各个指标和其他的差异性, 目前看到CPU和内存使用基本一致,看到iops 比其他节点都高一些
Royce1220
(Ti D Ber Kwxb3 N7 I)
7
感觉这个应该是结果,是sql分布不均才导致io负载高一点吧
老鹰506
(Ti D Ber Uhzt Tfx J)
8
有这个怀疑,但是需要数据佐证,看到底是请求分布不均还是磁盘本身有问题
TiDB_TTRRT
(Ti D Ber Tm Ntpua L)
9
把时间范围拉长一些,如果只是今天的iops高,我觉得是结果,先通过慢查询定位相关SQL,dashboard的慢SQL那也标记着处理SQL最慢的tikv节点,另外,慢查询的相关表,查一下region的leader分布是否均匀,是不是读的时候,region的leader都在慢的tikv上面。
独善其身
(Ti D Ber Bi Rqfz5 K)
10
慢sql是不是在执行过程中出现region热点数据了
老鹰506
(Ti D Ber Uhzt Tfx J)
11
是最近一直有点高,
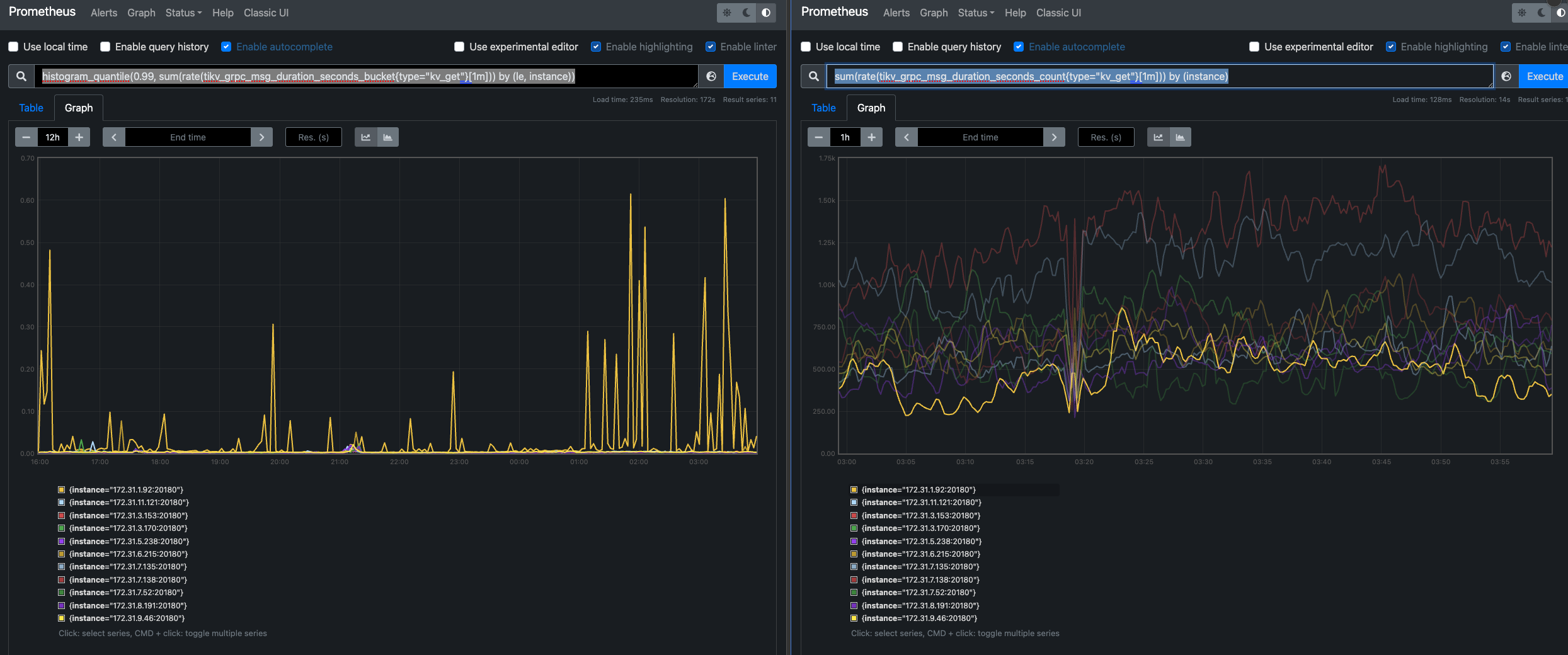
1、从grpc监控看到,同一个操作类型比如之类 kv_get 延时没有其他的高,但是 请求qps 确实比其他的高。
左边是 每个 TiKV 节点处理 kv_get 请求的 P99 延迟
左边是 每个 TiKV 节点每秒处理的 kv_get 请求数量(QPS)
从这个角度看到 QPS 还没有其他节点高,但是P99延迟明显高
2、从store容量使用 Leader分布来看是基本均衡等
3、也看了TiKV-Trouble-Shooting 中 hot-read/hot-write 监控没有看到明显的差异
从这些信息,结合iops高,是不是就说明是这个节点的磁盘有问题了呢
老鹰506
(Ti D Ber Uhzt Tfx J)
12
没有看到明显的热点异常, TiKV-Trouble-Shooting 中hot-read/hot-write 没有明显差异
托马斯滑板鞋
(托马斯滑板鞋)
13
dashboard里能抓到那个时间段的慢sql吗?执行计划里有说明慢在那,可以抓出来看看
TiDB_TTRRT
(Ti D Ber Tm Ntpua L)
14
show table table_name regions,查看相关表的leader store id,看看这些leader是否都在一个store上面
老鹰506
(Ti D Ber Uhzt Tfx J)
16
从哪里判断热点store不少? 是热点store,还是热点region?
老鹰506
(Ti D Ber Uhzt Tfx J)
17
现在不确定具体的表呢?只是知道这个store节点iops异常, 你这个建议的出发点是什么呢
老鹰506
(Ti D Ber Uhzt Tfx J)
18
目前定位是磁盘io问题,把这个节点下线了。然后整个集群目前是稳定的了
system
(system)
关闭
19
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。