一个好的问题描述有利于社区小伙伴更快帮你定位到问题,高效解决你的问题
【TiDB 使用环境】生产环境
【TiDB 版本】8.1.1
【部署方式】华为云
【操作系统/CPU 架构/芯片详情】
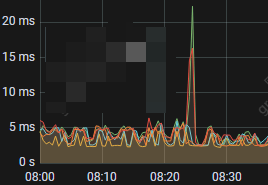
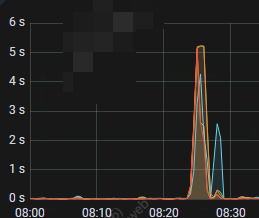
华为云部署了一套tidb集群,最近经常有tikv store 被标记为slow store,看了一下raft io 面板,确实是有异常的,append log 和 commit log 的延迟确实是高,特别是commit log duration的延迟很高,
99% Append log duration per server
99% Commit log duration per server
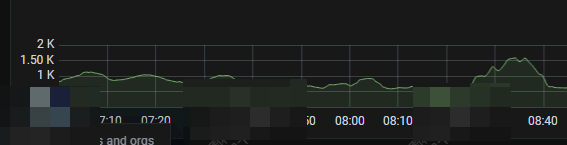
1.但是去查了node_exporter的磁盘性能监控图,磁盘io不是很高
iops确实升高明显
但是磁盘读写延迟不高,tikv store的读写延迟不超过5ms
disk 读写延迟 node_exporter
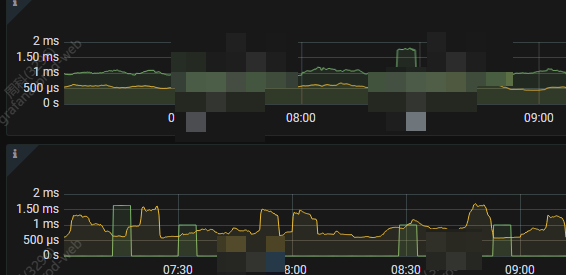
2.commit log为什么和append的 延迟差了这么多,按照原理来说,应该就是磁盘和网络的问题了,但是通过blackbo 来看,网络延迟也不高啊
大家有什么排查思路嘛
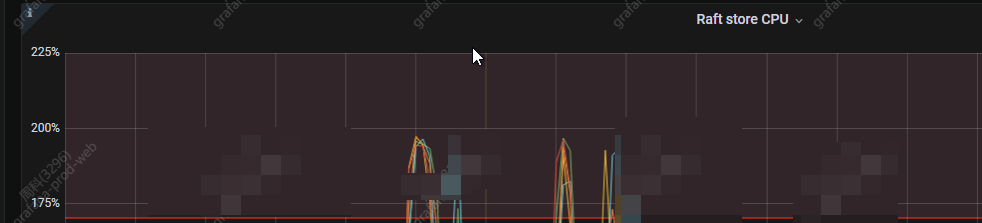
还有一点,raft store cpu 超过了 80% * raftstore.store-pool-size (默认设置为2)
所以有没有可能是raftstore 线程池cpu 不够,导致拖慢了tikv的commit log
菩提老祖
(菩提老祖)
4
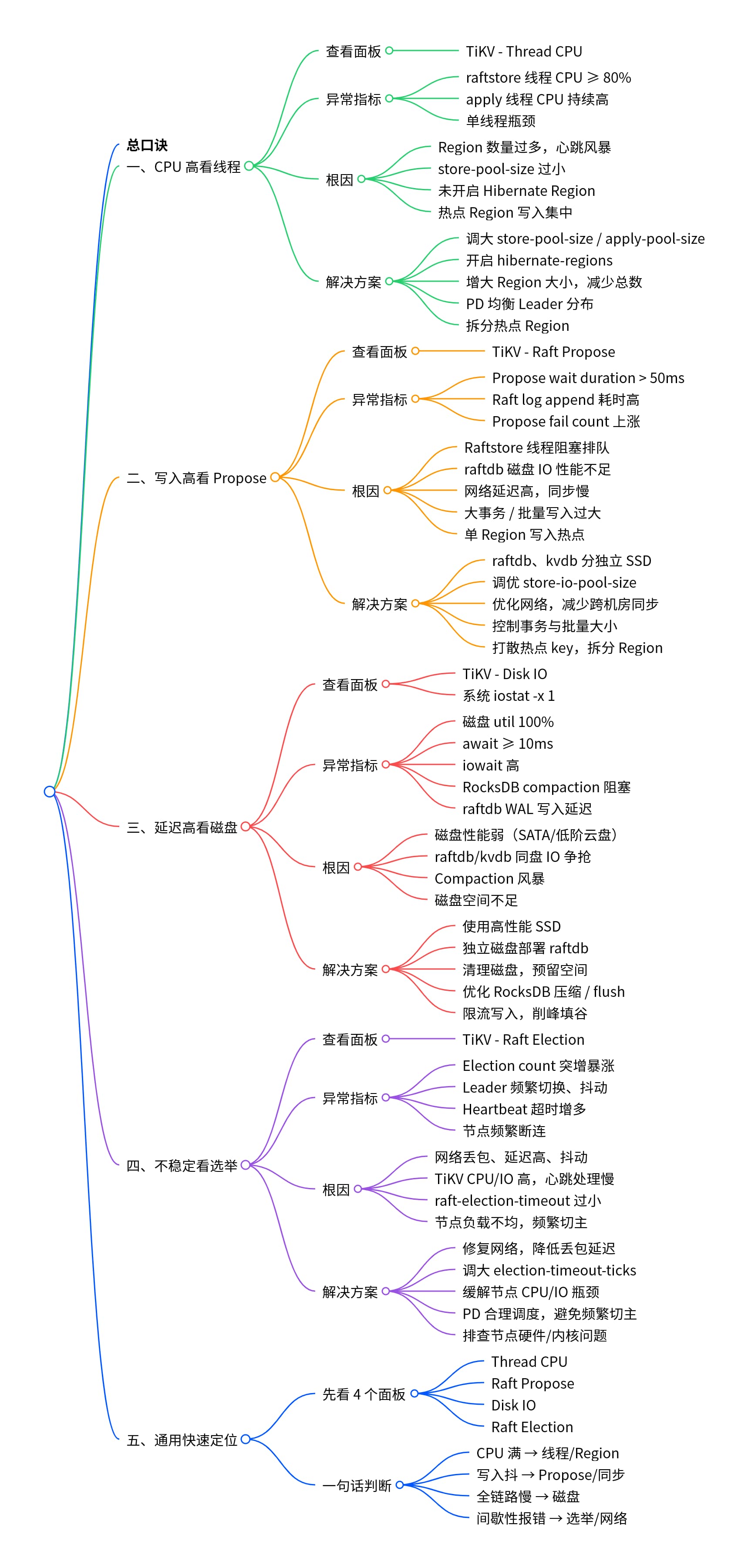
从提供的信息分析:
raftstore.store-pool-size=2 意味着只有 2 个线程处理所有 raftstore 工作,总 CPU 上限就是 200%。当超过 160%(80% × 2)时,raftstore 线程池饱和,导致:
1、append log 延迟高 — raftstore 线程忙于处理 raft 消息和写 raft log,来不及调度
2、commit log 延迟高 — log 写入磁盘后需要通知 apply 线程提交,但 raftstore 线程积压
3、slow store — 其他 store 检测到你这个 store 响应慢,标记为 slow
并发处理能力差,如果云主机配置高,没必要限制的这么低。
在slow store时间点,看下线程池是否打满,区分写入延迟还是提交延迟。是否有大事务导致raftstore线程处理单条消息时间过长。
1 个赞
Royce1220
(Ti D Ber Kwxb3 N7 I)
5
感觉可能是RaftStore 线程繁忙或网络同步延迟?
在slow store时间点,看下线程池是否打满,
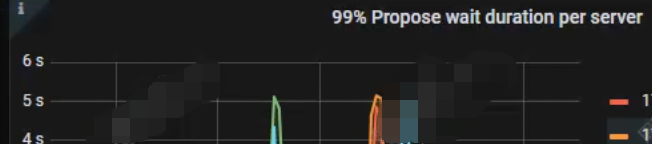
raft store cpu 几乎都打满了,看了下在slow store的时间点 Raft Propose 下的 Propose wait duration 发现也是很高(和commit log 的延迟重合) 几乎是可以确定了还是raft store cpu的瓶颈,
您说的区分写入延迟还是提交延迟。是否有大事务导致raftstore线程处理单条消息时间过长 ,这是什么意思呢
我们这个集群是个大集群,有近90万个region,这种情况下,对raft store估计有不小的压力
菩提老祖
(菩提老祖)
8
就像你提到问题 ,我也认为是cpu问题。raftstore.store-pool-size 默认2 改大些 比如4
线程不够 / Region 太多 / 热点写入
内存和磁盘都很低的话,查查看看是不是内存限制大小了。还有就是append日志并行度是否低了
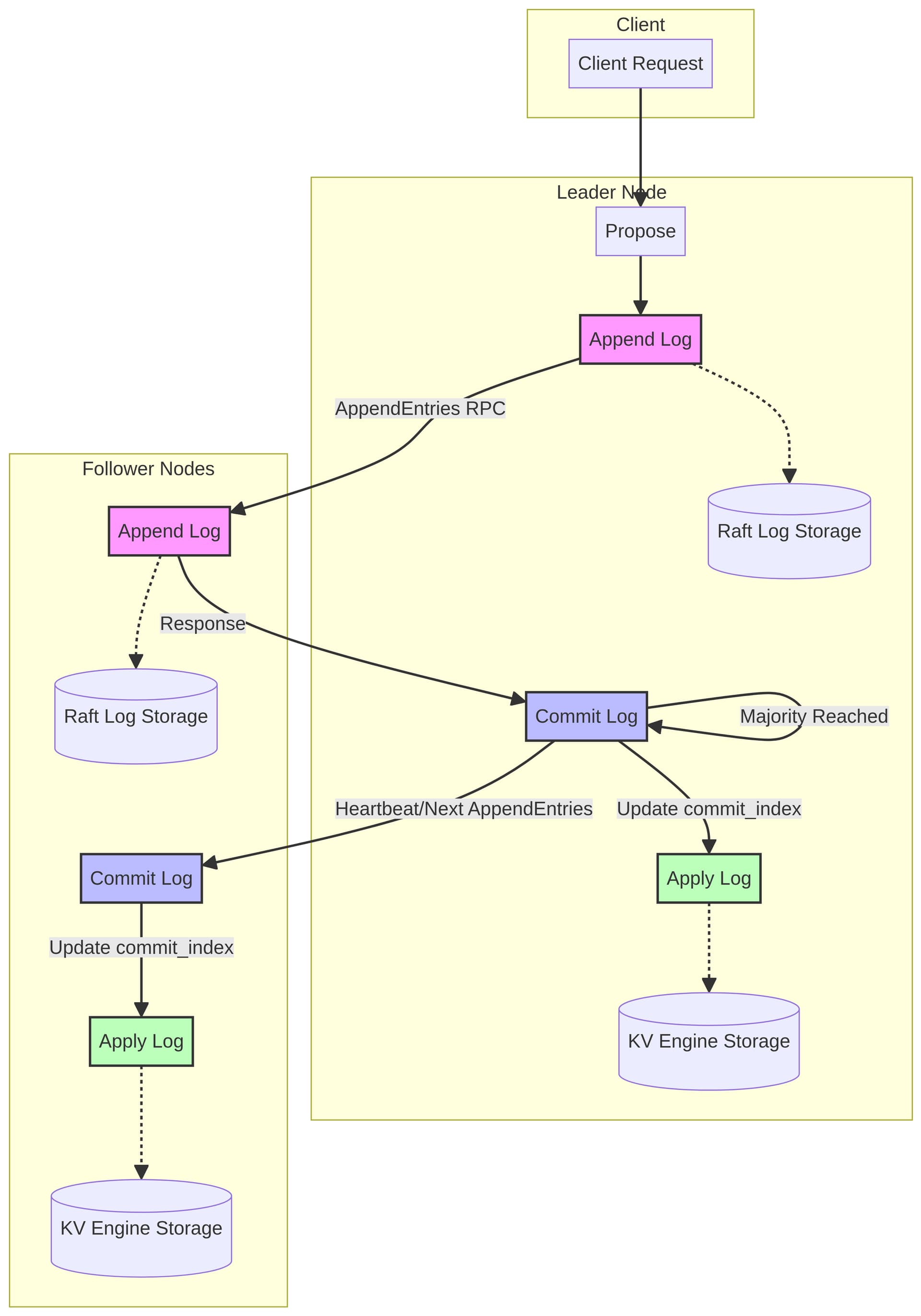
问题描述里,append 虽然慢了点但应该在合理范围内,commit 慢了几个数量级,主要问题矛盾推测在 leader 和 follower 同步数据
manus.im “tikv raft 的 append log, apply log 和 commit log 的区别,画个图说明“
raftstore.store-pool-size 调整到4以后,高峰期 也没有发生过掉leader的现象