

面对海量数据、高并发以及信创改造的迫切需求,证券基金期货行业如何借助原生分布式数据库突破传统架构瓶颈?本文将结合平凯星辰资深技术专家的分享,深入解析 TiDB 的核心原理,并通过三大典型场景的调优实践,展现 TiDB 如何为金融核心系统打造稳定、高效、敏捷的数据底座。
一、TiDB 分布式数据库架构解析
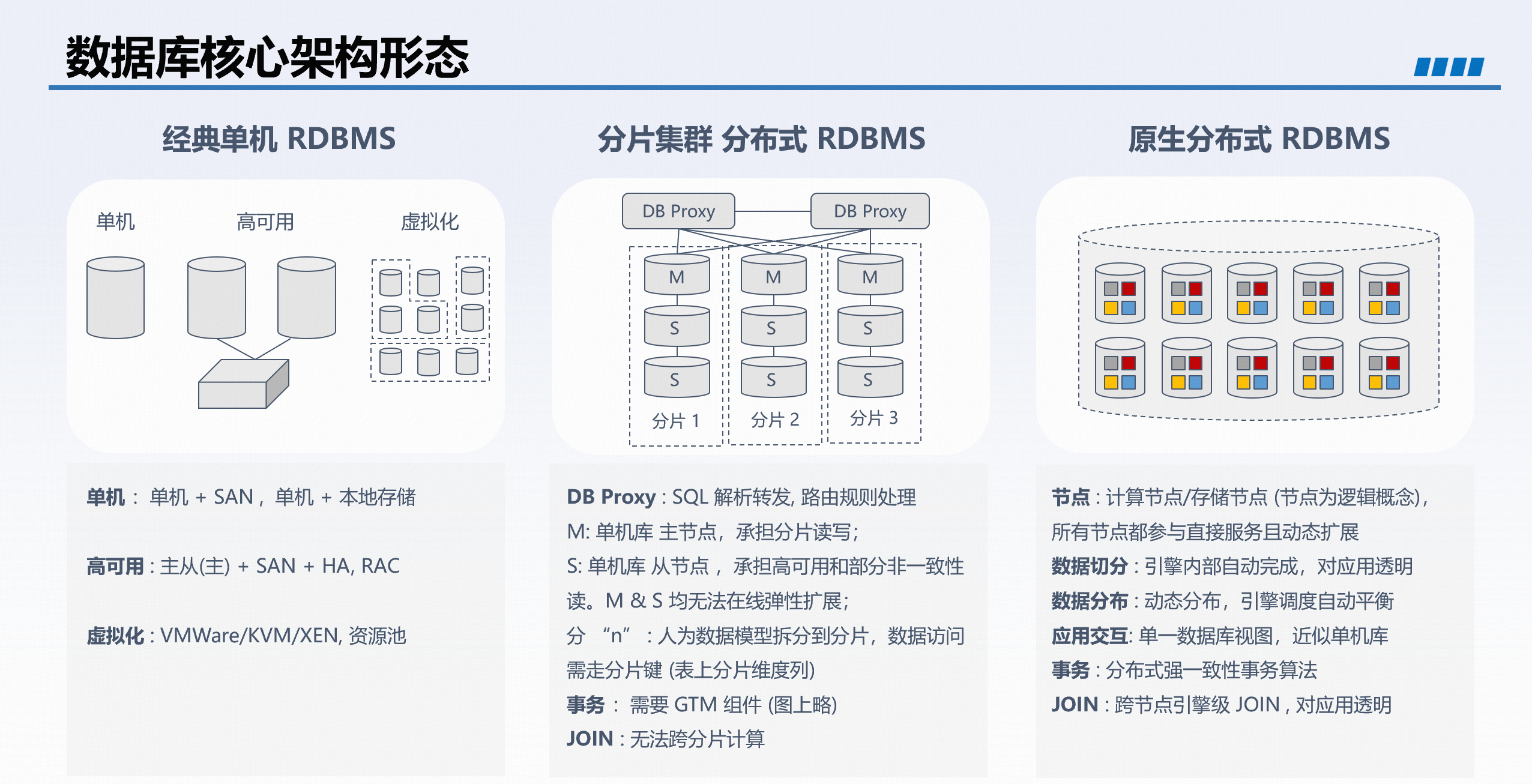
1. 数据库架构的演进
数据库架构的演进主要经历了三个阶段:
- 集中式架构(单机/主从):使用简单,延迟极低,适合一般业务体量的交易场景,但扩展性不足。
- 分库分表架构:为解决扩展性瓶颈而生,但给业务开发带来额外的改造成本,且仅适用于固定分片键的稳态业务。
- 原生分布式架构:以 TiDB 为代表,同时解决了集中式的扩展性问题和分库分表的开发复杂性,实现水平扩展与高可用。
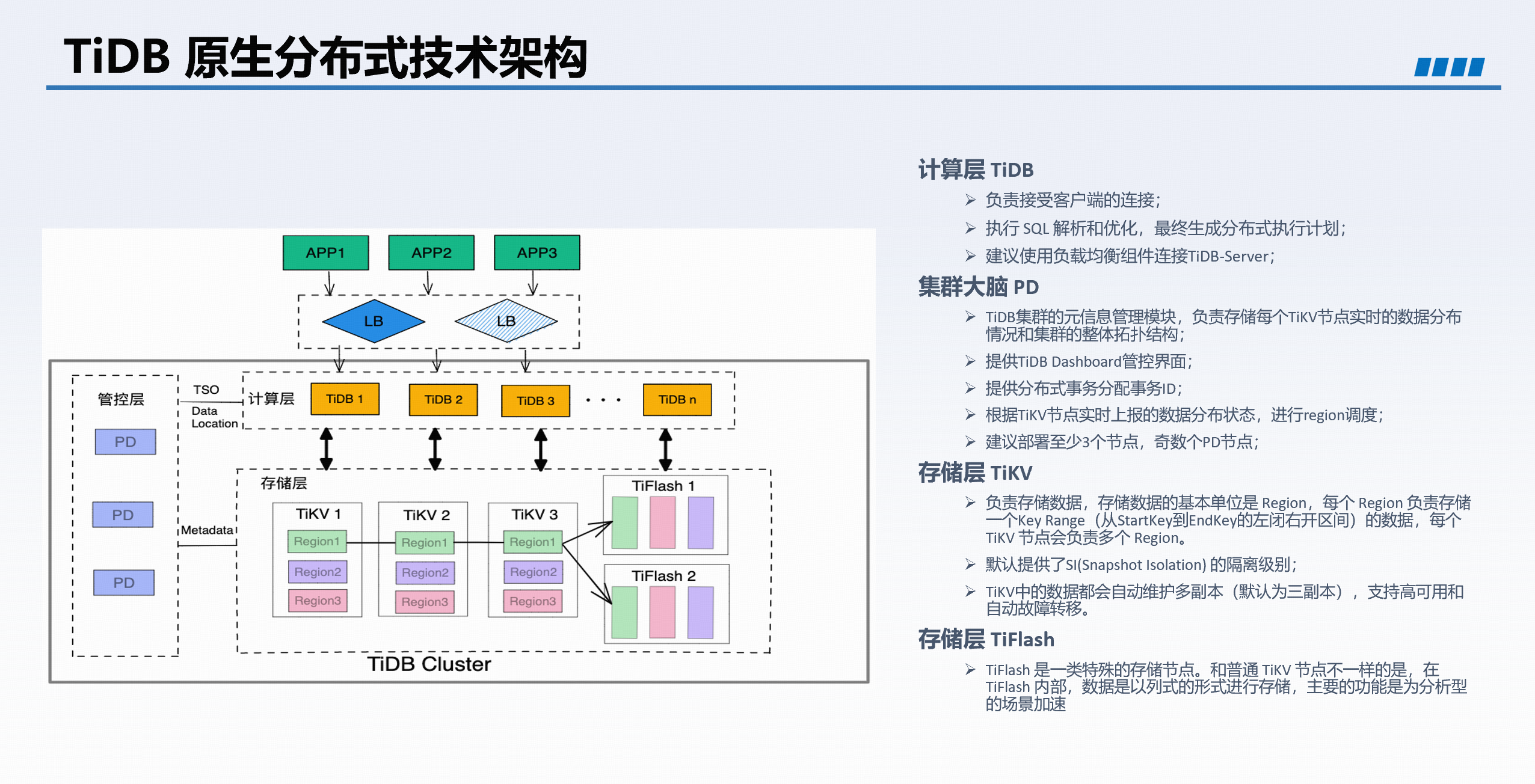
2. TiDB 核心组件概览
TiDB 的整体架构可以用两个关键词概括:存算分离和行列双存储引擎。核心组件包括:
- TiDB Server:无状态的 SQL 引擎,完全兼容 MySQL 协议,支持高可用部署(≥2 实例)。负责 SQL 解析、编译,并将操作转换为对底层存储引擎的 KV 请求。
- TiKV:行存存储引擎,采用多层架构:本地 KV 存储 → Raft 一致性协议 → MVCC 并发控制 → 分布式事务层 → API 层,确保数据强一致和高可靠。
- PD Server:集群的“大脑”,负责收集各分片(Region)和存储节点的状态信息,并生成调度任务,保证数据均衡和负载均衡。
- TiFlash:列存扩展组件,通过异步复制 TiKV 数据,实现行存与列存一致性。可用于 HTAP 场景,智能加速 OLAP 查询。
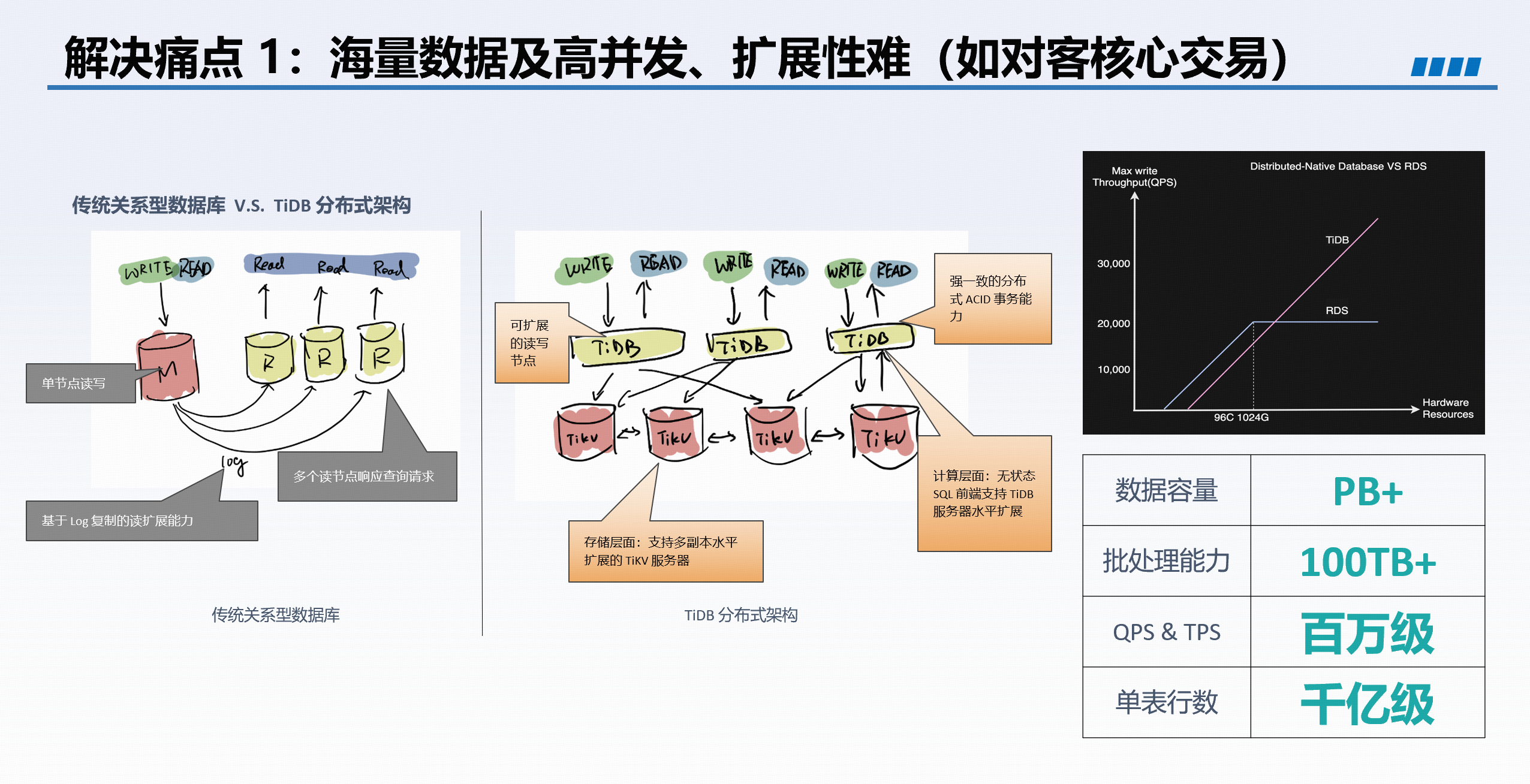
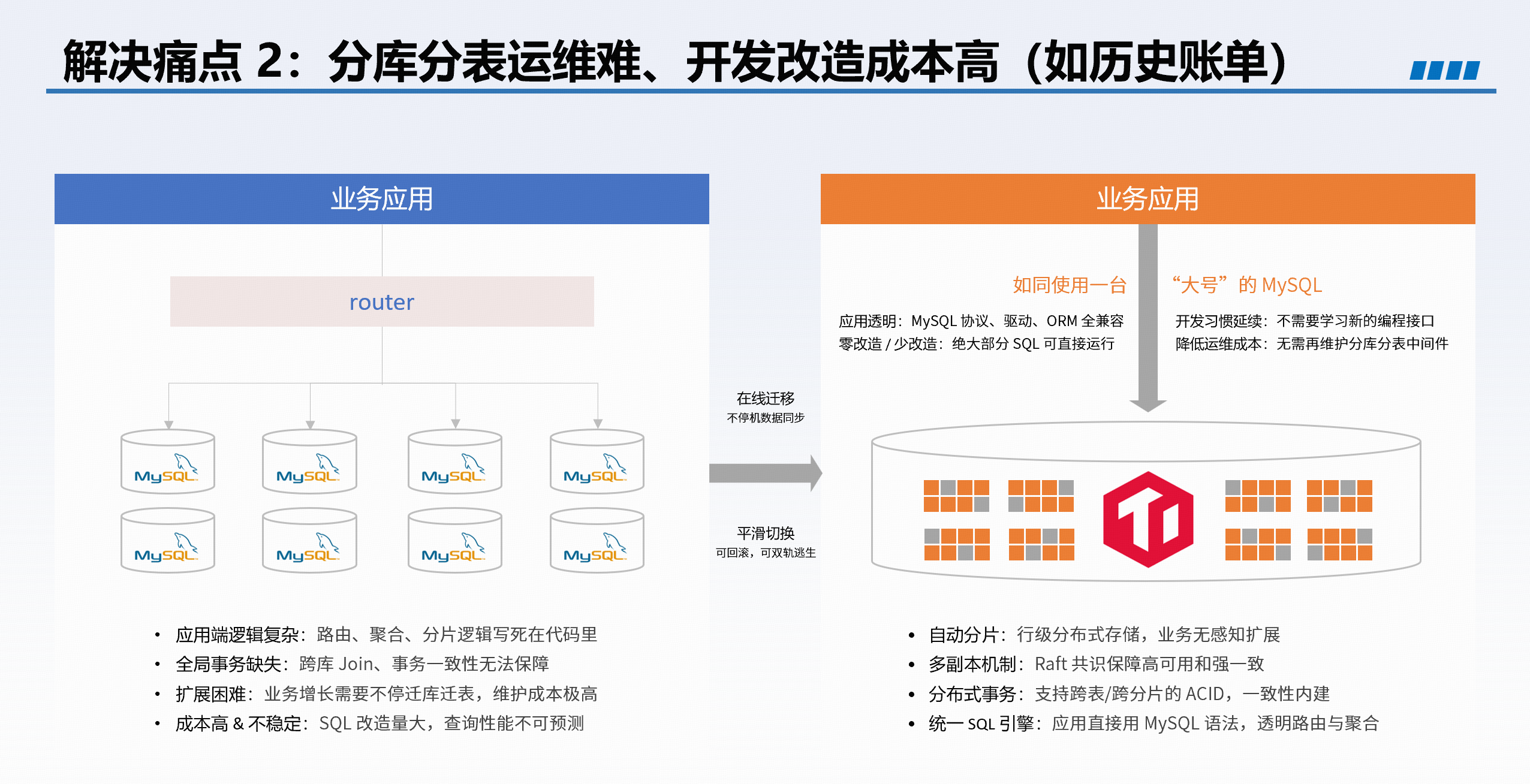
3. TiDB 如何破解金融行业四大痛点
痛点 |
TiDB 解决方案 |
|---|---|
海量数据及高并发下扩展性难 |
多写多读、水平扩展,单集群可支撑 PB 级数据量、百万级 QPS 及百万张表。 |
分库分表架构运维难、开发成本高 |
原生分布式避免跨库关联、动态 DDL 等问题,典型场景如历史账单库替换 MyCAT。 |
技术栈复杂、分析时效性不足 |
HTAP 能力一栈式替代“OLTP + ETL + OLAP”复杂架构,满足实时风控、CRM 等场景。 |
硬件成本高、运维不统一 |
3 倍以上压缩率节约存储成本,通过资源管控与资源池实现多业务共享,降本增效。 |
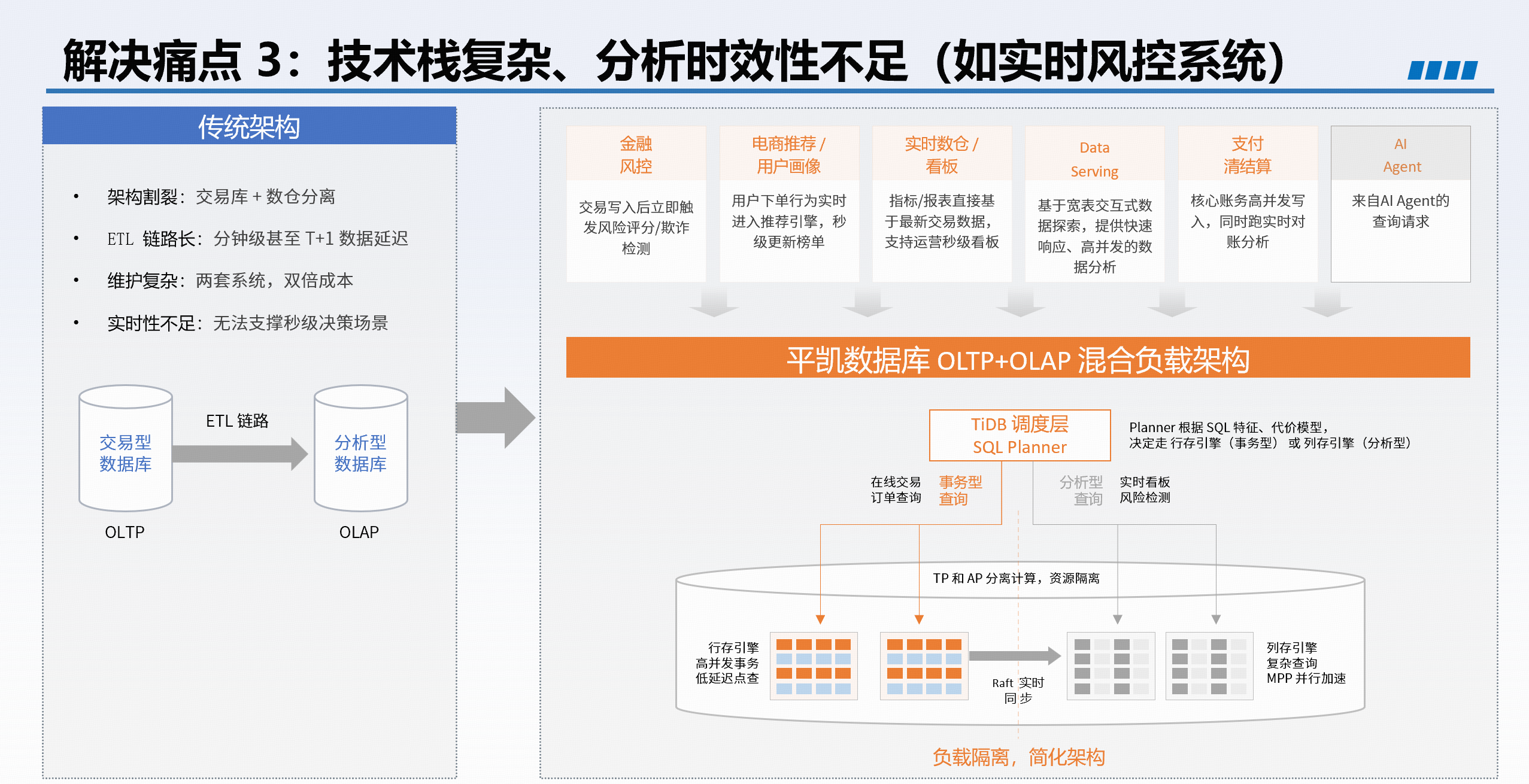
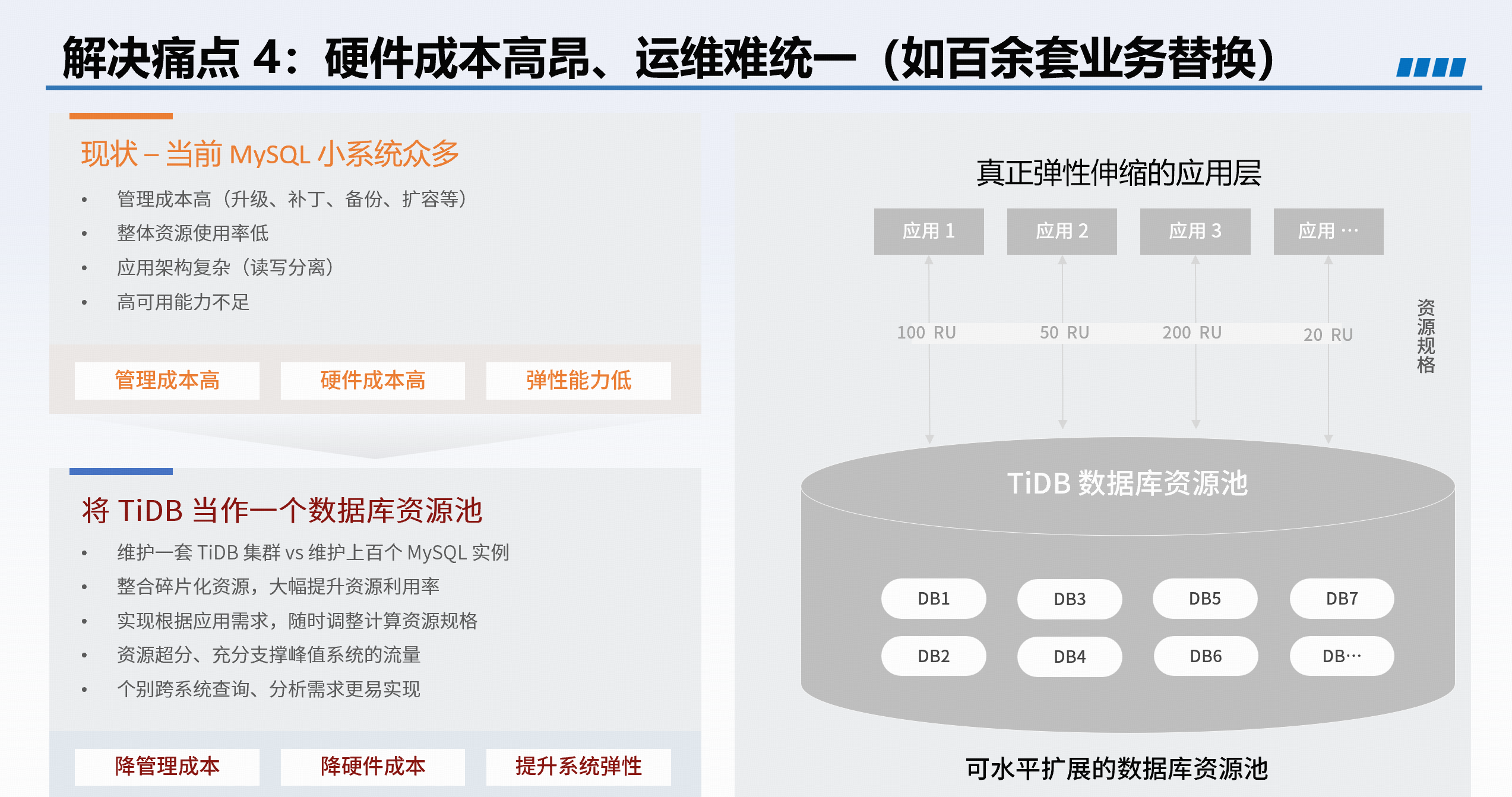
二、证券行业典型调优实践
1. 慢查询优化
监控工具
- Grafana:查看系统整体性能,如资源使用、线程池状态。
- Dashboard:分析具体 SQL 细节,包括执行计划、统计信息。
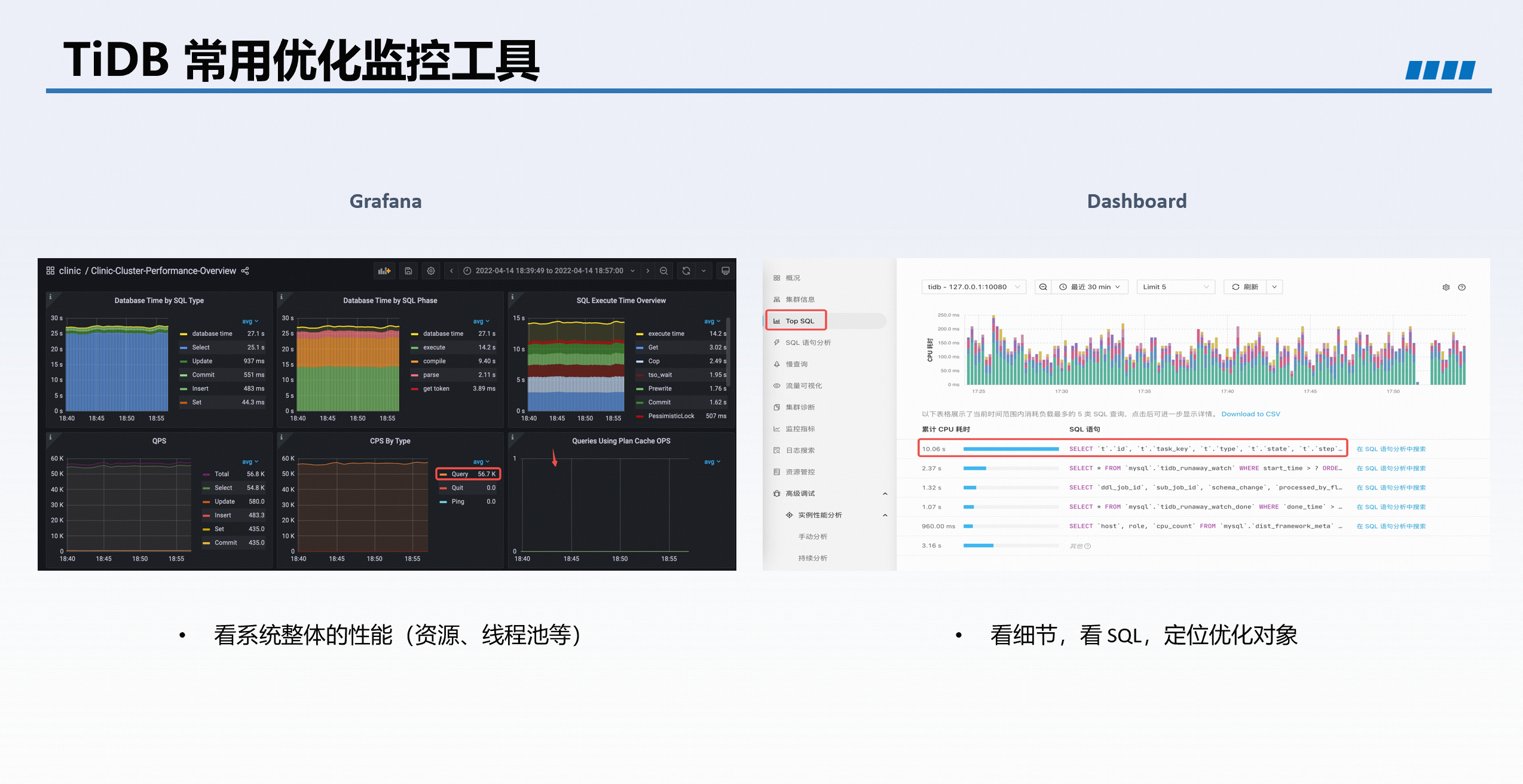
慢查询定位
- 利用慢 SQL 元数据视图,按用户、统计信息准确性、执行计划跳变等维度检索。
- Dashboard 热力图可直观查看集群中不同节点的负载倾斜情况。
优化方法
- Hint 强制修改执行计划:如强制走索引、调整 Join 方式。需注意 Hint 未生效的常见原因(如客户端未加 -c 参数、字段排序规则不一致)。
- SQL Binding:无需修改应用代码,直接在数据库端绑定稳定执行计划,避免执行计划跳变。
- 更新统计信息:当执行计划错误源于统计信息缺失或过期时,通过手动收集或调整统计信息更新策略解决。
- 业务 SQL 优化:如大事务拆分为小批量,从源头降低数据库压力。

典型案例
某客户因统计信息未及时更新,导致 SQL 执行计划走错索引,耗时激增。执行计划中出现 pseudo 关键字,表健康度为 0。重新收集统计信息后,执行计划恢复正常,耗时显著下降。后续通过 SQL Binding 固定执行计划,彻底杜绝类似问题。
2. 热点问题
热点产生原理
TiDB 按主键范围划分数据分片(Region),数据按主键排序存储。若使用自增主键,新写入的数据会集中在同一 Region,即使 Region 自动分裂,短时间内仍集中在单节点,形成写入热点。
热点定位
- Grafana 监控图表:观察各节点 CPU、QPS 是否严重不均。
- Dashboard 热力图:出现明显的亮黄色阶梯状图案,表明存在热点。
解决方案
- 非聚簇表 + 预分区:避免使用自增列作为主键,创建表时指定预分区。
- 使用
AUTO_RANDOM替代AUTO_INCREMENT:打散主键分布。 - 手动 Split Region:在跑批前对表进行打散。
- 降低并发写入:防止单个节点线程池被打满。
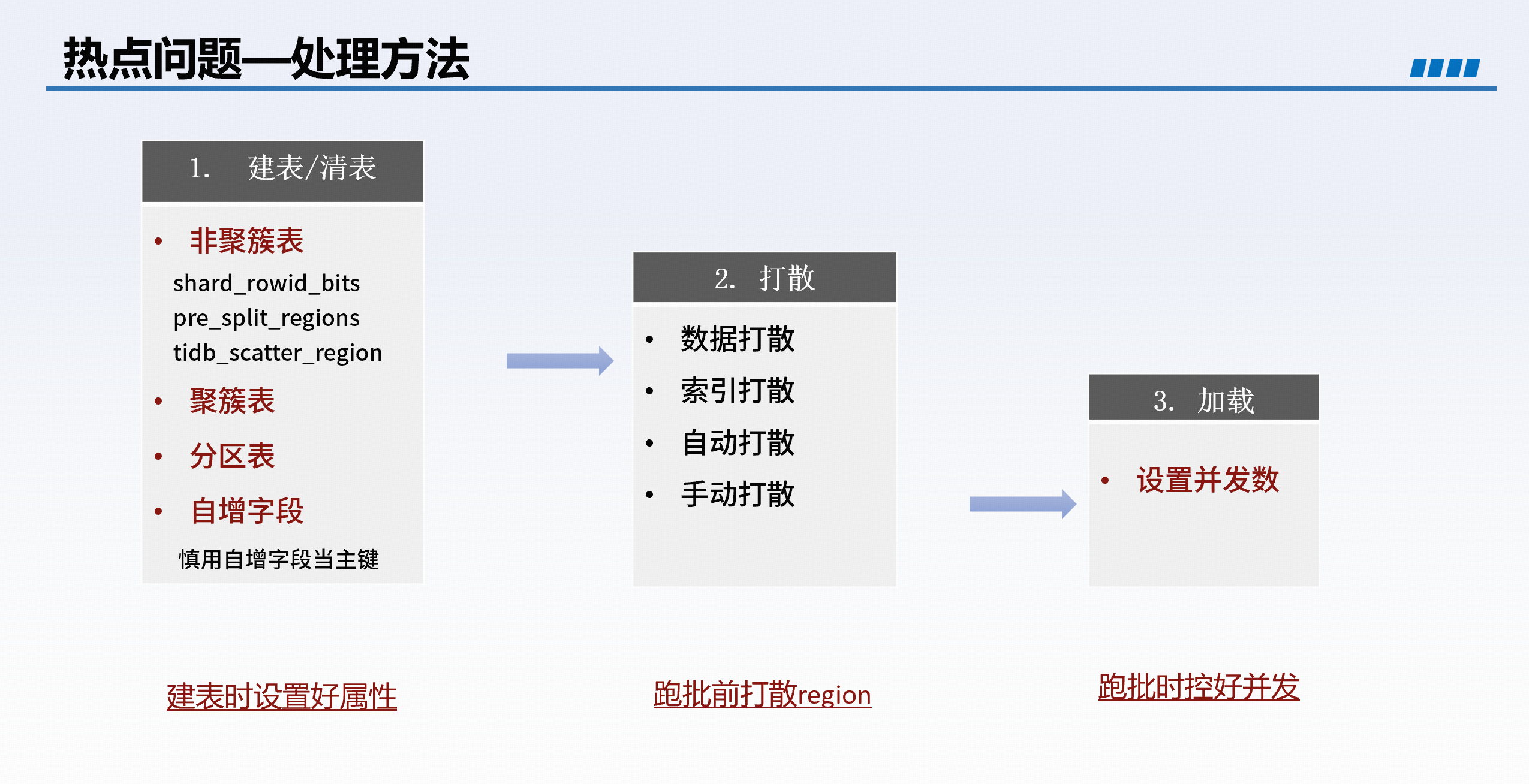
典型案例
某客户每晚通过 DataX 从大数据平台同步数据至 TiDB,随着数据量增长,同步越来越慢。通过 Dashboard 的 TopSQL 定位到消耗 CPU 最高的 Insert 语句,热力图和节点监控均显示单节点负载过高。最终通过将表改为非聚簇表并预打散 Region,解决了热点问题,同步性能恢复。
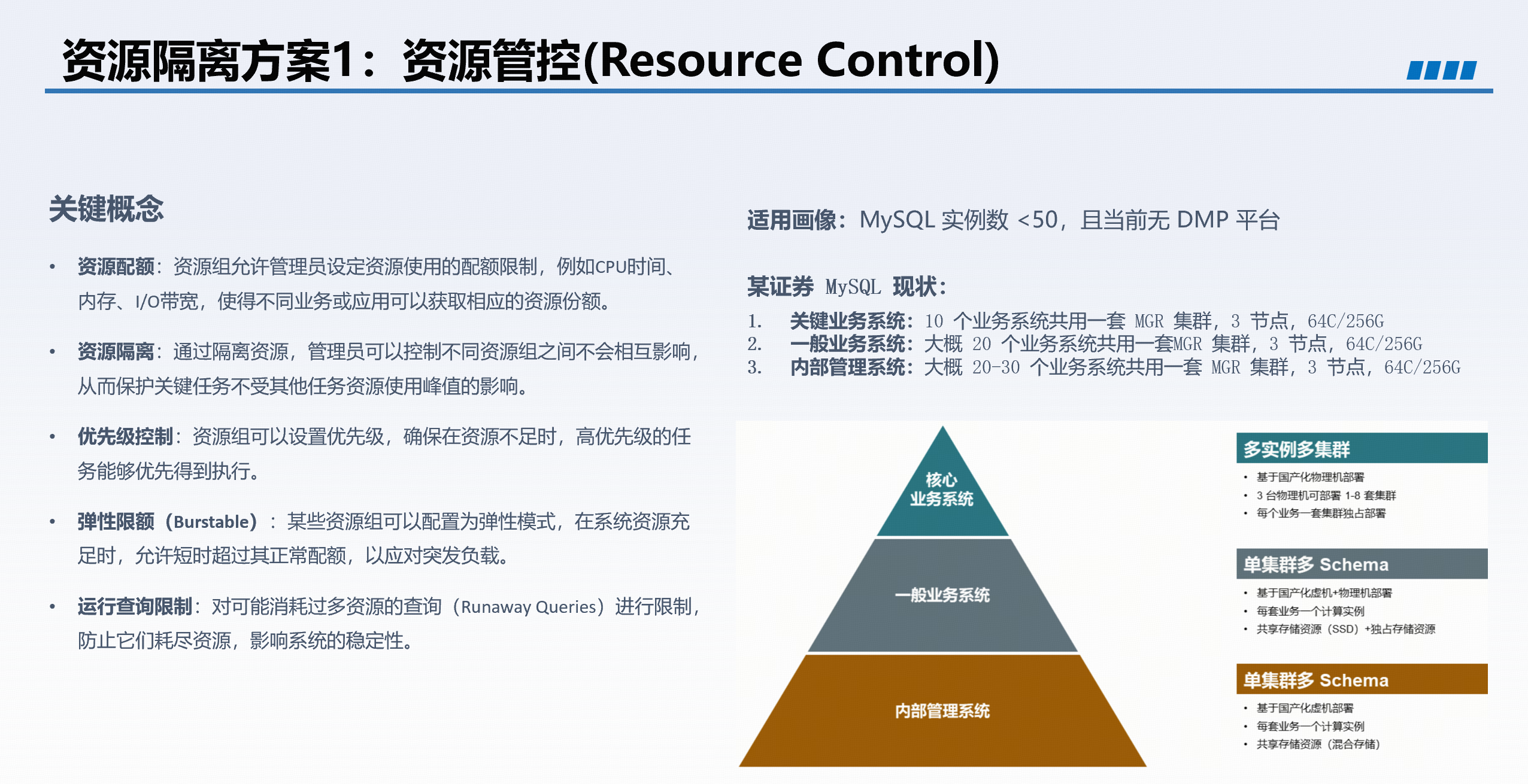
3. 资源隔离
资源管控方案
TiDB 提供多种资源隔离手段:
- 资源组(Resource Group):基于流控机制,为不同业务设定资源上限(如 CPU、IO),适用于多套小型业务共享集群。例如,跑批业务与联机业务分时运行,可确保跑批不冲击日间交易。
- 数据放置策略:实现物理隔离,将不同业务的数据分布到指定节点、磁盘,甚至独立计算引擎。适用于需要严格隔离的场景,也可在一套集群中同时支撑 TP 与 AP 业务(如 2 节点给 TP,1 节点给 AP)。
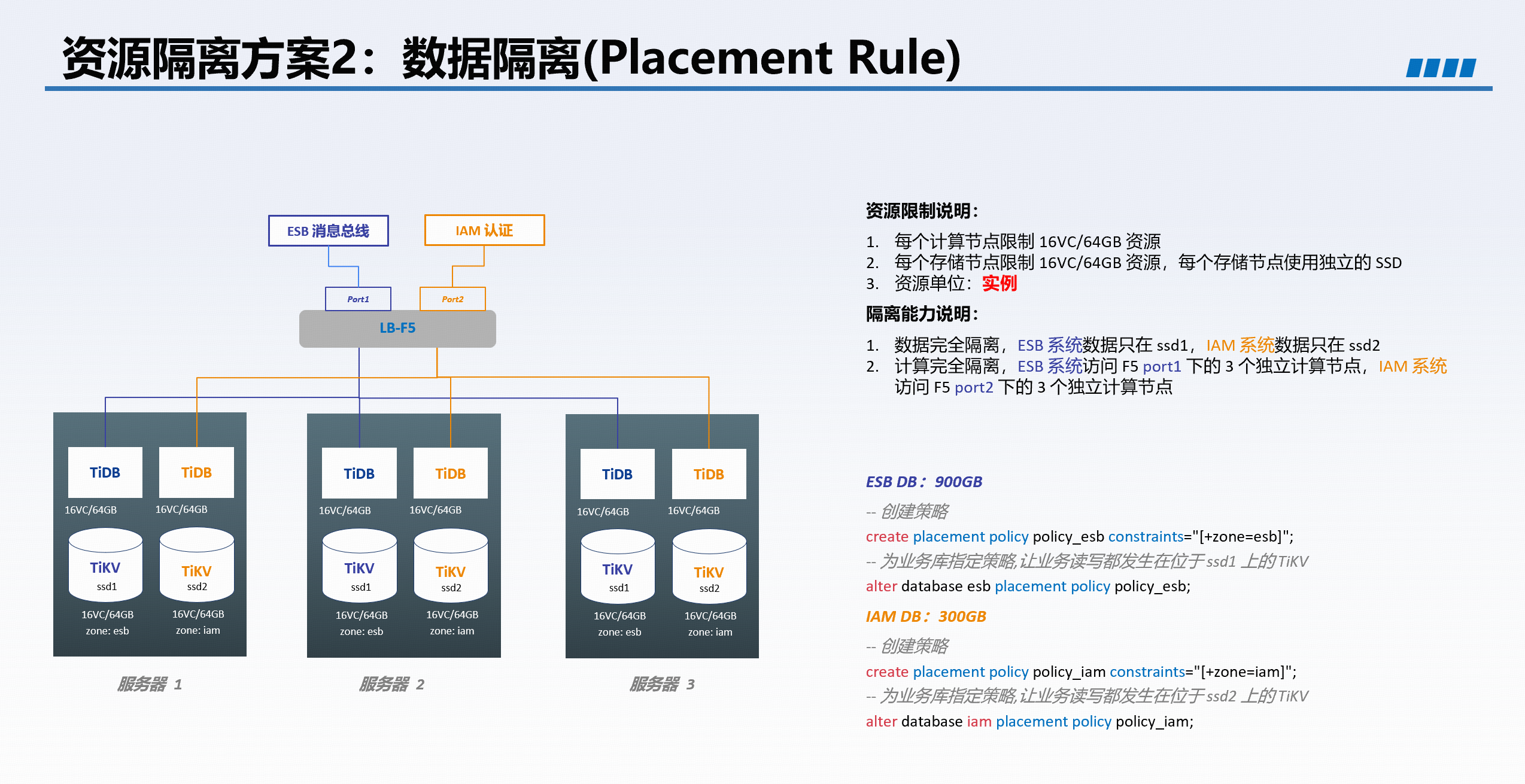
使用示例
- 预估资源容量 → 创建资源组并设定上限 → 将资源组绑定给业务用户。
- 配置数据放置策略,指定 TiKV 实例标签和副本约束。
典型案例
某客户一套 TiDB 集群承载多个应用。某日,A 应用的异常 SQL 导致某存储节点读线程池被占满,严重影响 B 业务。通过 Grafana 监控发现该节点资源使用率异常升高。随后,为不同业务绑定资源组进行限流,之后资源使用始终控制在设定上限内。未来如需更彻底的数据隔离,可进一步采用数据放置策略。
三、TiDB 企业版运维平台 TEM 介绍
TEM 是 TiDB 企业版提供的图形化管控平台,主要功能包括:
- 集群管理:可视化部署、扩缩容、监控告警、备份恢复等。
- 主机管理:统一管理所有主机资源。
- 巡检与告警:自动化健康检查与异常通知。
- 诊断与灾备:内置诊断工具,支持主备集群切换与容灾演练。
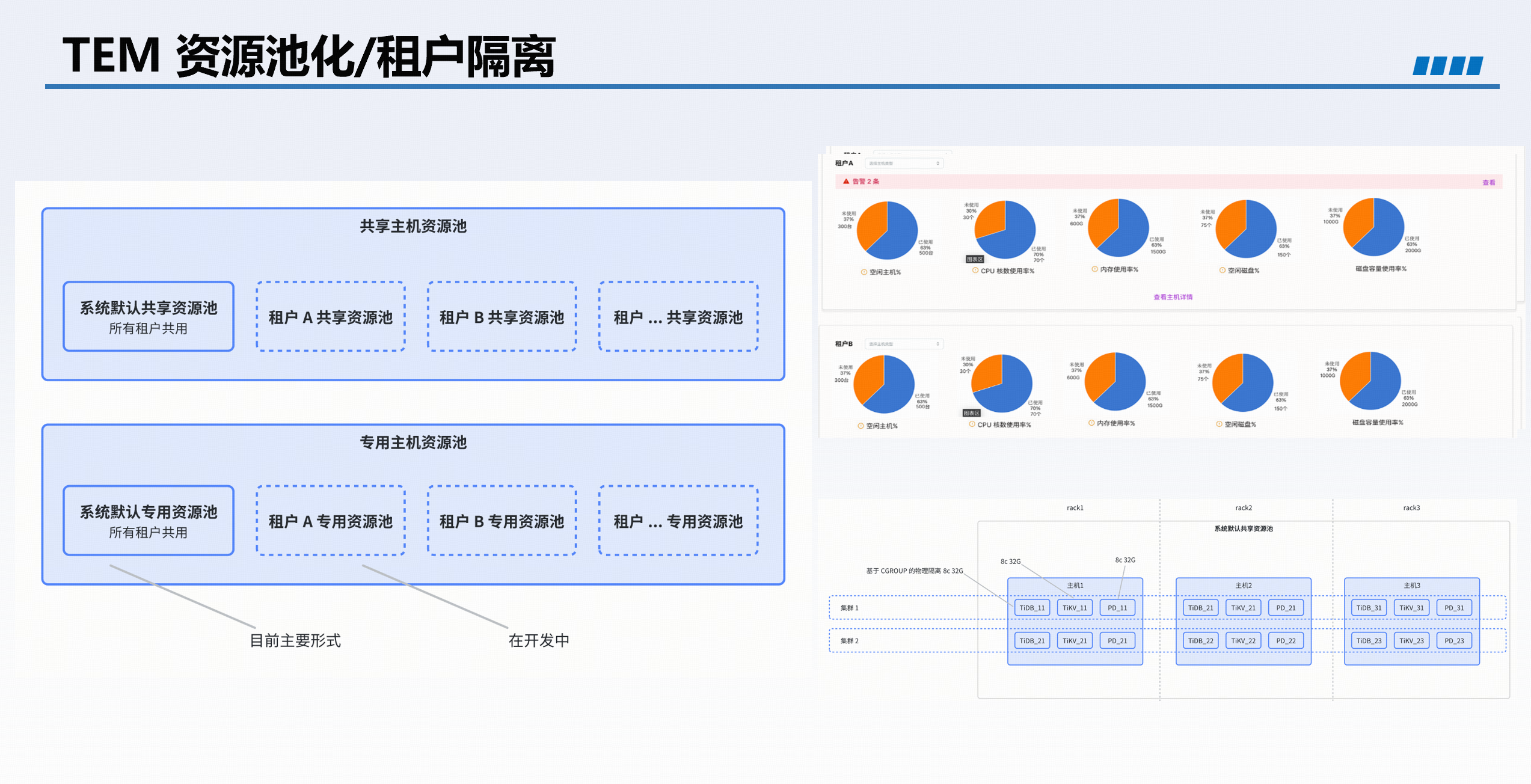
资源池化新能力
最新版本中,TEM 支持将主机资源抽象为资源池,可创建多个租户,为每个租户分配资源,租户内可自定义集群套餐(如标准套餐、敏捷模式套餐),实现资源精细化管理与自助服务。
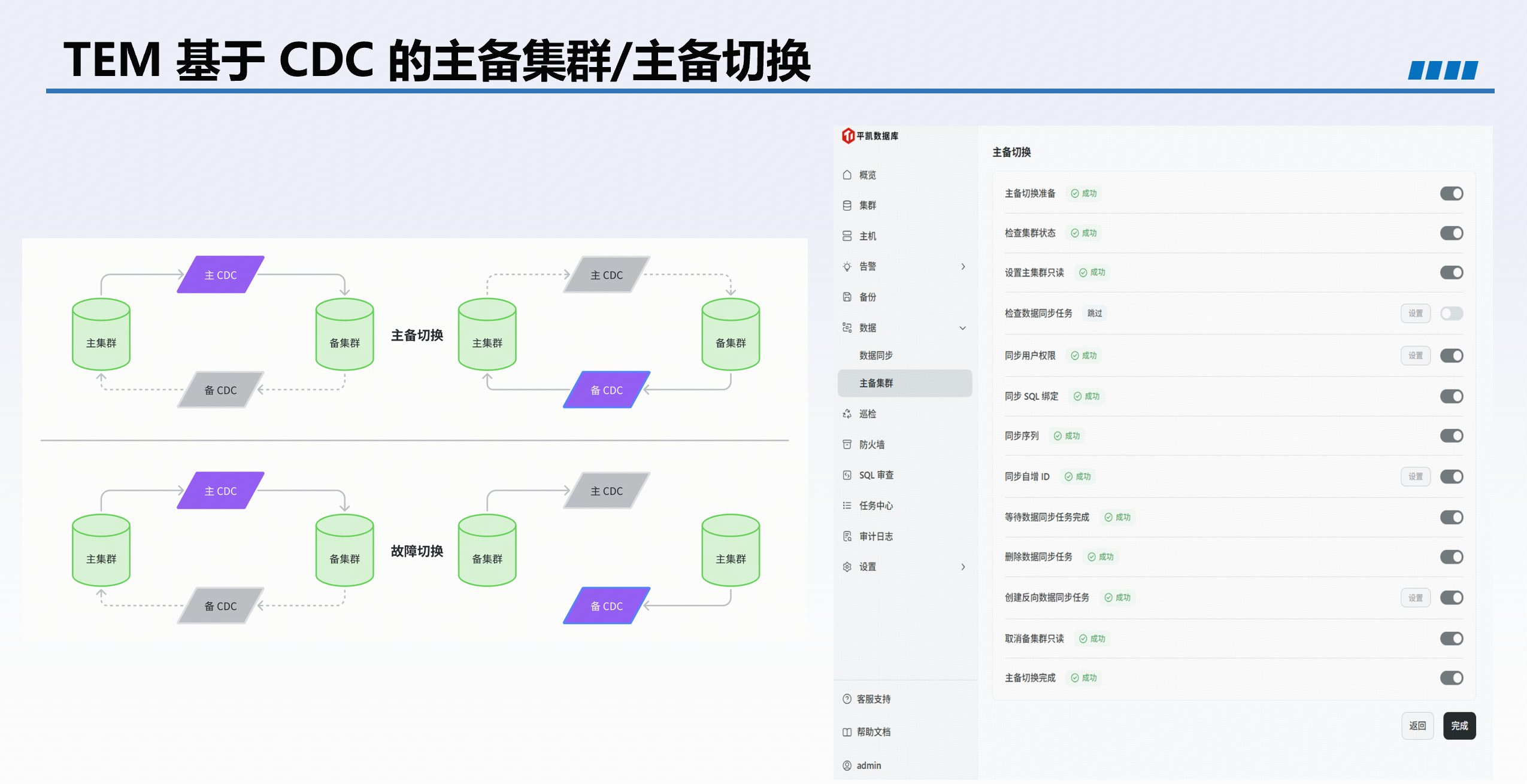
主备容灾增强
针对金融监管要求,TEM 提供了主备集群搭建及一键切换能力,便于定期进行容灾演练,确保业务连续性。
四、TiDB 最新特性概览
1. 敏捷模式
除标准分布式模式外,TiDB 新增小规格敏捷模式(1-3 节点,可运行于虚拟机),面向开发测试、中小业务量场景,降低入门门槛。
2. 聚能模式
通过新一代存储引擎、大 Region 架构及亲和性调度,实现更低延迟、更高性能,满足极致性能要求的核心交易场景。
3. MySQL 兼容性增强
在已有生态兼容基础上,新增存储过程、触发器、自定义函数等功能,进一步降低从 MySQL 迁移的改造成本。
4. 向量功能
支持向量数据类型与检索,可满足 AI 创新类业务(如智能投顾、相似性检索)对向量计算的需求。
5. 全文索引
新增全文索引支持,为日志分析、内容搜索等场景提供更高效的查询能力。
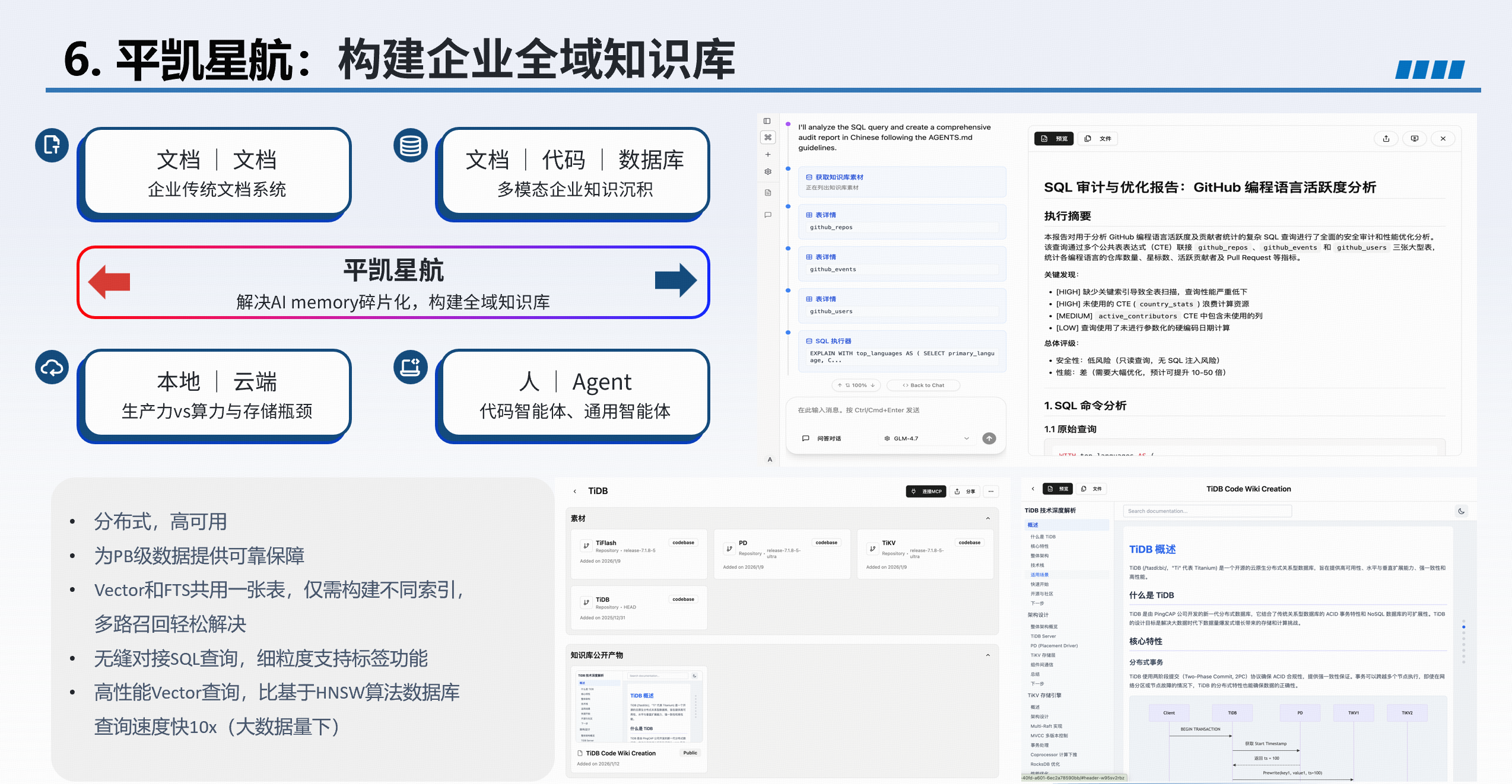
6. AI 方向的探索——平凯星航
即将推出的“平凯星航”旨在帮助企业构建全域知识库,典型应用包括:
- 自动生成 SQL 审计与优化报告;
- 基于内部代码生成 Code Wiki 文档;
- 智能问答等。
结语
从集中式到分布式,从单一负载到 HTAP,TiDB 正以原生分布式架构重新定义金融级数据库的弹性与效率。未来,我们将持续深耕证券行业场景,结合 AI 等前沿技术,为金融数字化转型提供更强大的数据基础设施。