

1、Lesson 06:TiDB 数据库 HTAP 概述
1.1 HTAP 技术

1.1.1 OLTP(在线事务处理)
- 存储模型:支持实时更新的行存
- 核心特点:高并发,一致性要求高
- 数据操作:每次操作少量数据
1.1.2 OLAP(在线分析处理)
- 存储模型:批量更新的列存
- 核心特点:并发数低
- 数据操作:每次操作大量数据
1.1.3 HTAP(混合事务/分析处理)
- 定义:同时具备 OLTP 和 OLAP 两种能力的混合架构,能够在同一套系统中同时处理高并发事务和大规模分析查询。
- 优势:避免了传统架构中数据在事务库和分析库之间的 ETL 同步过程,实现数据的实时分析,降低延迟与运维成本。
1.2 传统 OLTP 与 OLAP 分离架构的问题与 HTAP 解决方案
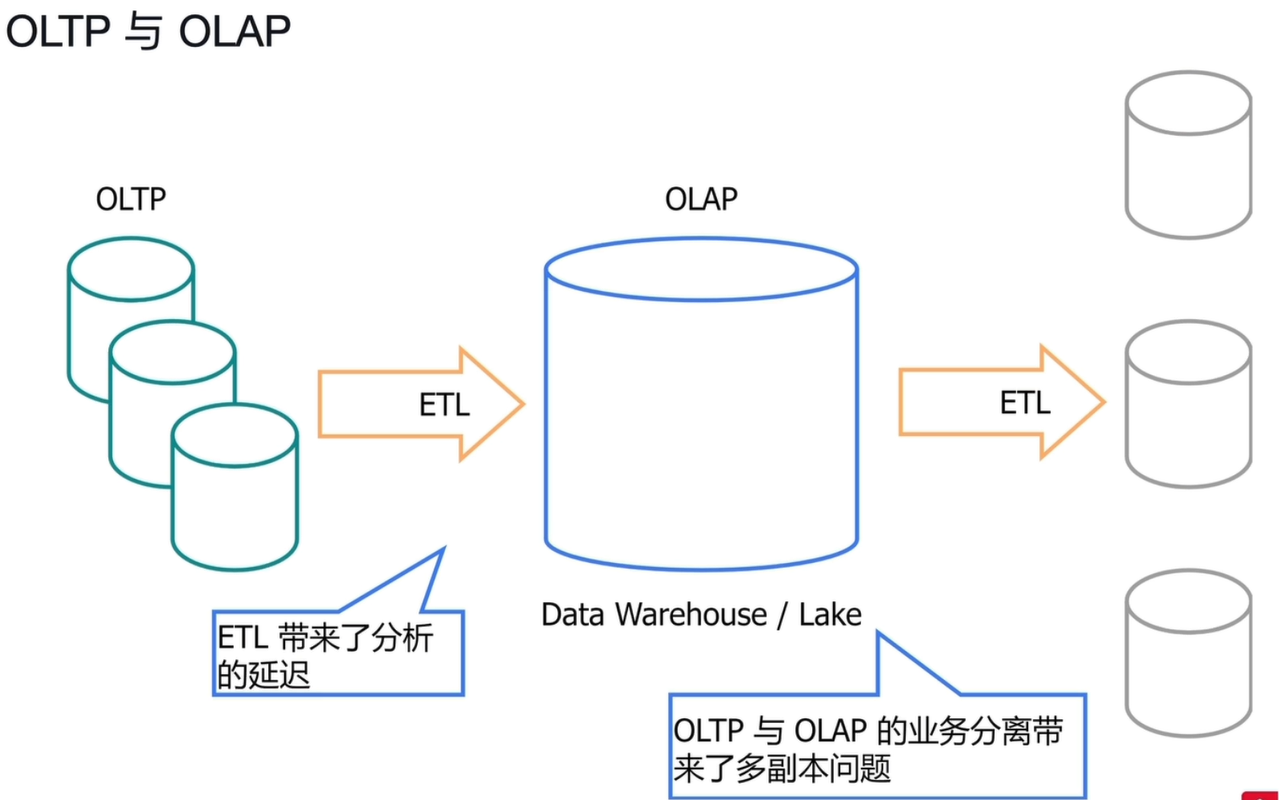
1.2.1 传统架构流程
- OLTP 系统:业务数据实时写入在线事务数据库。
- ETL 过程:定时将 OLTP 数据抽取、转换、加载到数据仓库/数据湖。
- OLAP 系统:基于仓库数据执行分析查询,结果再通过 ETL 分发到下游报表系统。
1.2.2 核心痛点
- 分析延迟:ETL 是定时批量任务,分析结果无法反映实时业务状态。
- 多副本问题:数据在多个系统间复制,维护成本高,一致性难以保障。
1.2.3 HTAP 解决方案
- 统一存储:在同一套数据库中同时支持行存(面向事务)和列存(面向分析),无需额外数据同步。
- 实时分析:直接对最新的业务数据执行复杂分析查询,消除 ETL 延迟。
- 单一副本:仅维护一份数据,降低运维复杂度,保证事务与分析的数据一致性。
1.3 HTAP 的核心要求

1.3.1 可扩展性
- 分布式事务:支持跨节点的事务处理,保证事务的ACID特性,同时兼顾高并发与一致性。
- 分布式存储:数据可横向扩展存储节点,实现海量数据的存储与管理,支持数据的自动分片与负载均衡。
1.3.2 同时支持 OLTP 与 OLAP
-
同时支持行存和列存:
- 行式存储:满足OLTP场景的实时更新、高并发读写需求。
- 列式存储:优化OLAP场景的大规模聚合查询性能,降低I/O开销。
-
OLTP 与 OLAP 业务隔离:通过资源调度、负载隔离机制,避免两类负载互相干扰,保障各自的性能表现。
1.3.3 实时性
- 行存与列存数据实时同步:事务写入的数据能实时同步到列存副本,确保分析查询能访问最新数据,消除传统架构的ETL延迟。
1.4 TiDB 的 HTAP 架构

1.4.1 整体架构组成
TiDB 的 HTAP 架构采用分布式分层设计,核心组件包括:
-
PD 集群(PD cluster)
- 集群的元数据管理中心,负责全局调度、负载均衡与分布式事务协调。
- 管理 TiKV 节点,实现数据分片的自动调度与故障恢复。
-
TiDB Server 层
- 兼容 MySQL 协议,作为应用访问的入口节点,处理 SQL 解析、优化与执行。
- 无状态设计,可水平扩展,同时支持 OLTP 和 OLAP 负载的接入。
-
存储集群(Storage Cluster)
- TiKV:面向 OLTP 的行式存储引擎,支持高并发事务、强一致性和水平扩展,负责业务数据的实时写入与读取。
- TiFlash:面向 OLAP 的列式存储引擎,通过实时同步 TiKV 数据,为大规模分析查询提供高性能支持,与 TiKV 形成行存+列存的混合存储模型。
1.4.2 HTAP 能力实现
- 行存与列存实时同步:TiFlash 以 Raft Learner 角色实时复制 TiKV 数据,确保分析查询能访问最新数据,消除传统 ETL 延迟。
- 负载隔离:OLTP 负载由 TiKV 处理,OLAP 负载由 TiFlash 处理,两者通过不同的存储引擎和资源调度实现隔离,避免互相干扰。
- 统一入口:应用通过 TiDB Server 访问数据,无需区分事务与分析场景,由 TiDB 自动路由到合适的存储引擎执行查询。
1.5 TiDB 数据库的HTAP 核心特性

1.5.1 行列混合存储
- 列存(TiFlash)支持基于主键的实时更新:TiFlash 作为列式存储引擎,能够实时接收 TiKV 的数据变更,保证分析查询的数据时效性。
- TiFlash 作为列存副本:TiFlash 以 Raft Learner 角色同步 TiKV 数据,既作为分析负载的专用副本,又不影响主事务流程。
- OLTP 与 OLAP 业务隔离:事务负载由 TiKV 处理,分析负载由 TiFlash 处理,通过存储引擎和资源调度实现物理隔离,避免性能互相干扰。
1.5.2 智能路由与执行优化
- 智能选择(CBO 自动或人工选择):基于代价的优化器(CBO)会根据查询类型、数据分布和统计信息,自动选择最优的执行路径,决定路由到 TiKV 还是 TiFlash 执行;也支持通过 Hint 人工指定执行引擎。
1.5.3 分布式计算架构
- MPP 架构:TiFlash 采用大规模并行处理(MPP)架构,支持跨节点的分布式查询执行,能高效处理复杂聚合、多表关联等分析场景,充分利用列存的优势提升性能。
1.6 TiDB MPP 架构详解

1.6.1 核心定义与适用场景
MPP(Massively Parallel Processing,大规模并行处理)是 TiFlash 提供的分布式计算架构,专为处理大规模分析查询设计:
- 适用场景:大量数据的 Join、聚合等复杂分析查询
- 执行位置:所有 MPP 计算均在 TiFlash 节点内存中完成,避免不必要的磁盘 I/O
- 当前限制:目前仅支持等值连接(Equi-Join)
1.6.2 执行流程与角色分工
-
TiDB Server(协调节点/Coordinator):
- 接收用户 SQL 请求,解析并生成分布式执行计划
- 向多个 TiFlash 节点分发任务,并协调节点间的数据交换与结果汇总
-
TiFlash 节点(计算节点):
- 接收并执行本地分片数据的计算任务
- 节点间直接进行数据交换(Shuffle),完成分布式 Join 和聚合
- 将中间结果返回给 TiDB Server 进行最终汇总
-
使用验证方式: 可通过
Enforce_mpp语句强制使用 MPP 模式,验证查询是否支持该架构执行,便于性能调优与问题排查。
1.6.3 执行示例解析
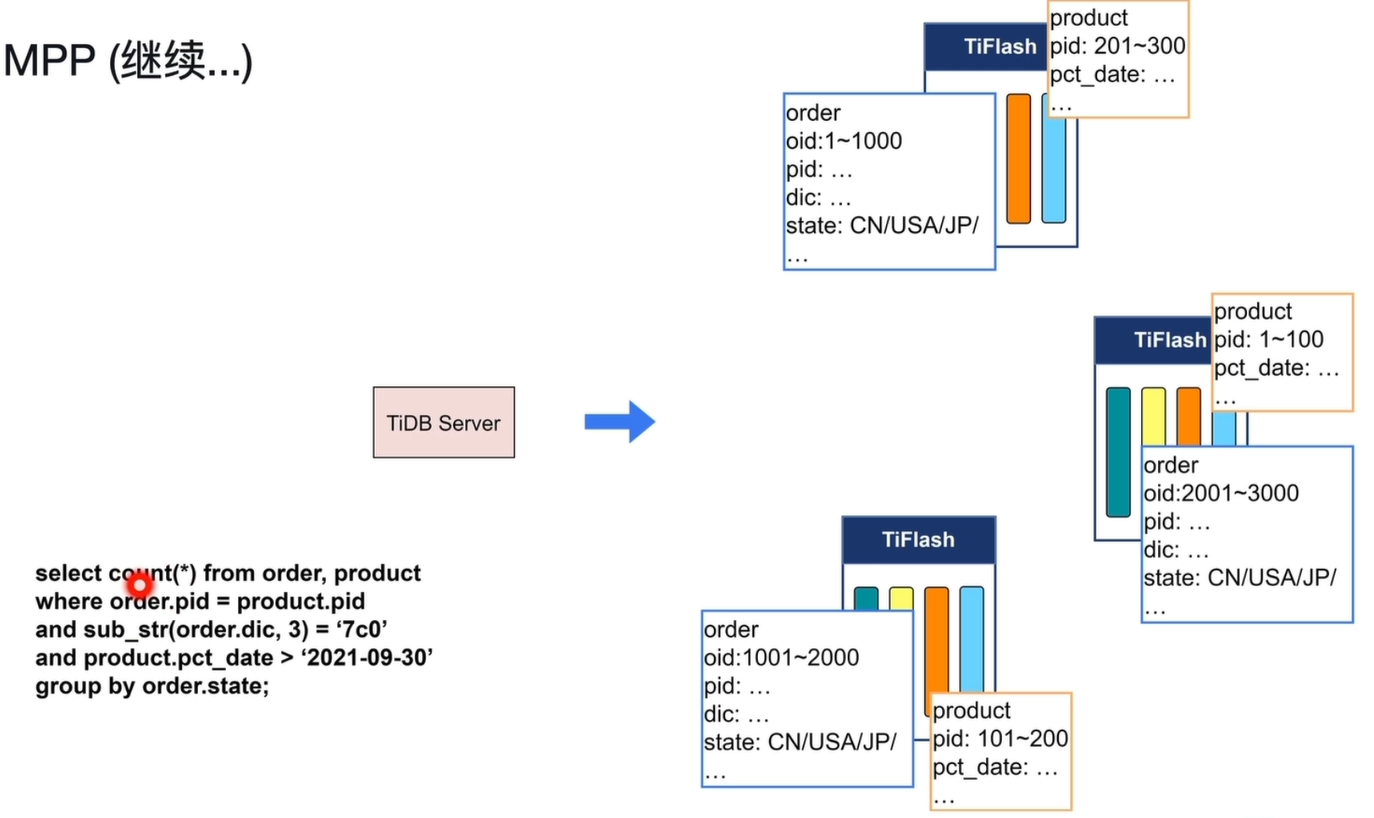
SQL 为例:
select count(*) from order, product
where order.pid = product.pid
and sub_str(order.dic, 3) = '7c0'
and product.pct_date > '2021-09-30'
group by order.state;
-
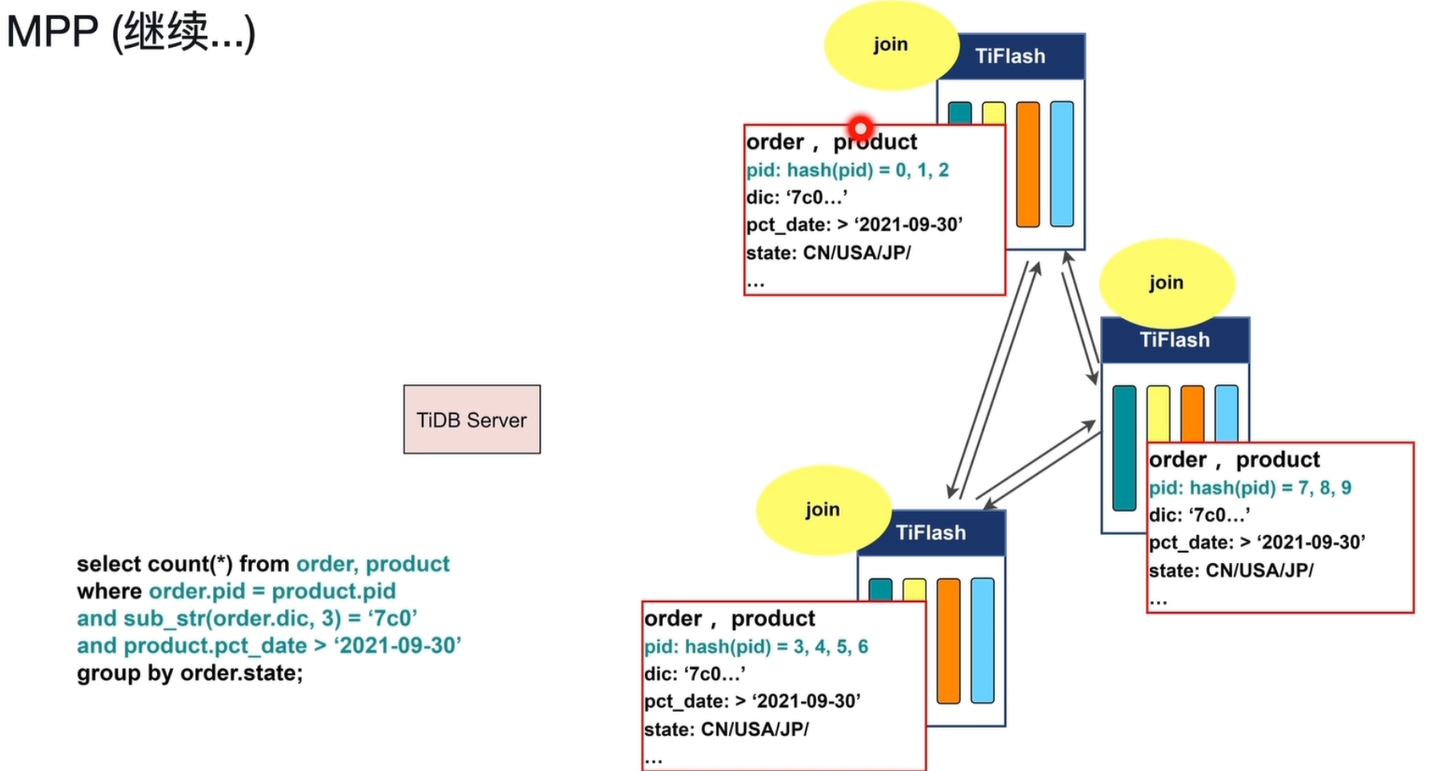
数据分片与本地过滤:
-
order表按 oid 范围分片,product表按 pid 范围分片,分布在多个 TiFlash 节点。 -
每个 TiFlash 节点先对本地数据执行过滤:
order表过滤sub_str(order.dic, 3) = '7c0'product表过滤product.pct_date > '2021-09-30'
-
过滤后的数据量大幅减少,降低后续 Join 和聚合的开销。
-
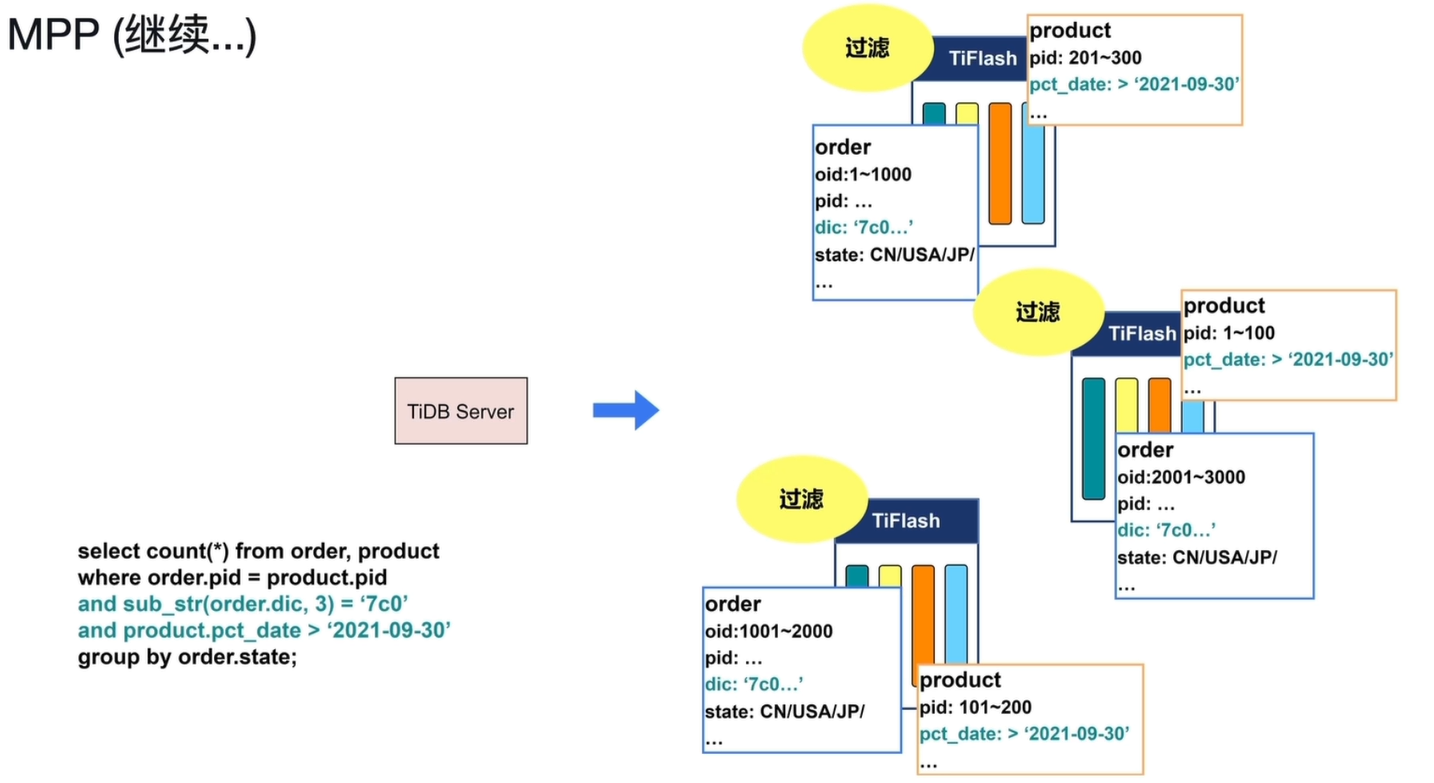
-
数据交换(Shuffle)阶段 1:按 pid 分区:
- 为了基于
order.pid = product.pid进行等值 Join,TiFlash 会对过滤后的数据按pid进行哈希分片(如hash(pid) = 0~2、3~6、7~9)。 - 节点间通过数据交换,将相同
pid哈希值的order和product数据发送到同一个目标节点。 - 这样,目标节点上同时拥有了 Join 双方的数据,可以在本地完成后续的 Join 操作。
- 为了基于
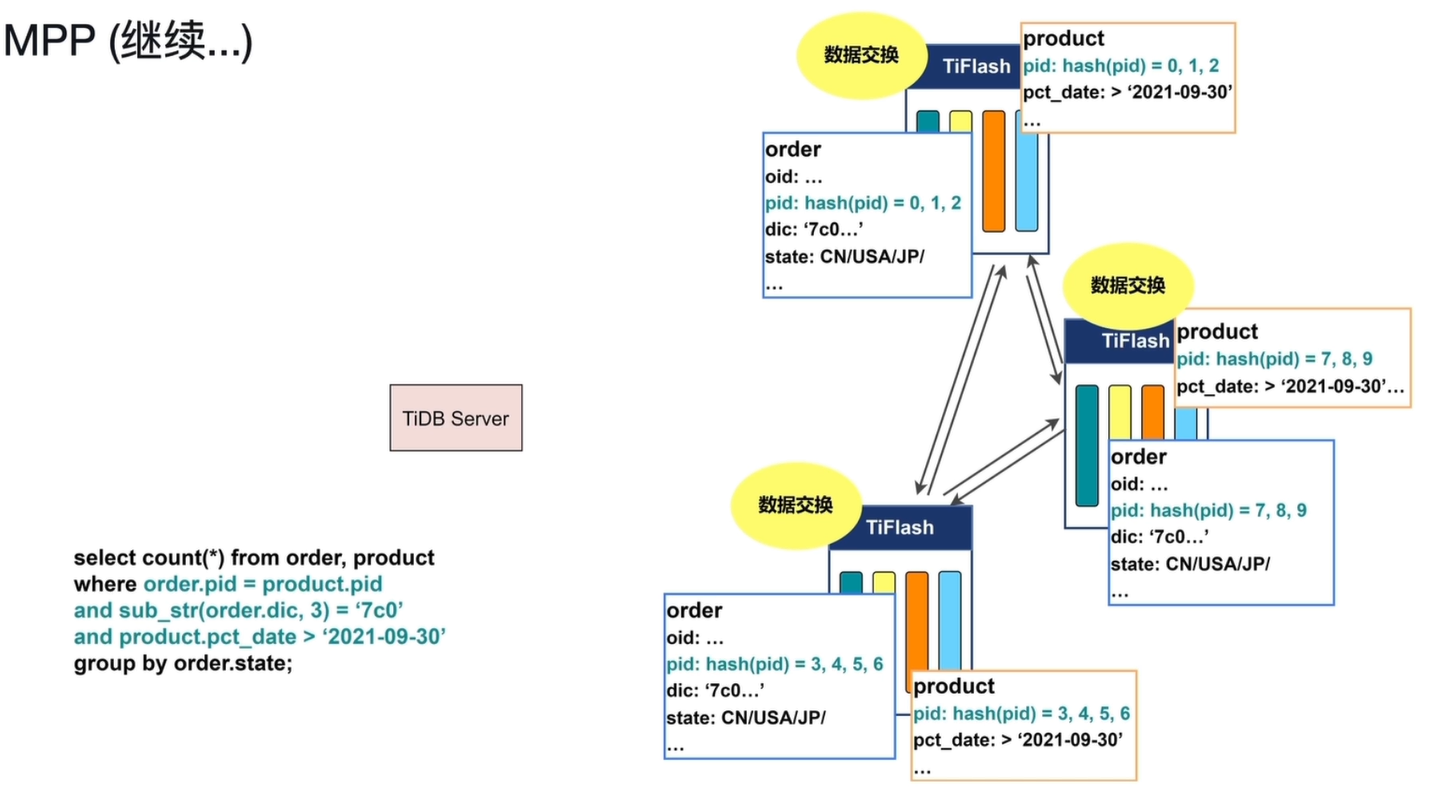
-
分布式 Join 阶段:
- 每个 TiFlash 节点收到 Shuffle 过来的数据后,在本地完成
order与product的等值连接(Join)。 - 此时,每个节点上都持有了 Join 后的完整数据集,且数据按
pid分布在不同节点,实现了并行 Join 处理。
- 每个 TiFlash 节点收到 Shuffle 过来的数据后,在本地完成
-
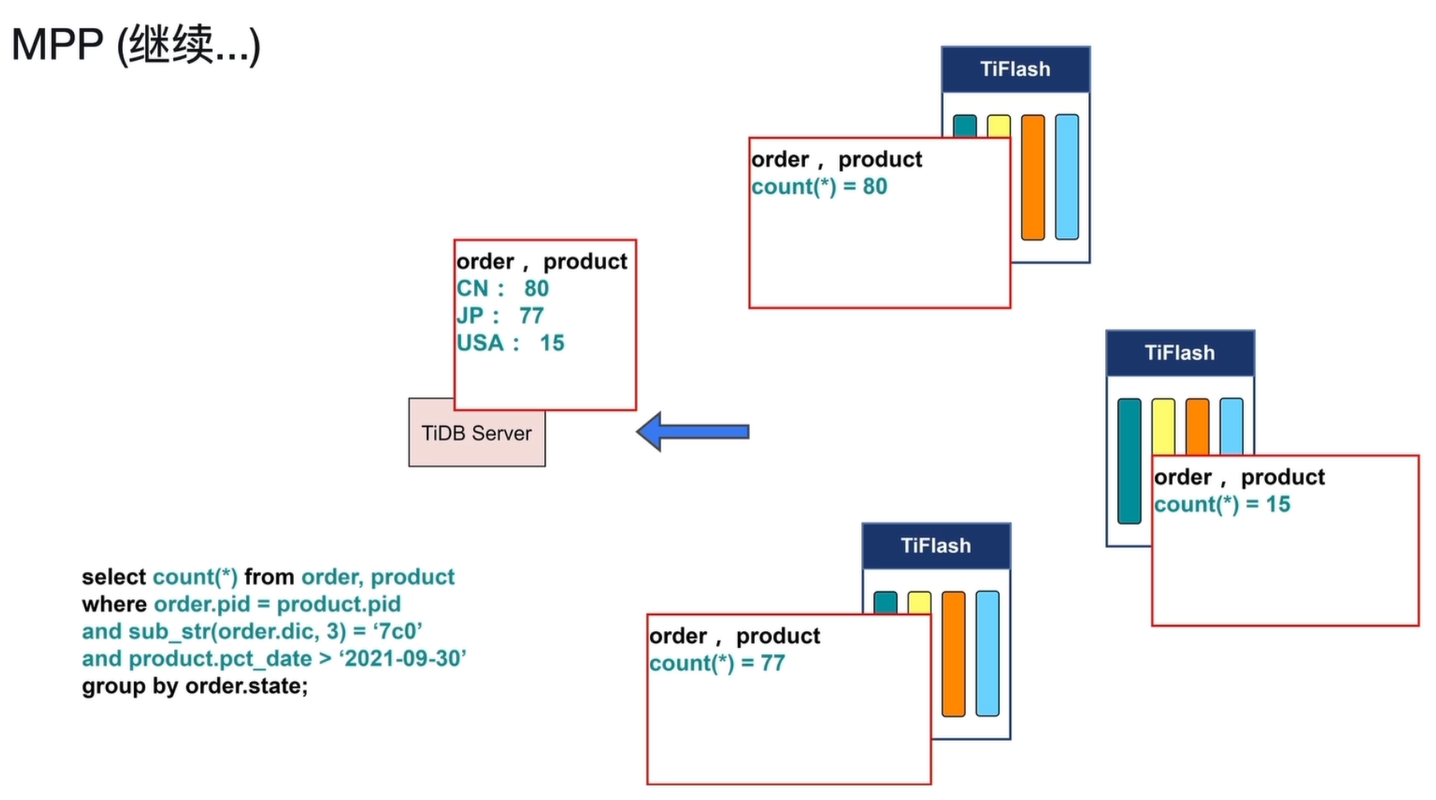
数据交换(Shuffle)阶段 2:按 state 分区:
- 为了执行
group by order.state,需要将 Join 后的数据按state进行二次哈希分区(如hash(state) = CN、USA、JP)。 - 节点间再次进行数据交换,将相同
state的数据发送到同一个目标节点,确保每个目标节点上只包含同一state的数据。
- 为了执行

-
本地聚合阶段:
- 每个 TiFlash 节点收到 Shuffle 过来的同
state数据后,在本地执行count(*)聚合计算,得到每个state的统计结果(如 CN: 80、JP: 77、USA: 15)。 - 这一步是完全并行的,每个节点只处理自己负责的
state分区数据。
- 每个 TiFlash 节点收到 Shuffle 过来的同

-
结果汇总与返回阶段:
- 各 TiFlash 节点将本地的聚合结果返回给 TiDB Server。
- TiDB Server 汇总所有节点的结果,整理成最终的查询结果集(如
CN: 80, JP: 77, USA: 15),并返回给用户。
1.6 总结 TiDB MPP 架构详解
TiFlash 的 MPP 架构是 TiDB 实现高性能分析的核心,其完整执行流程如下:
- 数据分片与本地过滤:数据按范围分布在多个 TiFlash 节点,各节点先对本地数据执行过滤,减少后续计算量。
- 第一次 Shuffle(按 Join Key 分区):为执行等值 Join,数据按
pid哈希分区,将相同pid的数据发送到同一节点。 - 分布式 Join:各节点在本地完成
order与product的等值连接。 - 第二次 Shuffle(按 Group Key 分区):为执行
group by,数据按state二次哈希分区,将相同state的数据发送到同一节点。 - 本地聚合计算:各节点在本地执行
count(*)聚合,得到每个state的统计结果。 - 结果汇总与返回:各节点将结果返回给 TiDB Server,由其汇总整理后返回给用户。
1.7 TiDB 混合工作负载场景
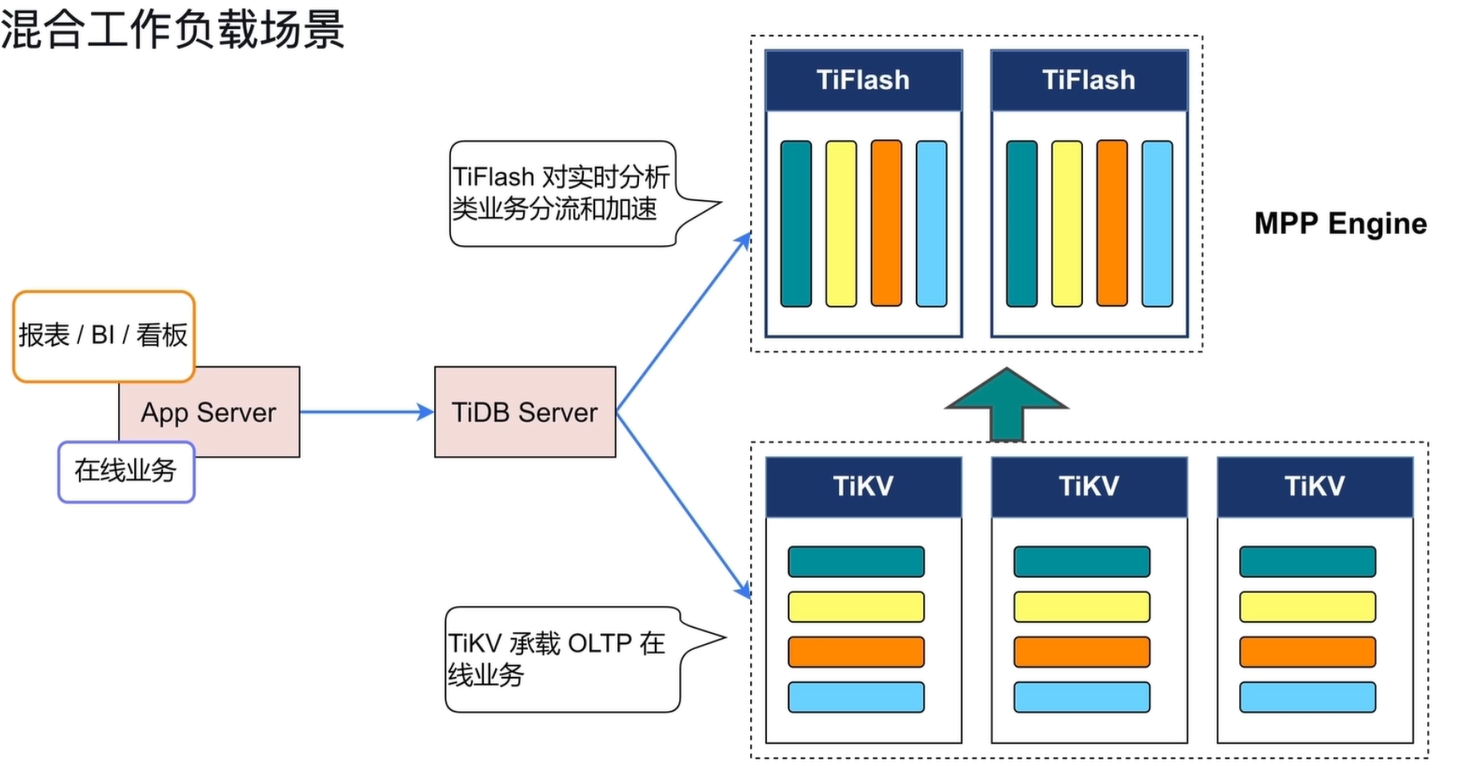
TiDB 的 HTAP 架构可以同时承载 OLTP 在线业务与 OLAP 分析业务,实现混合工作负载的高效处理。
1.7.1 整体流程
-
业务入口:
- 在线业务(OLTP)、报表/BI/看板(OLAP)等请求,统一通过应用服务器(App Server)接入。
- 所有请求以 MySQL 协议发送到
TiDB Server。
-
负载分流与路由:
-
TiDB Server作为统一入口,根据查询类型自动路由到不同的存储引擎:- OLTP 在线业务:路由到
TiKV集群,由行式存储引擎处理高并发事务读写。 - OLAP 实时分析:路由到
TiFlash集群,由列式存储引擎(MPP Engine)处理大规模分析查询。
- OLTP 在线业务:路由到
-
-
存储与计算分工:
- TiKV 集群:承载 OLTP 在线业务,保障事务的低延迟与高并发。
- TiFlash 集群:通过 MPP 引擎对实时分析类业务进行分流和加速,利用列式存储与并行计算提升查询性能。
-
数据一致性保障:
- TiFlash 以 Raft Learner 角色实时同步 TiKV 数据,确保分析查询访问的数据与事务数据保持强一致。
1.8 传统流式计算场景对比
传统架构中,为了支撑多种业务需求,常采用 CDC(Change Data Capture)技术进行数据分发,存在数据链路复杂、实时性不足等问题。

1.8.1 架构流程
-
数据来源:在线应用(online APP)产生的业务数据,统一写入主数据库。
-
数据分发:通过 CDC 工具捕获数据变更,并将数据同步到多个下游系统:
- MySQL:承载 OLTP 在线业务。
- MPP 系统:用于报表与分析场景。
- Elasticsearch:用于数据检索场景。
- Hadoop/数仓(图中大象图标):用于聚合计算与离线报表场景。
1.8.2 核心痛点
- 数据链路复杂:需要维护多条 CDC 同步链路,架构臃肿,运维成本高。
- 数据实时性低:数据从主库同步到各下游系统存在延迟,无法满足实时分析需求。
- 一致性风险:多副本数据之间难以保证强一致性,容易出现数据不一致问题。
- 资源开销大:多套系统独立部署,硬件资源利用率低,整体成本高昂。
1.9 TiDB 流式计算场景优化方案
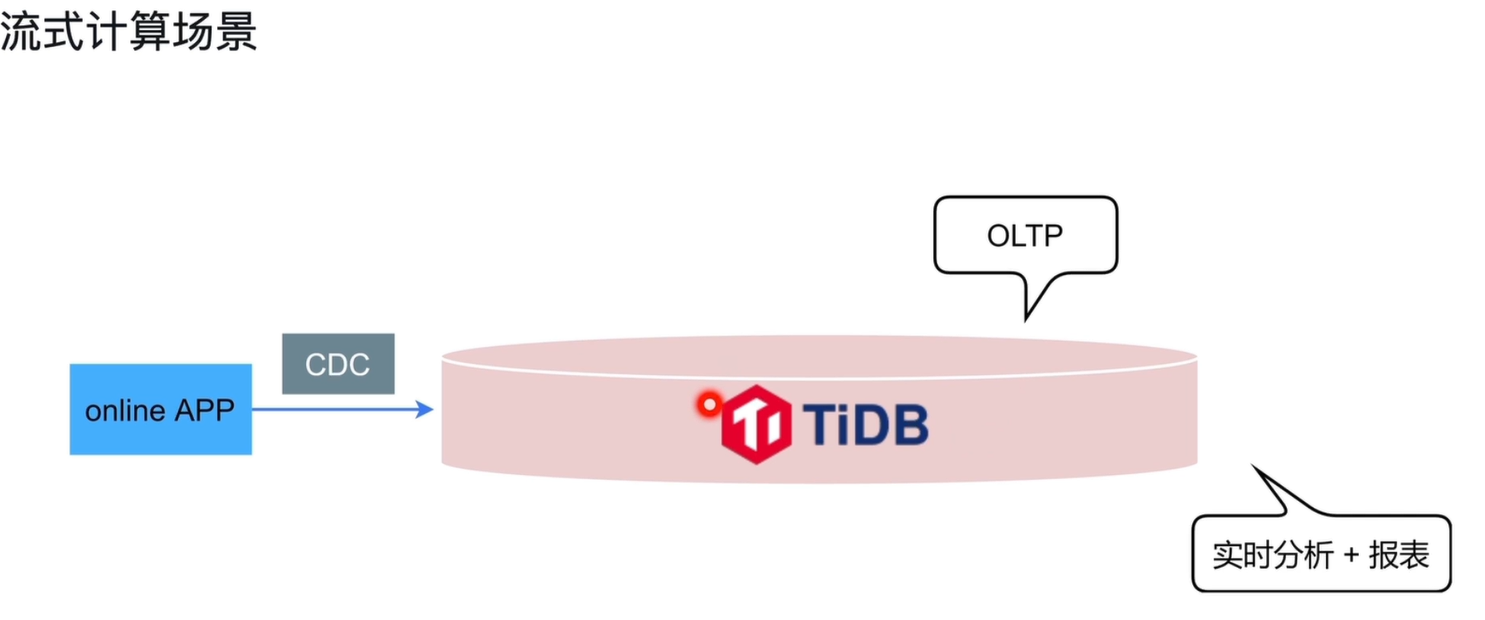
TiDB 的 HTAP 架构为传统流式计算场景提供了简化、高效的解决方案。
1.9.1 架构流程
-
数据来源:在线应用(online APP)产生的业务数据,直接写入 TiDB 集群。
-
统一处理引擎:TiDB 作为单一数据平台,同时承载两类核心业务:
- OLTP 在线业务:事务读写请求直接由 TiKV 行存引擎处理,保障低延迟与高并发。
- 实时分析 + 报表业务:分析查询由 TiFlash 列存引擎(MPP)处理,数据通过 Raft 协议实时同步,无需额外 CDC 工具。
1.9.2 优势对比
- 架构大幅简化:无需维护多条 CDC 同步链路,用一套 TiDB 集群即可同时支撑事务与分析需求,降低运维复杂度。
- 数据实时性高:TiFlash 实时同步 TiKV 数据,分析查询可直接访问最新数据,消除传统架构的数据延迟问题。
- 一致性保障:基于 Raft 协议实现行存与列存数据的强一致性,避免多副本数据不一致风险。
- 成本与资源优化:单平台替代多套异构系统,减少硬件投入,同时提升资源利用率。
2、Lesson 07: TiFlash
2.1 TiFlash 架构详解
TiFlash 是 TiDB 实现 HTAP 的核心列式存储引擎,其架构设计实现了数据实时同步与高效分析的结合。
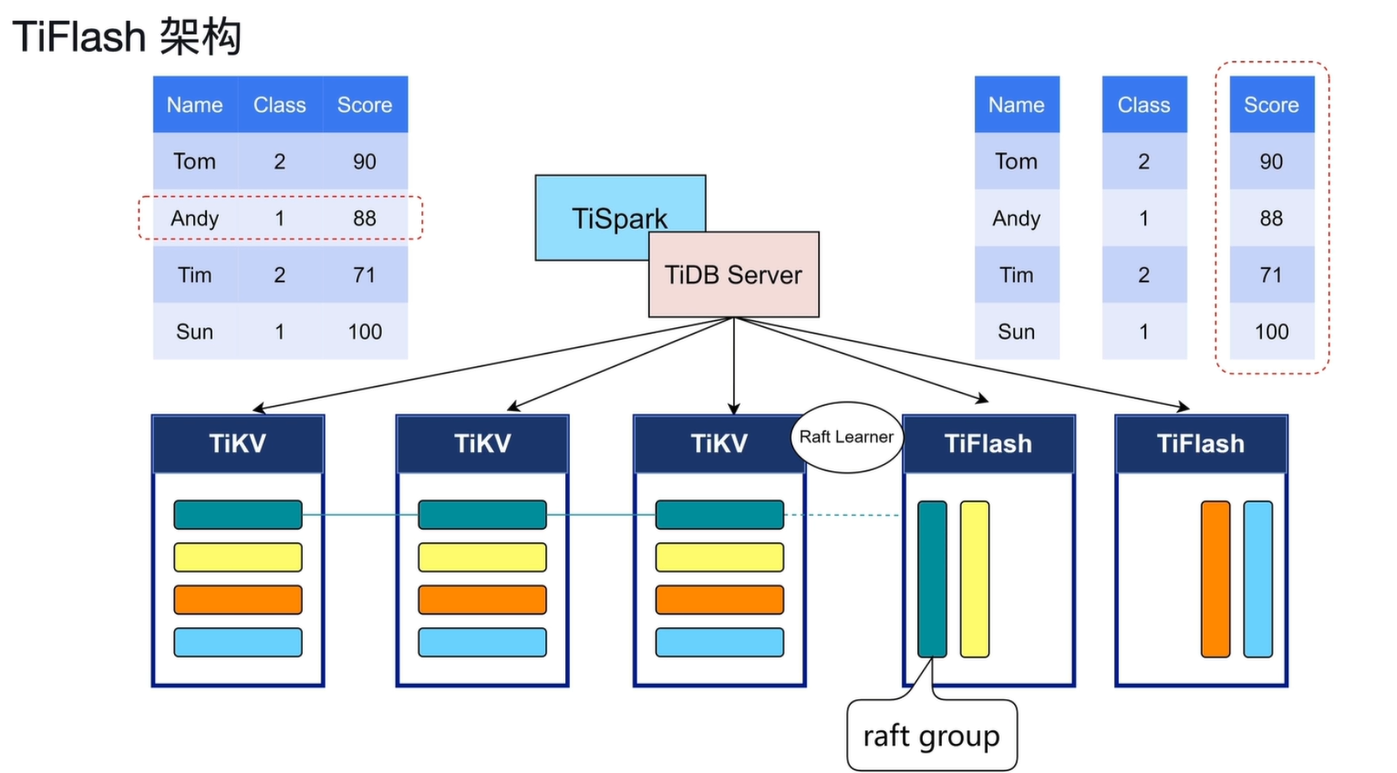
2.1.1 核心架构组成
-
数据同步机制:
- TiFlash 以 Raft Learner 角色加入 TiKV 的 Raft Group,实时接收 TiKV 的数据变更日志。
- 这种方式无需额外 CDC 工具,就能保证列存副本与主库数据的强一致性,同时不影响 OLTP 主流程性能。
-
存储模型:
- 行存(TiKV):数据按行存储,适合高并发事务读写。
- 列存(TiFlash):数据按列存储,同一列的数据连续存放,大幅降低分析查询的 I/O 开销。例如,查询
Score列时,只需读取Score列的数据块,无需读取整行。
-
计算与路由层:
- TiDB Server:作为统一入口,接收 SQL 请求并生成执行计划。
- TiSpark:支持通过 Spark 直接访问 TiFlash,兼容大数据生态的分析场景。
- 优化器会根据查询类型,自动将事务请求路由到 TiKV,将分析请求路由到 TiFlash,实现负载分流。
2.1.2 关键特性
- 实时数据同步:基于 Raft 协议的同步机制,保证 TiFlash 数据与 TiKV 秒级延迟,满足实时分析需求。
- 列式存储优化:列存格式大幅提升聚合、过滤等分析操作的性能,同时支持高压缩比,节省存储空间。
- 负载物理隔离:OLTP 与 OLAP 负载分别由 TiKV 和 TiFlash 处理,互不干扰,保障在线业务的稳定性。
2.2 TiFlash 主要功能
TiFlash 提供四大核心功能,支撑 TiDB 的混合事务/分析处理能力:

-
异步复制: TiFlash 以 Raft Learner 角色异步复制 TiKV 数据,不参与 Raft 选主流程,不会影响 OLTP 主流程的性能。数据同步延迟低,可满足实时分析需求。
-
一致性读取: TiFlash 支持强一致性读取,通过读取 Raft 日志的 commit index,确保查询到的数据与 TiKV 主库的最新状态一致,避免脏读问题。
-
引擎智能选择: TiDB 的代价优化器(CBO)会根据查询的类型、数据分布和统计信息,自动选择最优的执行引擎:
- 事务型查询路由到 TiKV 行存。
- 分析型查询路由到 TiFlash 列存,无需人工干预。
-
计算加速: TiFlash 采用列式存储 + MPP 大规模并行处理架构,对聚合、过滤、Join 等分析操作进行深度优化,可显著提升大规模数据查询的性能。
2.3 TiFlash 核心功能:异步复制
异步复制是 TiFlash 实现 HTAP 架构的关键设计,它保证了分析负载不会影响在线事务的性能。
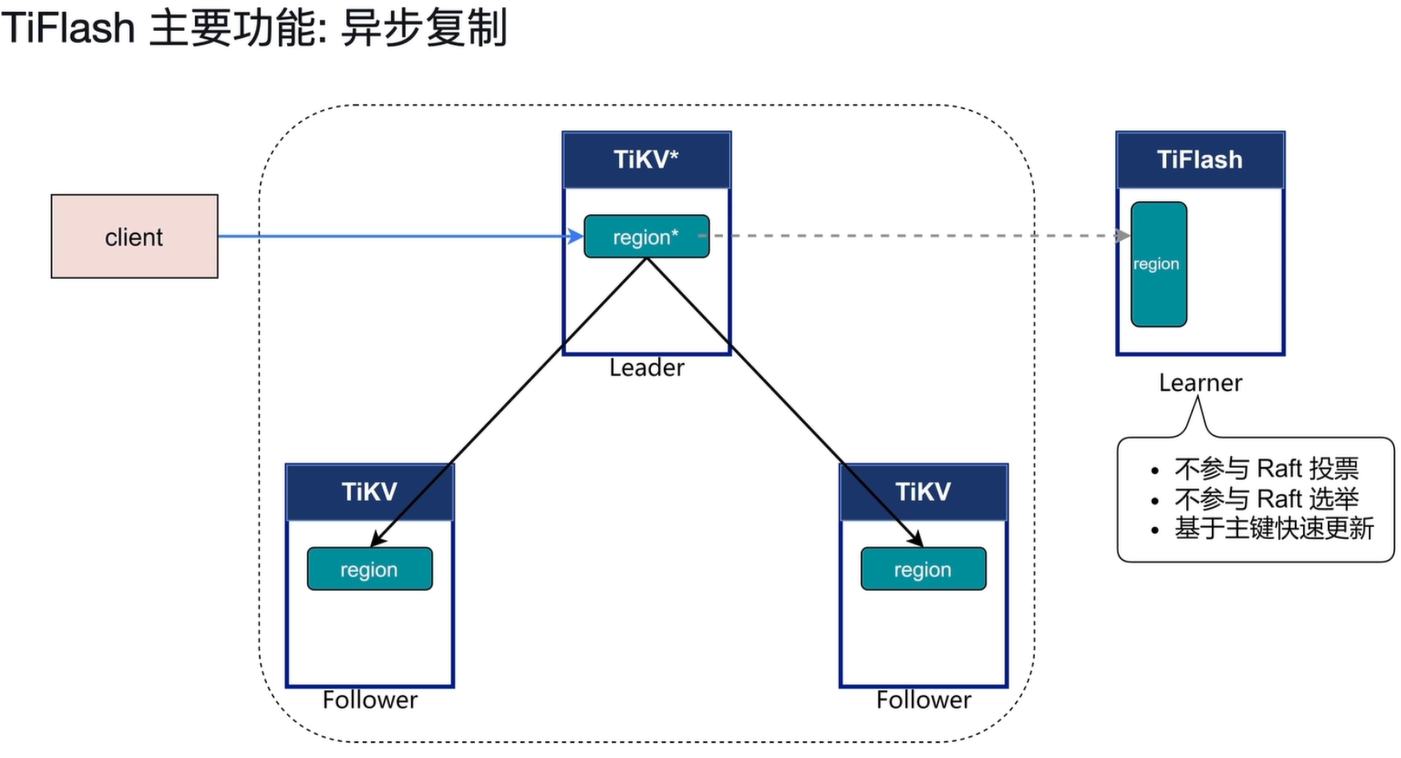
2.3.1 角色与原理
TiFlash 以 Raft Learner 角色加入 TiKV 的 Raft 复制组,工作原理如下:
- 不参与投票/选举:TiFlash 作为 Learner,不参与 Raft 协议的 Leader 选举和投票流程,不会影响 TiKV 主流程的可用性与写入性能。
- 被动接收数据:客户端写入数据时,只需等待 TiKV Leader 和多数派 Follower 确认即可返回;TiFlash 则异步、被动地接收 Leader 推送的 Raft 日志变更。
- 高效数据同步:基于主键实现快速更新,TiFlash 能高效处理增量数据变更,将同步延迟控制在秒级,同时大幅降低对 TiKV 的资源占用。
2.3.2 架构优势
- 读写性能隔离:OLTP 写入操作不受 TiFlash 同步过程的影响,保障了在线业务的低延迟与高并发。
- 数据一致性保障:通过 Raft 协议同步数据,TiFlash 与 TiKV 主库的数据保持最终一致性,满足分析业务的准确性要求。
- 运维简化:无需额外部署 CDC 工具,一套 Raft 协议同时支撑事务与分析副本,降低了架构复杂度与运维成本。
2.4 TiFlash 核心功能:一致性读取
虽然 TiFlash 是异步复制,但它通过特定机制实现了与 TiKV 一致的强一致性读取,避免脏读问题。
2.4.1 工作原理
- T0 时刻客户端写入
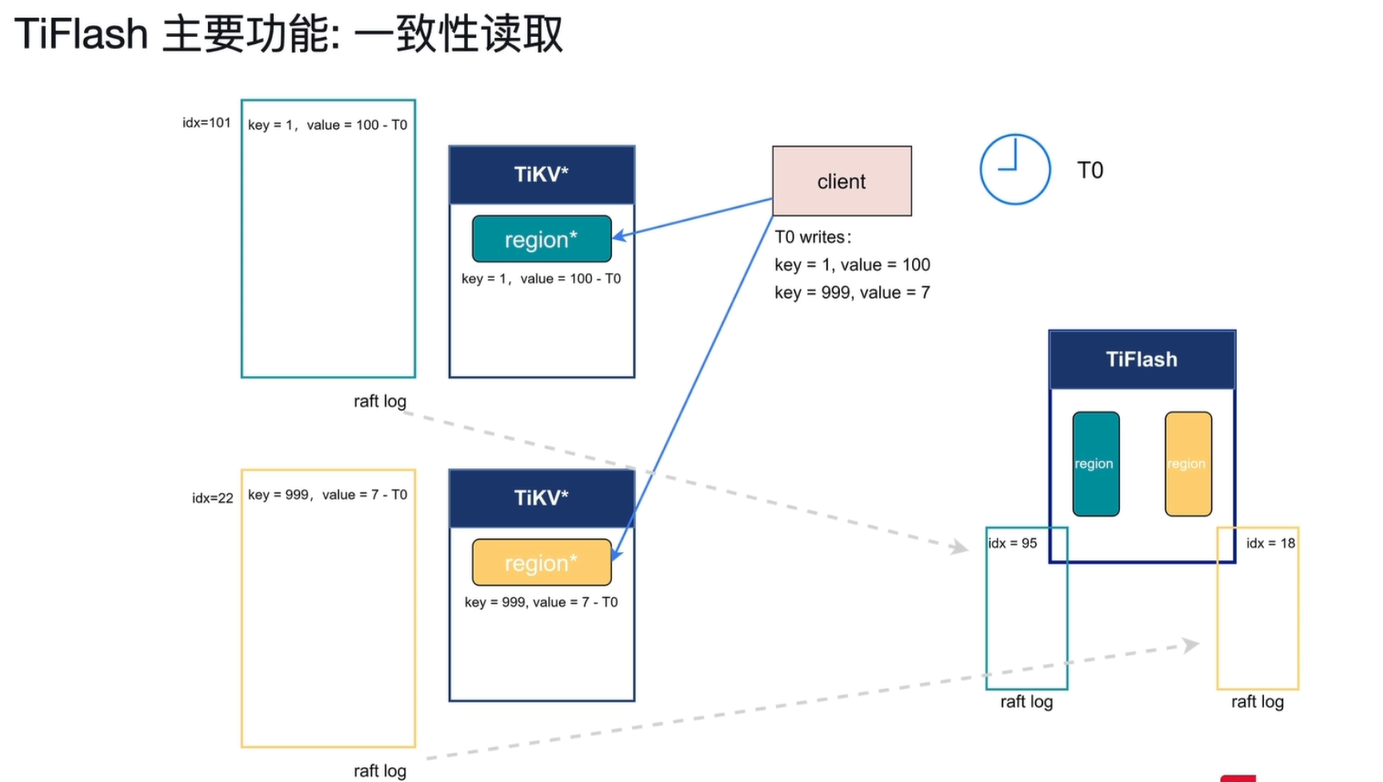
客户端向 TiKV 写入两条数据:key=1, value=100 和 key=999, value=7。
- 这两条数据分别属于不同的 Region,对应的 Raft 日志索引分别更新到
idx=101和idx=22。 - TiFlash 异步接收TiKV 的 Raft 日志,但不同 Region 同步进度不同:
key=1同步到idx=95,还没追上最新的idx=101,key=999同步到idx=18,也没追上最新的idx=22,均未追上主库最新进度。
- T1 时刻客户端查询:
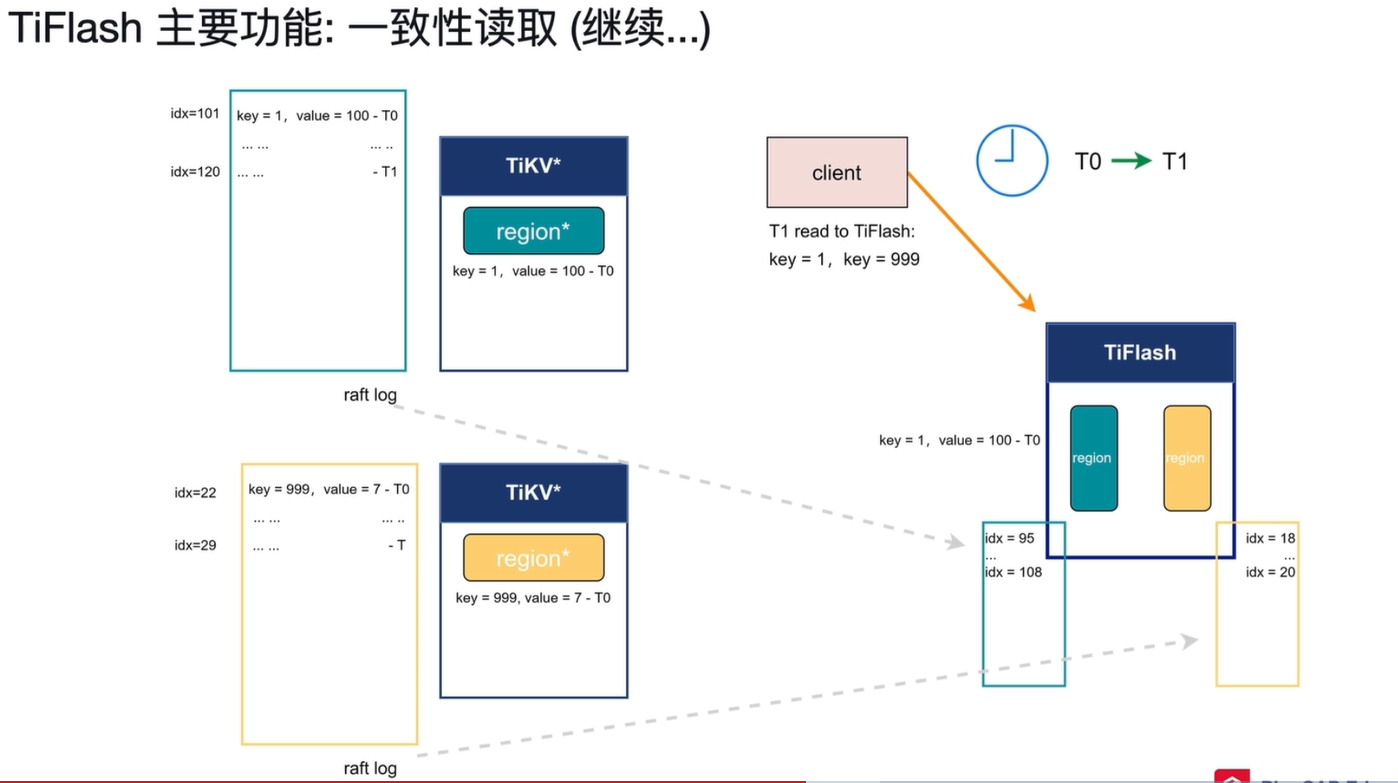
客户端向 TiFlash 发起查询,读取 key=1 和 key=999。
-
TiDB 先向 TiKV Leader 获取当前最新的
read index(即主库所有 Region 的最高提交索引,本例中为idx=120和idx=29)。-
TiFlash 收到
read index后,会等待本地相关 Region 的同步进度追上该索引:key=1所在 Region 继续同步,从idx=95更新到idx=108,再到idx=120。key=999所在 Region 继续同步,从idx=18更新到idx=20,再到idx=29。
-
当所有相关 Region 的同步进度都追上
read index后,TiFlash 才执行查询,返回与主库一致的数据:key=1, value=100和key=999, value=7,目前key=1,已经同步到idx=108,说明idx=101已经同步完成,key=999目前只到idx=20,还未同步到idx=29,此时一个已经同步完成,一个还未完成。TiFlash会询问何时同步完成,还不能返回数据。
-
- T2 时刻客户端写入:

- 客户端再次写入数据
key=1, value=200,主库key=1所在 Region 的 Raft 日志索引更新到idx=122。 - TiFlash 继续异步同步日志,此时
key=1所在 Region 同步进度为idx=115,尚未追上最新的idx=122;key=999所在 Region 同步进度为idx=21,尚未追上最新的idx=30。
- T3 时刻索引查询等待:
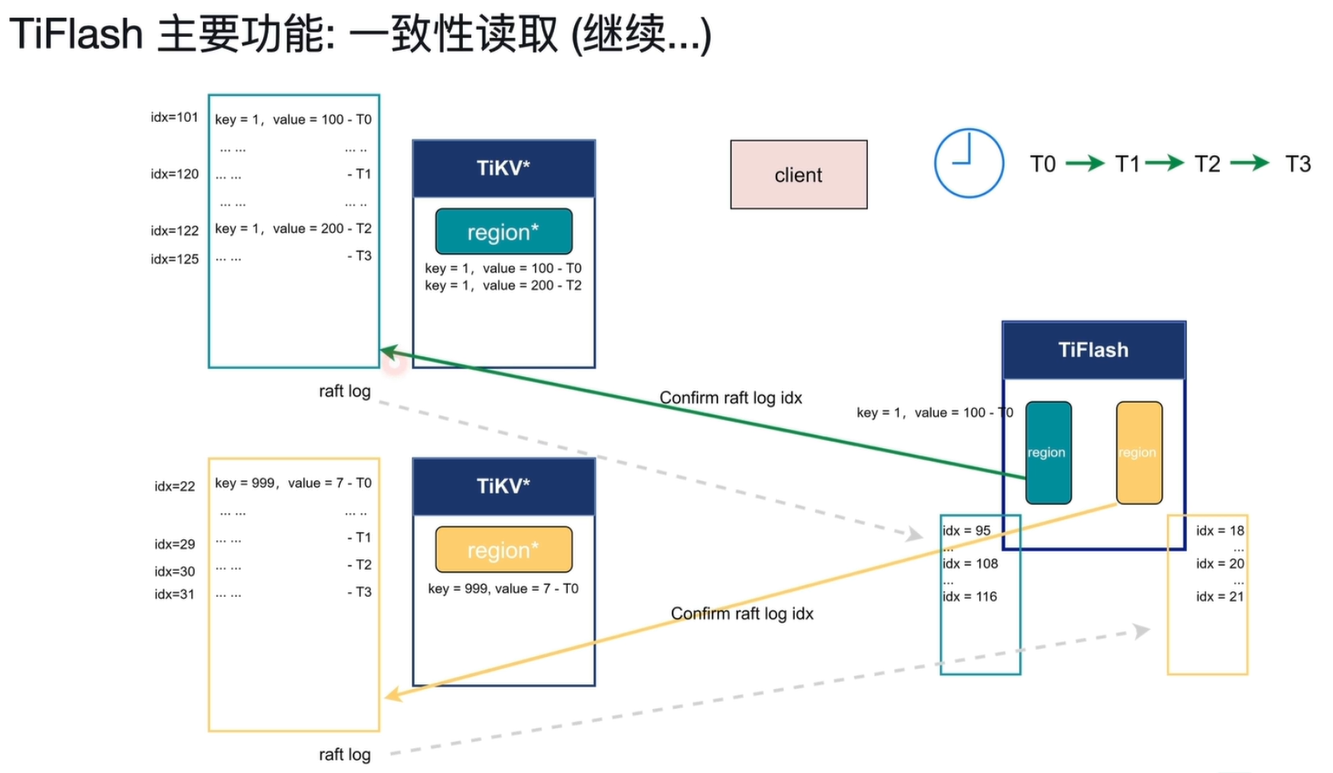
- TiFlash 轻量请求问询 TiKV,获取当前真实日志索引:
125、31,记作等待索引 Wait idx - TiFlash 以这两个索引为标准等待同步,确保此前所有写入数据都同步完成
- T4 时刻部分数据就绪:
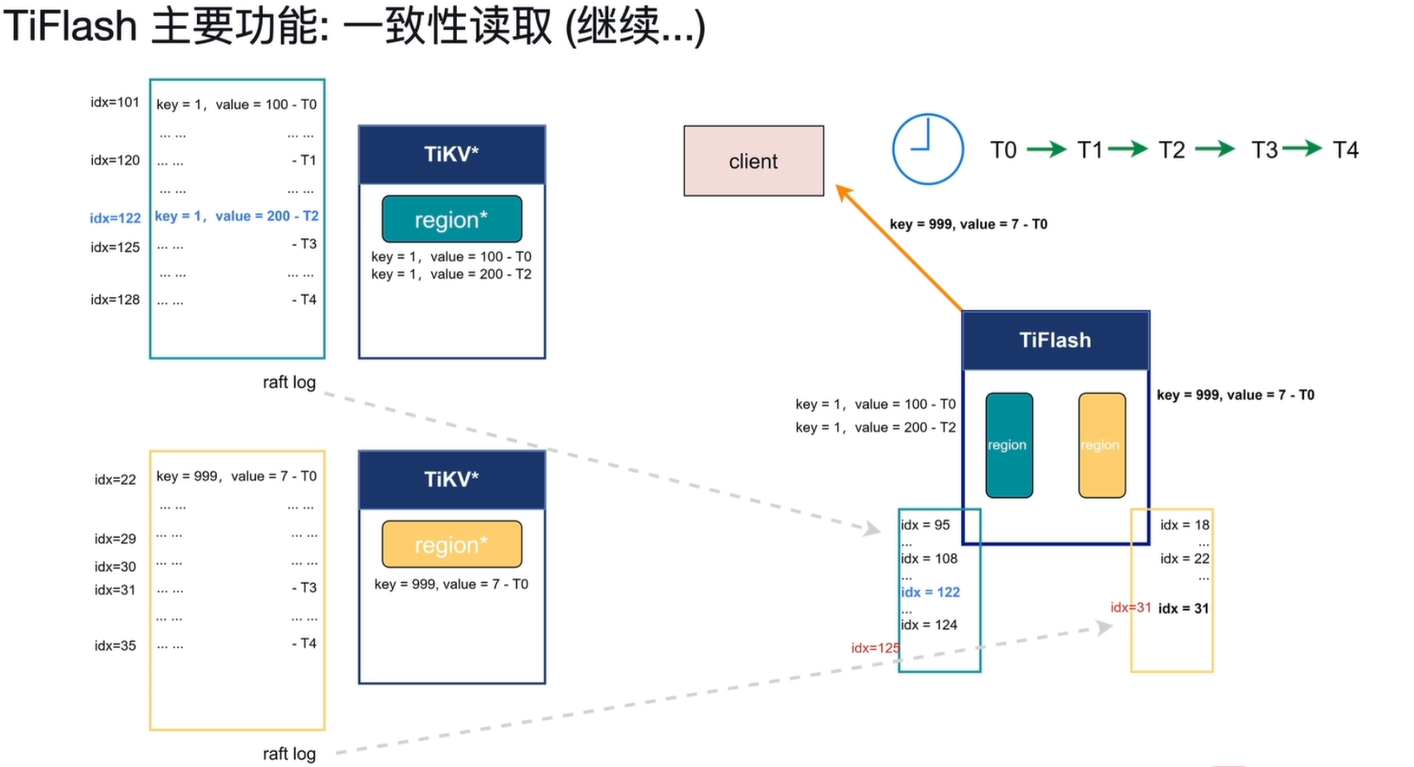
- TiFlash 黄色区域对应 Region 同步进度抵达
idx=31 - 满足读取条件,此时可正常读取到
key=999对应数值 7
- T5 时刻全部同步完成 + 快照隔离读取:
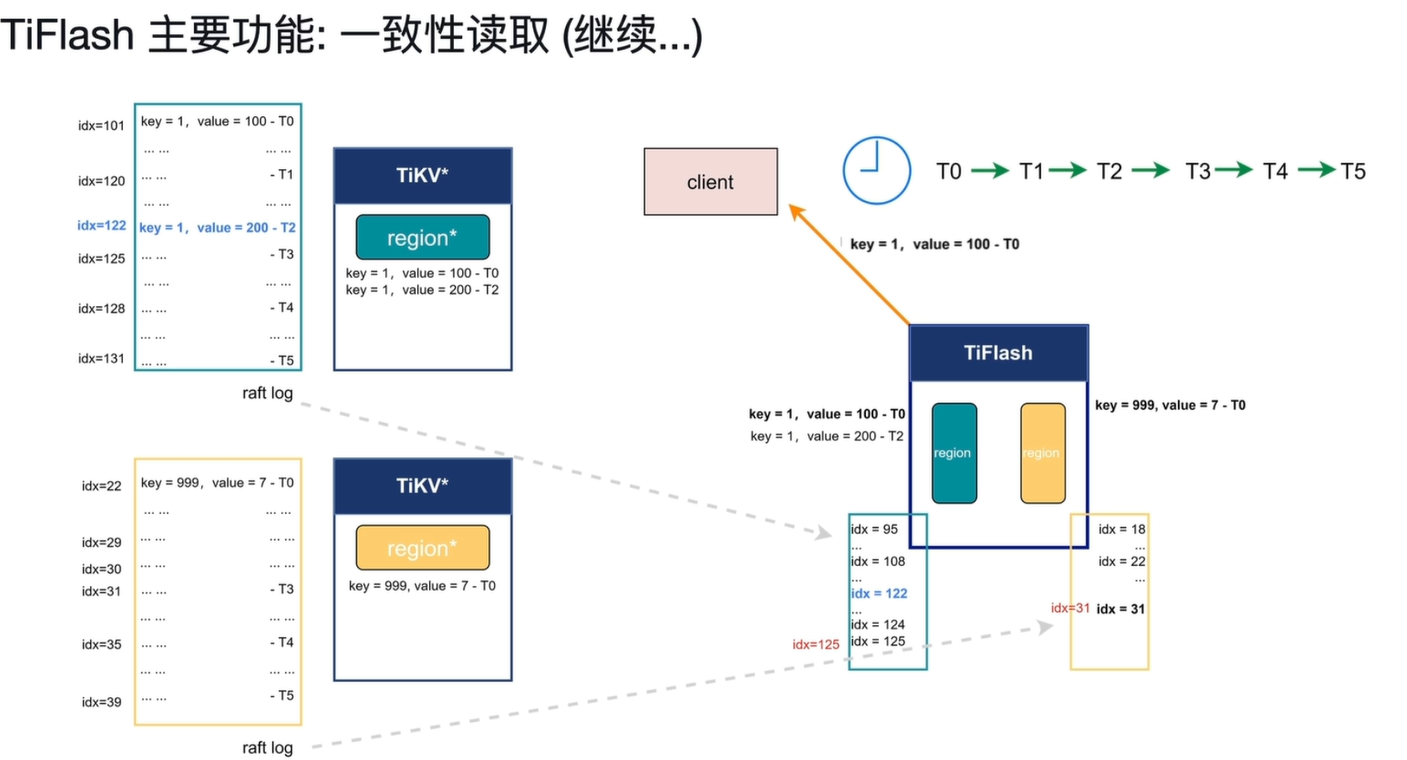
-
TiFlash 绿色 Region 同步进度抵达
idx=125,所有 Region 均满足等待索引要求读取 key=1时发现存在两个数据版本:
- 版本 1:
idx=101→value=100(T0 时刻写入) - 版本 2:
idx=122→value=200(T2 时刻写入)
- 版本 1:
-
按照快照隔离级别:查询请求在 T1 时刻发起,只能读取 T1 时刻之前已提交的数据
-
最终读取结果:
key=1 = 100,key=999 = 7,与 T1 时刻快照完全一致
2.4.2 关键价值
- 消除脏读风险:以主库实时索引为参照标准,保证查询数据与 TiKV 完全一致
- 轻量无损查询:索引问询操作开销极小,不会拖累在线事务性能
- 快照隔离保证:查询结果由请求时刻快照决定,不受后续写入干扰,实现可重复读
- 平衡一致性与性能:异步同步搭配索引等待机制,兼顾查询准确与业务吞吐
2.4.3 TiFlash 其他核心功能
-
引擎智能选择:TiDB 优化器自动区分事务、分析语句,分别路由至 TiKV、TiFlash
-
计算加速:依托列式存储与 MPP 并行计算,大幅提升聚合、关联类分析查询速度
-
2.5 TiFlash核心功能:引擎智能选择
TiDB 优化器会根据 SQL 语句的类型、数据分布和成本估算,自动选择最优的执行引擎(TiKV / TiFlash),无需人工干预,实现事务与分析负载的透明分流。
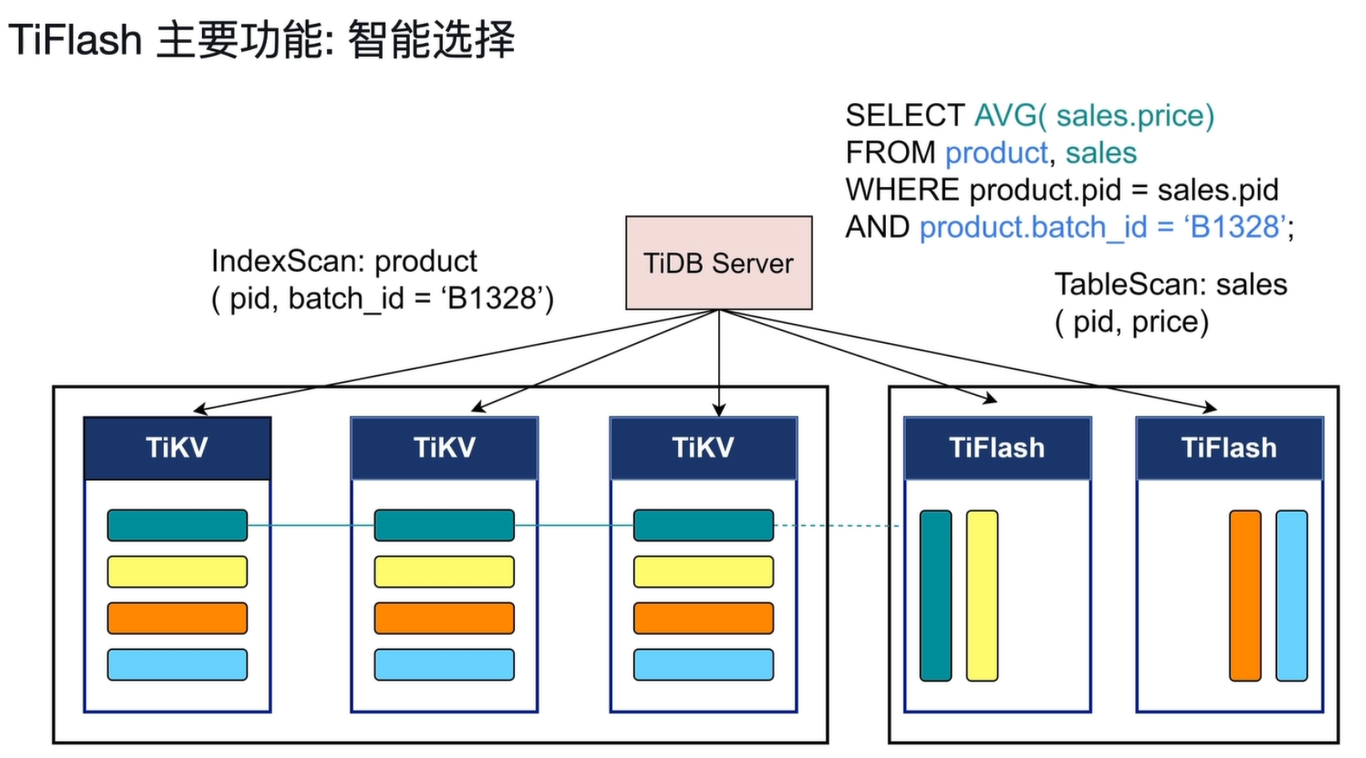
2.3.1 示例场景说明
以图中这条 SQL 为例:
SELECT AVG(sales.price)
FROM product, sales
WHERE product.pid = sales.pid
AND product.batch_id = 'B1328';
2.3.2 智能选择的执行逻辑
-
product 表:在 TiKV 上做索引扫描(IndexScan)
- 条件
product.batch_id = 'B1328'是高选择性过滤,适合用索引快速定位少量符合条件的pid。 - TiDB 优化器选择在 TiKV 上执行
IndexScan,高效过滤出目标数据,避免全表扫描的开销。
- 条件
-
sales 表:在 TiFlash 上做全表扫描(TableScan)
- 目标是计算
AVG(sales.price),属于典型的分析型聚合操作,数据量大、访问列少。 - TiDB 优化器选择在 TiFlash 上执行
TableScan,利用列存的优势,只读取pid和price两列,大幅减少 I/O,同时利用 MPP 并行计算加速聚合。
- 目标是计算
-
Join 与结果聚合
- 从 TiKV 取出的
pid列表,与 TiFlash 中读取的sales数据进行 Join,最终在 TiFlash 上完成AVG()计算。 - 整个过程对用户透明,应用侧只看到一条 SQL,优化器自动选择了最合适的引擎组合。
- 从 TiKV 取出的
2.3.3 核心价值
- 透明的负载分流:事务型操作在 TiKV 执行,分析型操作在 TiFlash 执行,互不干扰,保障在线业务稳定。
- 性能最大化:针对不同表、不同操作,选择最优的执行引擎,发挥行存和列存各自的优势。
- 简化开发运维:无需手动指定引擎或分库分表,单条 SQL 即可同时处理事务与分析逻辑,大幅降低架构复杂度。