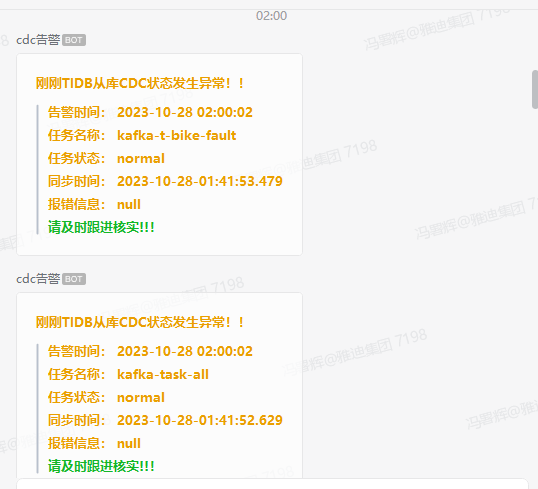
凌晨企业微信群cdc监控告警
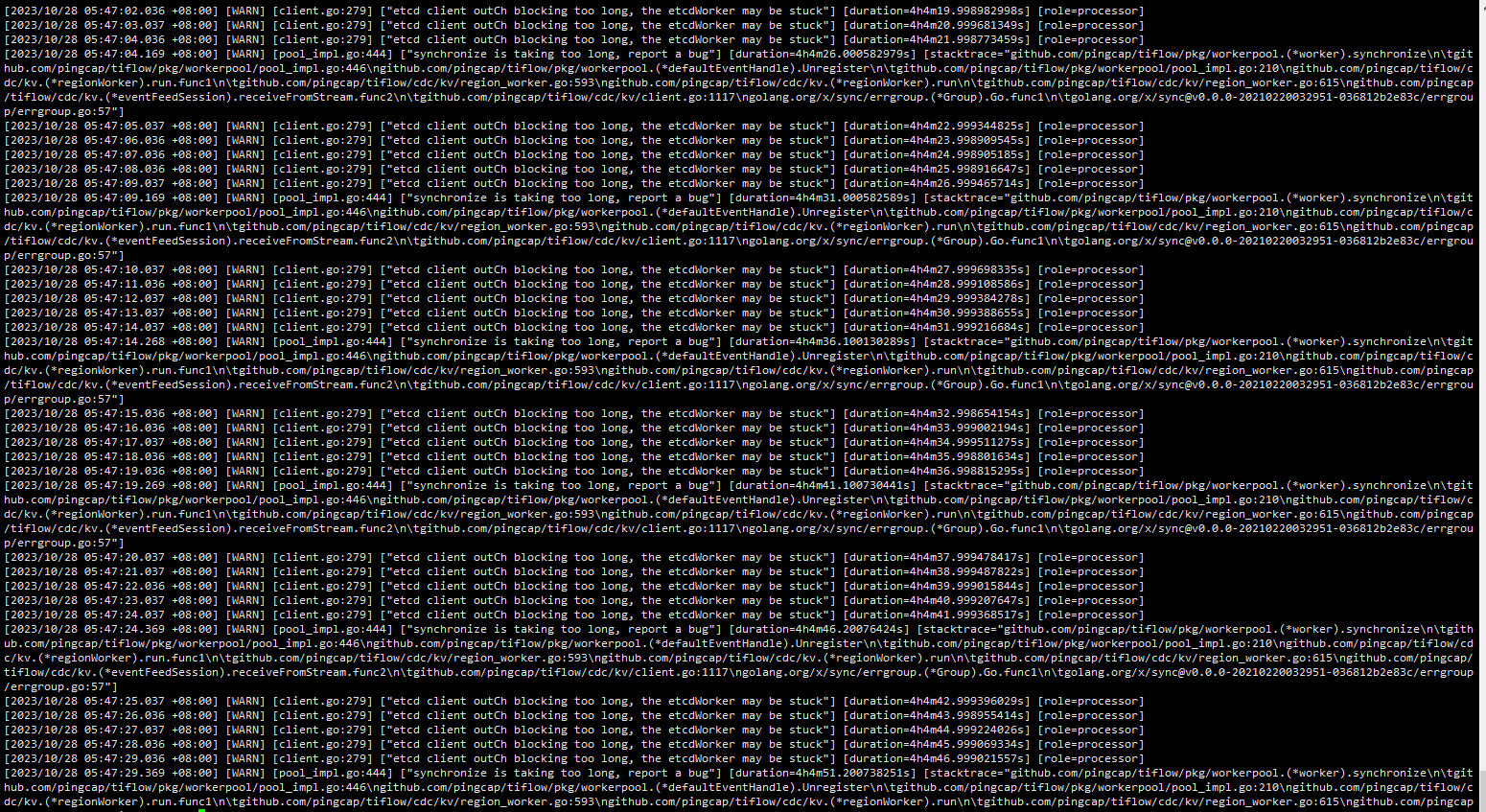
查看cdc日志,有如下warn
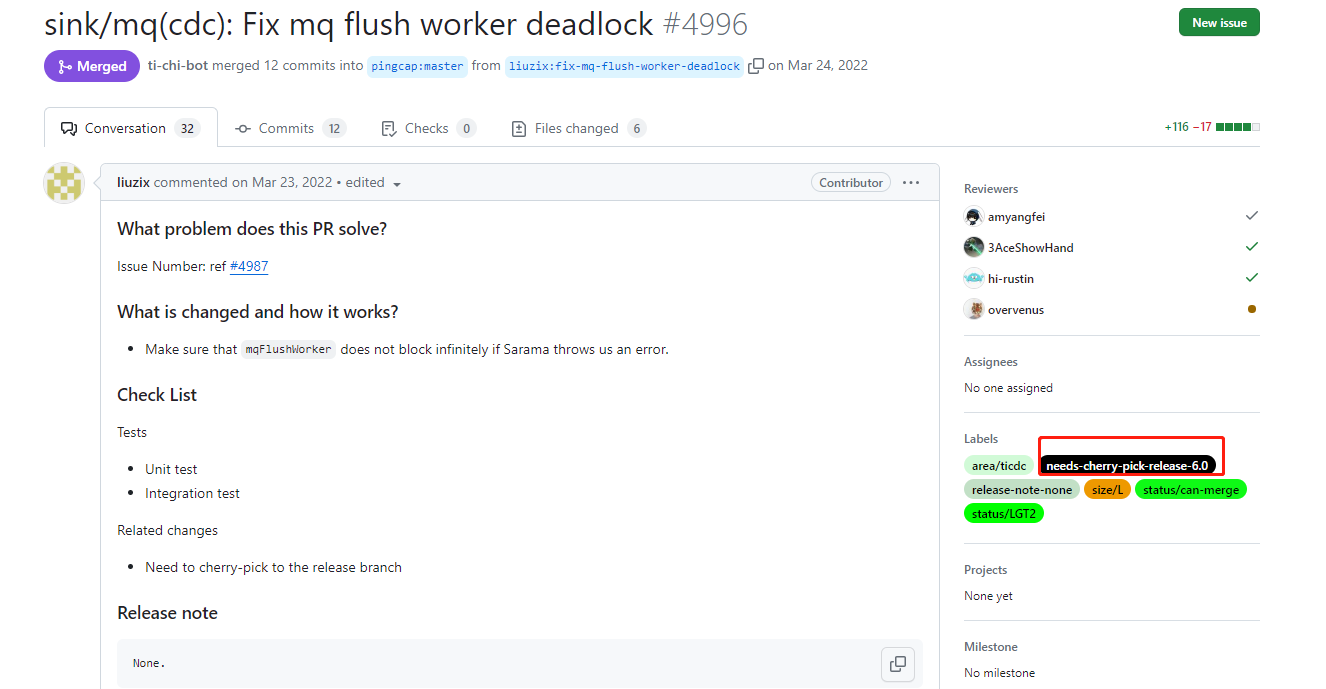
在论坛搜索后发现是已知bug
已打开 09:26AM - 22 Mar 22 UTC
已关闭 06:13AM - 24 Mar 22 UTC
type/bug
severity/major
found/automation
area/ticdc
affects-6.0
### What did you do?
1. create a changefeed with kafka sink
2. stop the chan… gfeed
3. prepare `go-tpc` workload
4. resume the changefeed
5. run `go-tpc` workload
periodically use `kill -s STOP` to pause the Kafka process for around 40 ~ 50s, each a few minutes.
### What did you expect to see?
The whole CDC works properly.
### What did you see instead?
Processor gets blocked for a long time.
When the problem happen, kafka process is healthy, resumed by `kill -s CONT`
```
[2022/03/22 14:00:30.348 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=23.000155792s] [role=processor]
[2022/03/22 14:00:31.348 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=23.9999115s] [role=processor]
[2022/03/22 14:00:32.348 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=24.9999985s] [role=processor]
[2022/03/22 14:00:33.349 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=26.000115375s] [role=processor]
[2022/03/22 14:00:34.349 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=27.000068583s] [role=processor]
[2022/03/22 14:00:35.349 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=28.000139292s] [role=processor]
[2022/03/22 14:00:36.348 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=28.999832417s] [role=processor]
[2022/03/22 14:00:37.349 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=29.99986875s] [role=processor]
[2022/03/22 14:00:38.349 +08:00] [WARN] [client.go:263] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=30.999821875s] [role=processor]
```
### Versions of the cluster
Upstream TiDB cluster version (execute `SELECT tidb_version();` in a MySQL client):
```console
master
```
Upstream TiKV version (execute `tikv-server --version`):
```console
master
```
TiCDC version (execute `cdc version`):
```console
master
```
[etcd_worker.log](https://github.com/pingcap/tiflow/files/8322983/etcd_worker.log)
[goroutine2.txt](https://github.com/pingcap/tiflow/files/8322990/goroutine2.txt)
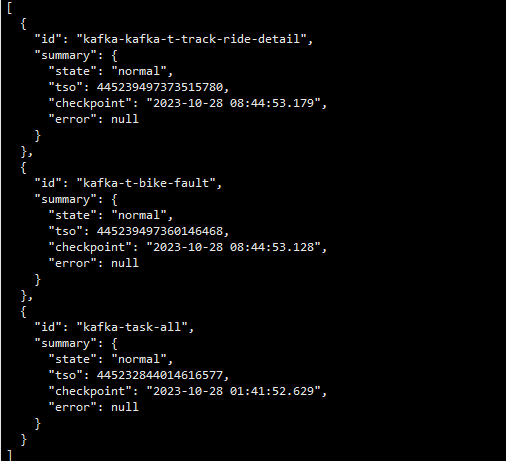
操作:重启cdc故障节点后任务恢复正常。
三个cdc节点,就一个节点出故障,三个任务卡死了一个任务,重启故障节点就好了
1 个赞
你看这个帖子6.5.2还有,6.5版本可是今年新出的版本
ticdc 无法同步,未显示error信息,日志告警如下:
[2023/08/03 17:29:00.180 +08:00] [WARN] [client.go:259] ["etcd client outCh blocking too long, the etcdWorker may be stuck"] [duration=10.599113445s] [role=processor]
[2…
下游kafka不出故障不会触发这个bug,触发了就重启。
system
2023 年12 月 28 日 14:02
14
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。