数据坏了
其它组件都是正常的up啊
![]() 直接拷贝物理文件?这样可不行吧,还是要按标准升级流程来,如果要更换服务器,采用扩容缩容的方式,直接拷贝底层文件,大概率是不行的
直接拷贝物理文件?这样可不行吧,还是要按标准升级流程来,如果要更换服务器,采用扩容缩容的方式,直接拷贝底层文件,大概率是不行的
1 个赞
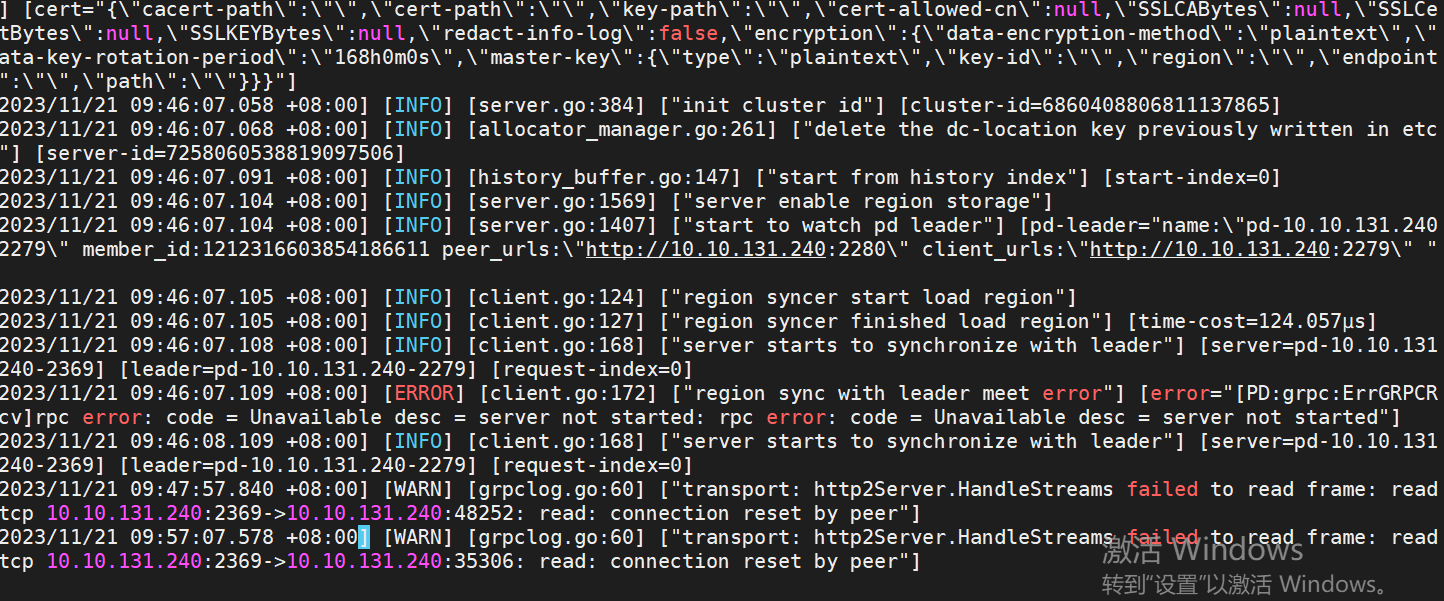
我真感觉和数据格式关系不大,因为从报错上看,就是pdRPC超时了,超过 40s了。
pd上有什么日志吗?
4版本的数据拷到另一个4版本的集群可以恢复吗?这个应该不支持把,不然没有安全性了
pdRPC BACKOFF了,看看PD节点的日志啊?
直接拷贝底层文件,绕过了正规的操作流程,出现未知问题也不奇怪。
只能说这些野路子,对判断问题有帮助,对解决问题没帮助。
PD节点不同步?TSO有问题?
你选的这个不是pd leader。超时和这个应该关系不大。看端口号2279下面有什么日志。
connection reset by peer
这个错误一般是pd在读取这个连接的时候,这个连接被调用pd的一方给关闭了。
不应该这么频繁,要么是防火墙有什么设置,要么就是连接数用尽了。
试试直接
curl http://10.10.131.240:2359/metrics
能访问吗?
访问没问题
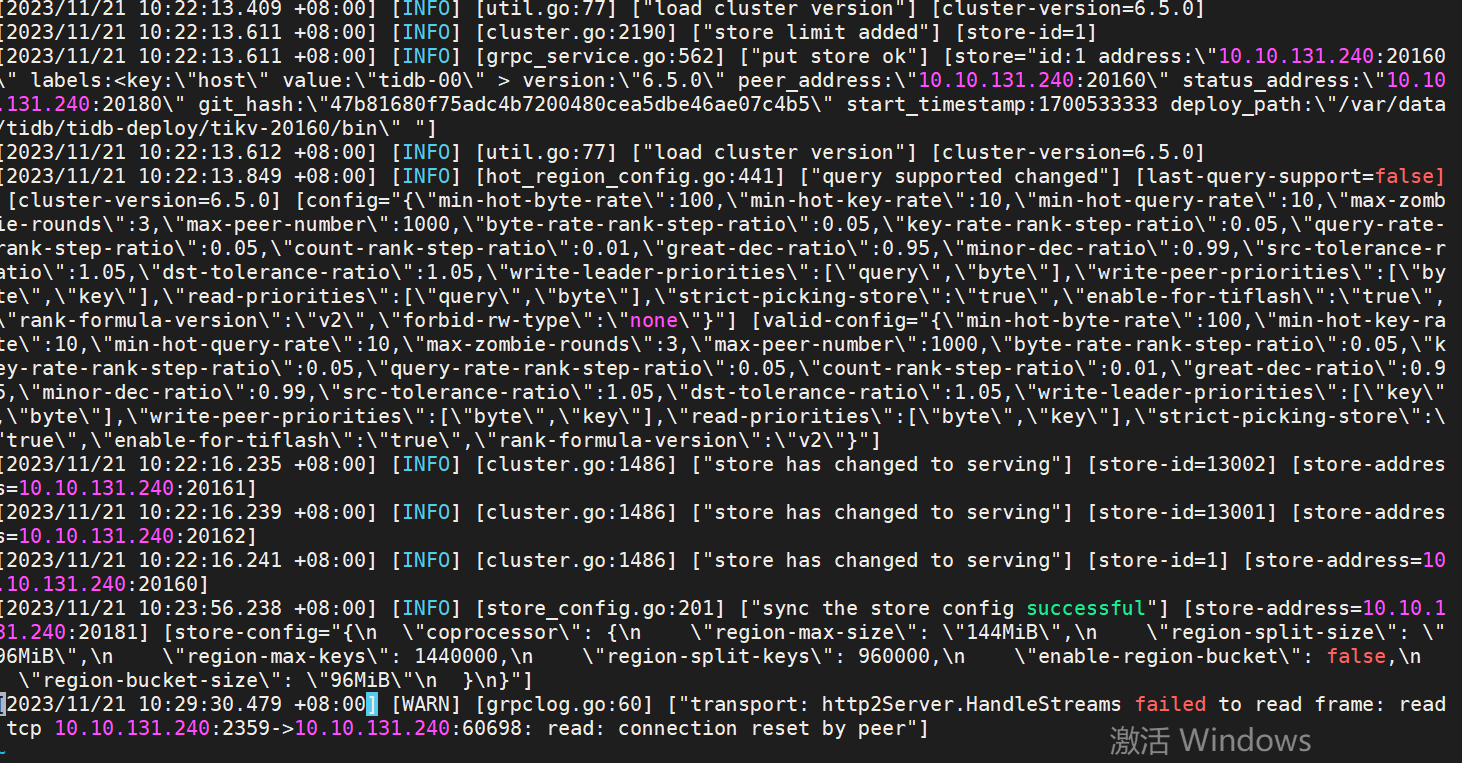
端口2359是leader,端口60698是啥?
完全没思路了。不知道怎么回事。 ![]()
不清楚,这是什么端口
pd.log (33.0 KB)
把其它2个pd都缩容了,只剩一个pd,这是完整的日志
可不可以跳过tidb,读取tikv的数据
可以,昨天还有共享过一个工具。
2 个赞
netstat -tuln |grep端口号或者lsof -i :端口号看下是哪个模块的服务?