建表时需要对时间collection_start_time字段做分区,希望首先按照天再按照小时分区,请问分区语句怎么写呀
在 TiDB 中,可以使用分区表来按照天再按照小时进行分区。下面是一个示例,演示如何创建一个按照天再按照小时分区的表:
首先,创建一个普通的表,定义需要的列和数据类型:
CREATE TABLE my_table (
id INT,
name VARCHAR(50),
created_at DATETIME
);
接下来,使用 ALTER TABLE 语句将表转换为分区表,并按照天再按照小时进行分区:
ALTER TABLE my_table
PARTITION BY RANGE(TO_DAYS(created_at) * 24 + HOUR(created_at)) (
PARTITION p20220101 VALUES LESS THAN (TO_DAYS('2022-01-01') * 24),
PARTITION p20220102 VALUES LESS THAN (TO_DAYS('2022-01-02') * 24),
PARTITION p20220103 VALUES LESS THAN (TO_DAYS('2022-01-03') * 24),
...
);
在上述示例中,我们使用 TO_DAYS(created_at) * 24 + HOUR(created_at) 来计算分区的值,将日期和小时转换为整数值。然后,使用 PARTITION BY RANGE 子句指定按照这个整数值进行分区。
根据需要,您可以根据实际情况定义更多的分区,每个分区对应不同的日期和小时范围。
请注意,分区表的创建和管理需要一些额外的注意事项,例如分区维护和查询优化。建议在使用分区表之前详细阅读 TiDB 的官方文档,了解更多关于分区表的信息和最佳实践。
https://docs.pingcap.com/zh/tidb/stable/partitioned-table#分区选择
参考下!
1 个赞
楼主的意思应该是使用多级分区,先range天,再rang小时
一年的时间,PARTITION p20220103 VALUES LESS THAN (TO_DAYS(‘2022-01-03’) * 24),这个岂不是要写365行 ![]()
上面的方法,随着时间变更,表结构估计得一直改。不是想要的呢 ![]()
你应该想要的是类似于oracle interval分区,插入数据自动添加对应分区
对,可以提供个sql模版吗
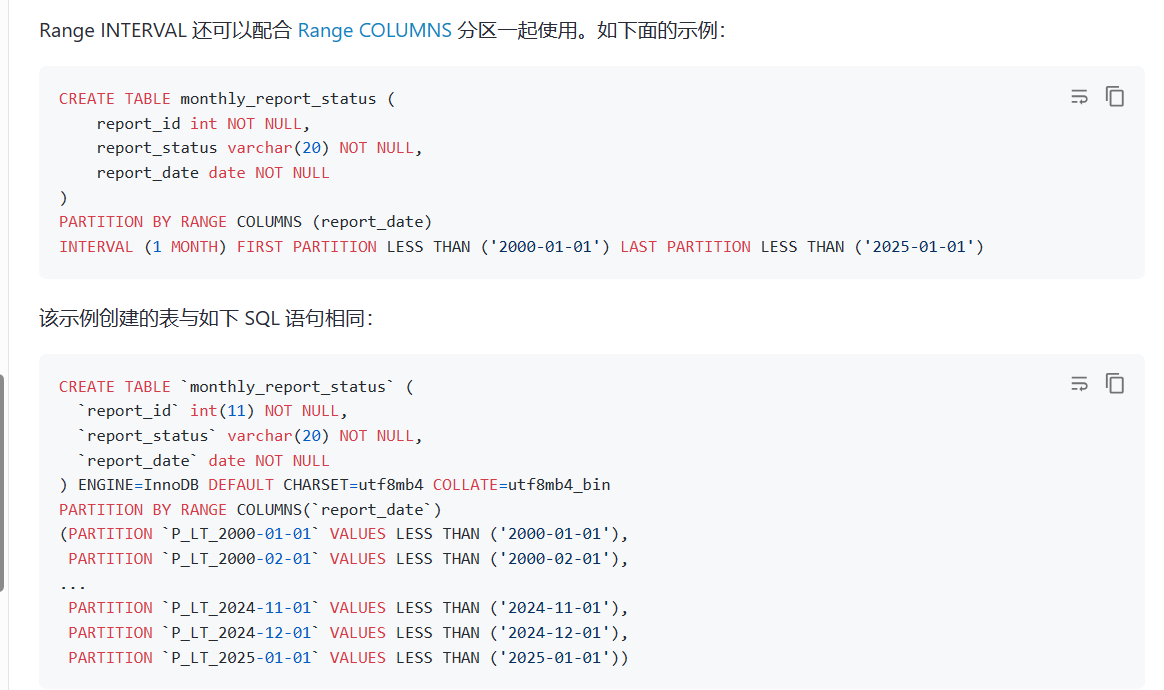
1 个赞
用的哪个AI?
你应该是想找数据库自动生成的那种,估计够呛,MYSQL版本的好像不支持
只能采用这种折中的方式处理了,想支持这种复杂的分区,目前只有 OLAP 引擎的可以
我觉得他想要的是分区(天)和子分区(小时)
就是不知道是否和ORACLE一样支持子分区
貌似tidb没有子分区吧,你这需求满足不了,看你的需求有点特殊,是否是时序数据?
对,数据是随着时间一直推移的
建议你调研下时序数据库

记得创建数据库时候使用utc时区,时区有个坑,使用北京时区有8个小时的数据查不出来
现在一个表最多也就8192个分区,你这一个小时一个分区的话,8192连1年都不够放的吧,1年就得8760个分区了。。。
https://docs.pingcap.com/zh/tidb/v6.5/tidb-limitations#单个-table-的限制
2 个赞
这得建多少分区啊
一个分区数据在500w左右其实性能还可以的