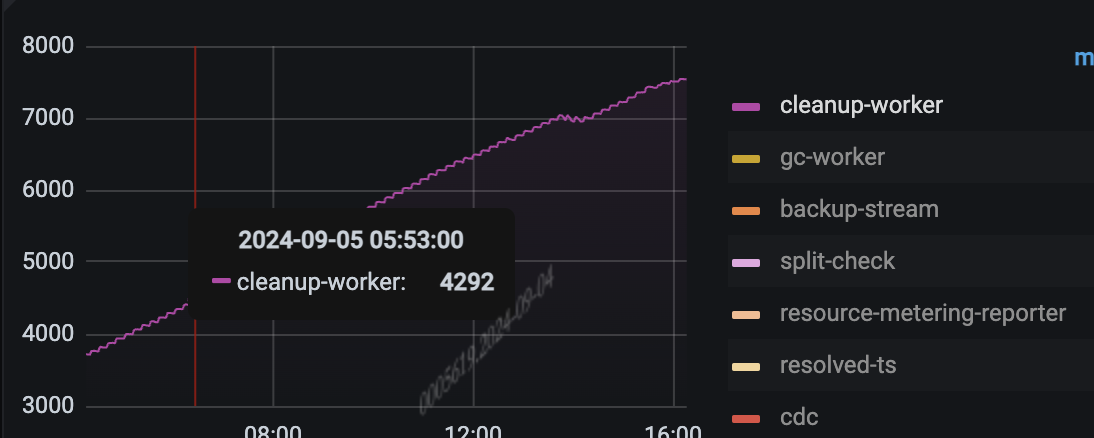
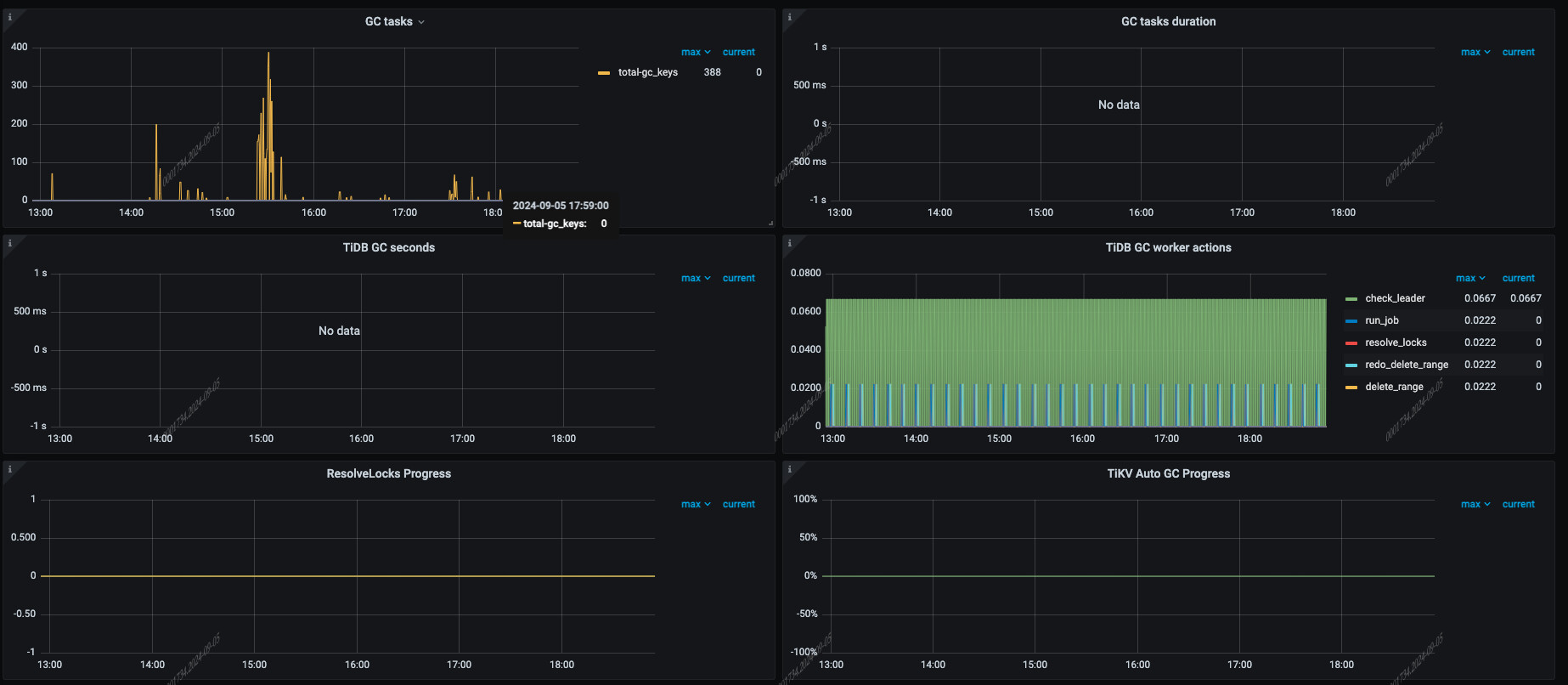
集群目前看其他指标都挺正常的,使用起来也没发现什么问题,但就是这个pending变得越来越多
GC 延迟高不高,这个延迟高的话也会导致 cleanup-worker 堆积待处理任务;
另外看看日志里,有没有cleanup-worker 相关的错误或警告信息
cleanup-worker是负责清理过期数据的后台线程,如果这个指标一直居高不下,可能意味着有大量的过期数据需要清理,或者清理工作遇到了瓶颈。
以下是一些降低cleanup-worker负载的参数和方法:
1、调整GC配置:增加gc-worker-count参数的值来增加GC工作线程的数量,或者调整gc-ttl参数来减少需要清理的数据量。
2、调整scheduler-worker-pool-size:如果scheduler-worker-pool-size设置得过低,可能会导致写入操作积压,从而增加cleanup-worker的负担。适当增加这个参数的值可以提高写入处理能力。
3、手动Compaction:如果自动GC工作不足以及时清理数据,可以考虑使用tikv-ctl工具进行手动Compaction,强制 RocksDB 进行Compaction,从而清理过期数据。
4、监控TiKV的GC相关指标,如gc_keys_duration和gc_tasks_duration,以及RocksDB的Compaction相关指标,如rocksdb_compaction_duration。
kevinsna
(Ti D Ber P O Zcnp Ja)
7
在TiKV中,cleanup-worker 是负责清理过期数据和无用数据的组件。如果监控到cleanup-worker 的pending tasks 数量持续居高不下,这通常意味着有大量的清理任务等待执行。 可以对TiKV 集群进行手动 compaction:tikv-ctl --pd 127.0.0.1:2379 compact-cluster -b -c default,lock,write。要在业务低峰期操作
Hello, cleanup-worker 任务堆积,应该是遇到了以下问题:
当前 TiKV 的 cleanup_worker 为单线程模型,主要负责处理两类任务:
-
Compact 任务
由 split-checker 发起。不检查 region 是否真正符合 compaction 条件。直接向 RocksDB 发起 CompactRange 请求并同步等待返回。执行成本较高。
-
CheckAndCompact 任务
每次检查 100 个 Region:如果符合条件,则向 RocksDB 发起 CompactRange 操作并等待返回。
默认每 5 分钟执行一次。
核心问题
问题一:cleanup_worker 无法并发执行 compaction
由于 cleanup_worker 是单线程模型:
- 所有 compact 请求只能 串行执行
- 无法并发向 RocksDB 发起 compact 任务
- 无法充分利用系统 CPU 和 IO 资源
- RocksDB compaction 资源利用率较低
表现为:
- RocksDB compaction CPU 使用率无法提升
- 每次只存在一个 manual compaction 任务
问题二:大量 Region 导致 CheckAndCompact 无法跟上
当需要 compaction 的 Region 数量非常多时:
1)CheckAndCompact 扫描效率严重不足
- 每 5 分钟只检查 100 个 Region
- 如果集群存在大量 Region:
2)CheckAndCompact 无法按周期完成
当 cleanup_worker 处理速度不足时:
- 一个周期内的 CheckAndCompact 任务无法完成
- 新任务继续进入队列
- 导致 cleanup_worker 队列堆积
问题三:Split-checker 产生大量重复 Compact 任务
由于部分 Region MVCC 版本堆积严重,会形成较大的 Region:
1)Split-checker 检测到大 Region 后:
- 向 cleanup_worker 提交 Compact 任务
2)Compact 任务需要排队执行:
3)Split-checker 每 10 秒触发一次:
- 会重复提交相同 Region 的 Compact 任务
4)导致 cleanup_worker 队列中:
- 同一个 Region 的 Compact 任务大量堆积
。。。
具体可以见 issue 描述。
最终上诉问题会导致:
最终导致:
- cleanup_worker 队列长期堆积
- MVCC 版本堆积
- Region 无法 split
- 冗余相同 compaction 循环发生
处理办法:找到 TiKV 中报 failed to handle split req 相关日志里面的 region-id, 对其进行手动 compact 后,重启 TiKV 节点,观察 cleanup-worker 的 pending task 是否继续上涨。