Tidb监控显示IO有延迟,请问如何解决?这个是什么原因引起的呢?
从图中看到红色的梯形的图,显示有IO延迟。
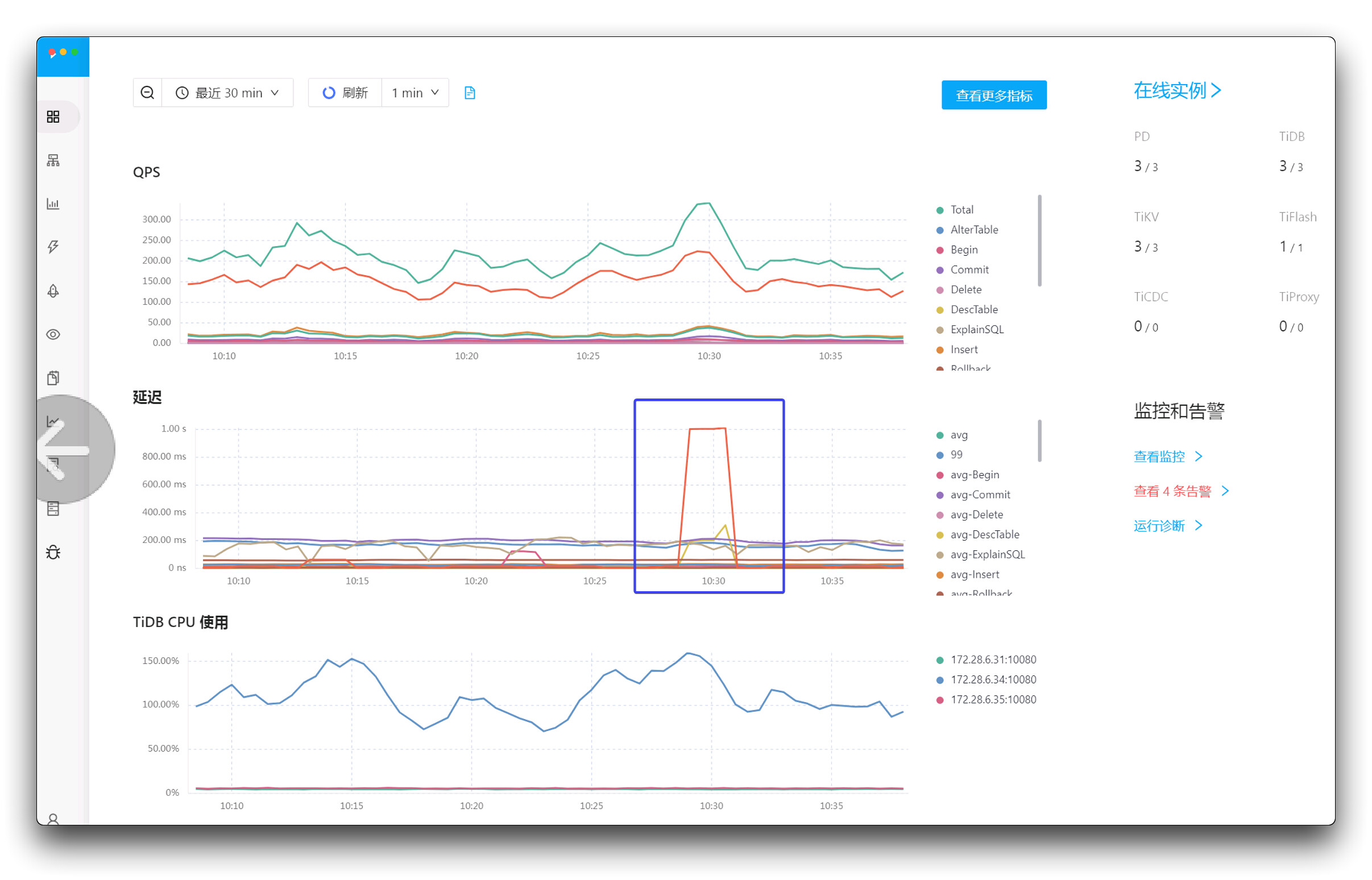
这个说明你有慢sql
1 个赞
看慢查询,这是时间段的 这个黄色是insert吧
1 个赞
通过 grafana 查下这个时间的监控指标,对比下看看
查看下对应对应时间的监控tidb–> Transaction–>Statement Lock Keys以及tidb–> Transaction–>Acquire Pessimistic Locks Duration看下是否有锁。以及Node-expoter下面的disk里面的write latch是否有延迟。
2 个赞
这个原因太多了阿,你那个几个截图没办法排查
建议从SQL入手排查
- 优化磁盘性能:确保 TiKV 节点使用 SSD 或高性能磁盘,避免磁盘故障或负载过高。
- 增加 TiKV 节点:如果 TiKV 节点负载过高,可以通过扩容 TiKV 节点来分担压力。
- 优化 TiDB 查询负载:减少 TiDB 节点的查询负载,优化 SQL 查询,避免不必要的长时间查询。
- 检查并优化网络:确保集群各节点之间的网络连接稳定,带宽足够。
- 调整 RocksDB 配置:根据 TiKV 的负载情况,优化 RocksDB 存储引擎的配置。
1 个赞
这段时间的慢查要挨个去看分析
同时段QPS也有所增加,可能是有业务进来了。可以看下对应时段的慢SQL,另外也可以看下IO的火焰图,看看对应时刻是否有高IO的对象。
看看这个延迟对应的是什么,有慢语句、添加索引等
这些信息看不出来,建议可以从如下方面排查入手:
磁盘性能瓶颈:检查磁盘IO性能,确保磁盘足够快,建议使用SSD。
TiKV资源瓶颈:增加TiKV节点数或优化TiKV的内存和磁盘配置,确保TiKV节点分担负载。
网络延迟:检查TiDB集群的网络连接,确保低延迟网络。
TiKV配置优化:调整TiKV的 rocksdb 配置,如增加 storage.block-cache-size 或调整 raftstore 配置。
慢查询:优化SQL查询,减少磁盘访问,避免全表扫描。
缓存未命中:增加TiDB或TiKV的缓存配置,提高缓存命中率。
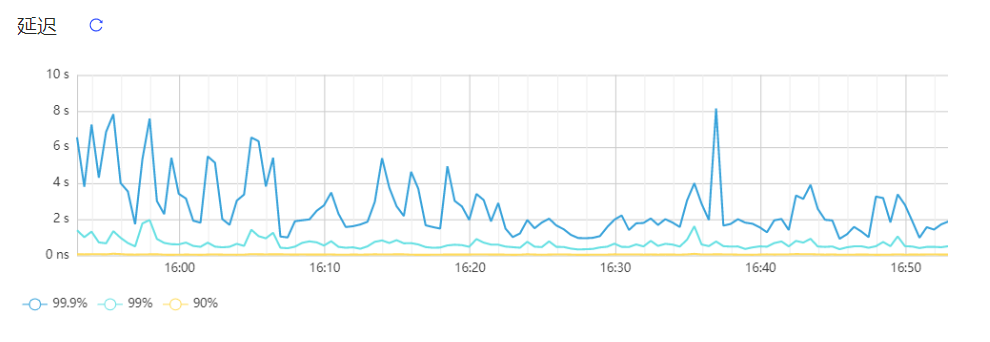
这个不是IO延迟,是sql延迟
你这是,sql的问题的,需要优化sql了
看看能不能定位到SQL,是不是全表扫了
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。