【 TiDB 使用环境】生产环境
【 TiDB 版本】 V7.5.1
tiup dmctl --version
tiup is checking updates for component dmctl …
A new version of dmctl is available:
The latest version: v8.5.1
Local installed version: v8.0.0
Update current component: tiup update dmctl
Update all components: tiup update --all
【复现路径】
【遇到的问题】
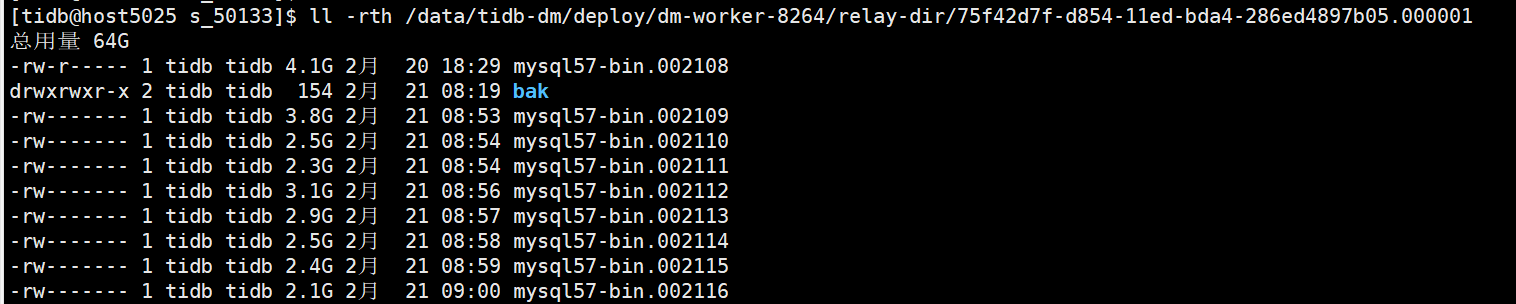
DM同步数据,上游mysql5.7.25 , 未开启GTID,传统binlog pos方式同步 。在同步时出现如下错误:
“errors”: [
{
“ErrCode”: 36001,
“ErrClass”: “sync-unit”,
“ErrScope”: “internal”,
“ErrLevel”: “high”,
“Message”: “panic error: table checkpoint position: (mysql57-bin.002108, 20212127), gtid-set: 00000000-0000-0000-0000-000000000000:0 less than global checkpoint location(position: (mysql57-bin.002108, 31354389), gtid-set: 00000000-0000-0000-0000-000000000000:0) (flushed location(position: (mysql57-bin.002108, 31354389), gtid-set: 00000000-0000-0000-0000-000000000000:0))”,
“RawCause”: “”,
“Workaround”: “”
}
]
做的处置:
在论坛查询该错误先关内容,参考 DM报错 "ErrCode": 36001如何解决? - #3,来自 Hacker_7b2KWuuo 文章。进行了binlog文件核对,发现的确binlog文件超过了4G。 但是 现在的问题是 这个问题该如何解决,如何让同步进行下去。
【资源配置】
【复制黏贴 ERROR 报错的日志】
dm-worker.log (2.4 MB)
【其他附件:截图/日志/监控】