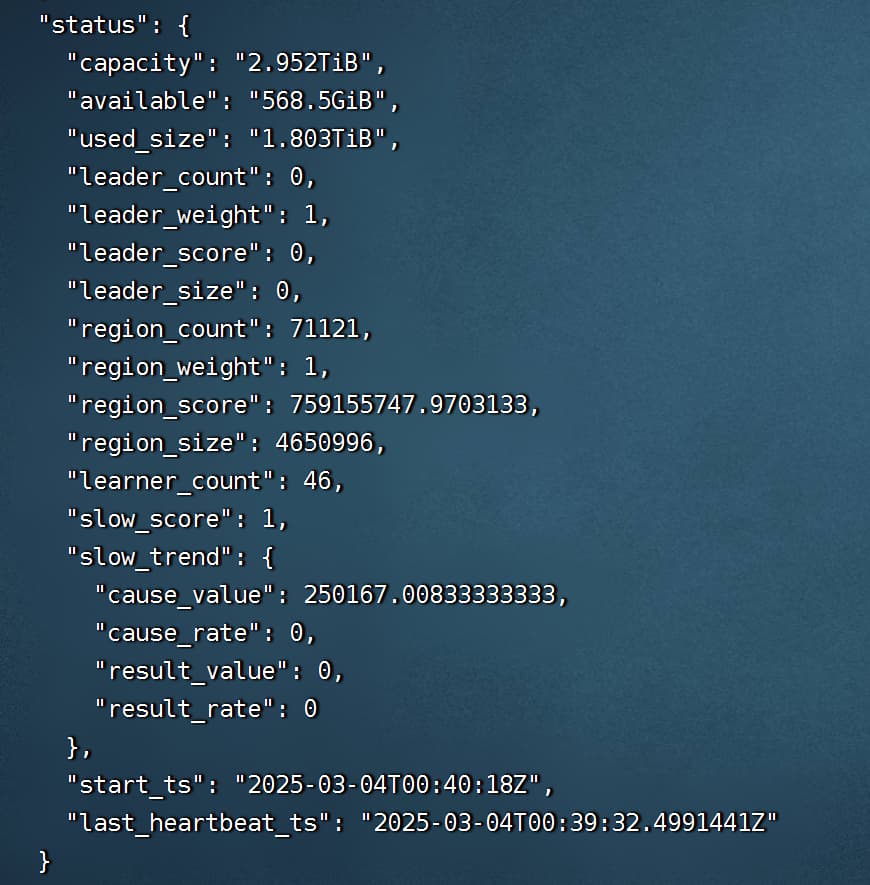
首先我tiup cluster start xxx,后 ,如下图。 (实际上,我们的kv37虚拟机现在由于某些原因无法启动,我没有开机)
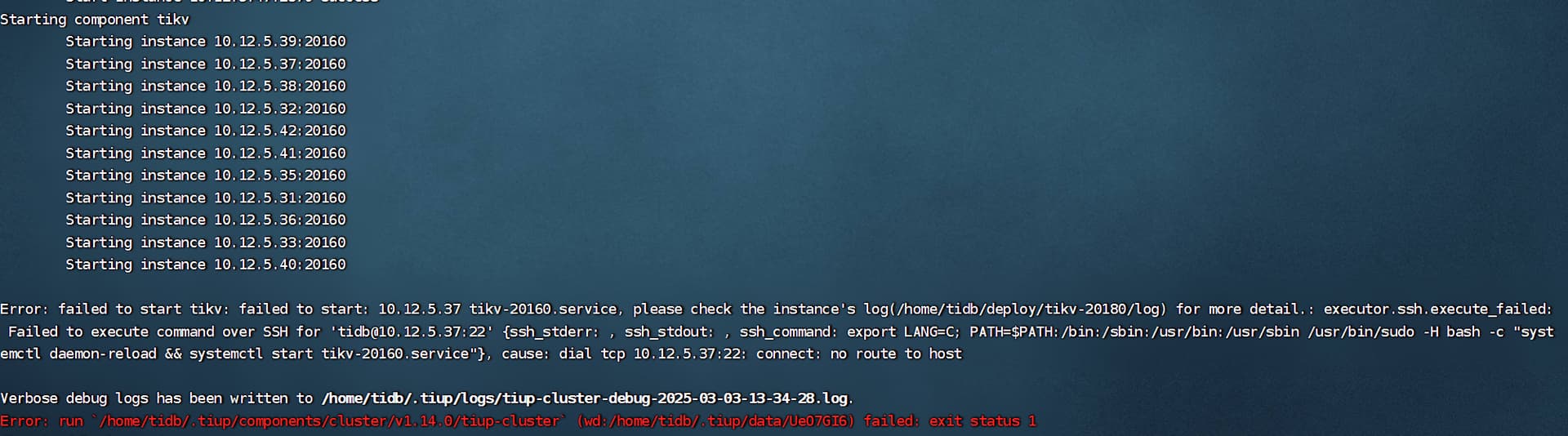
display 如下
然后我单独去启动tidb节点,报4000端口超时。
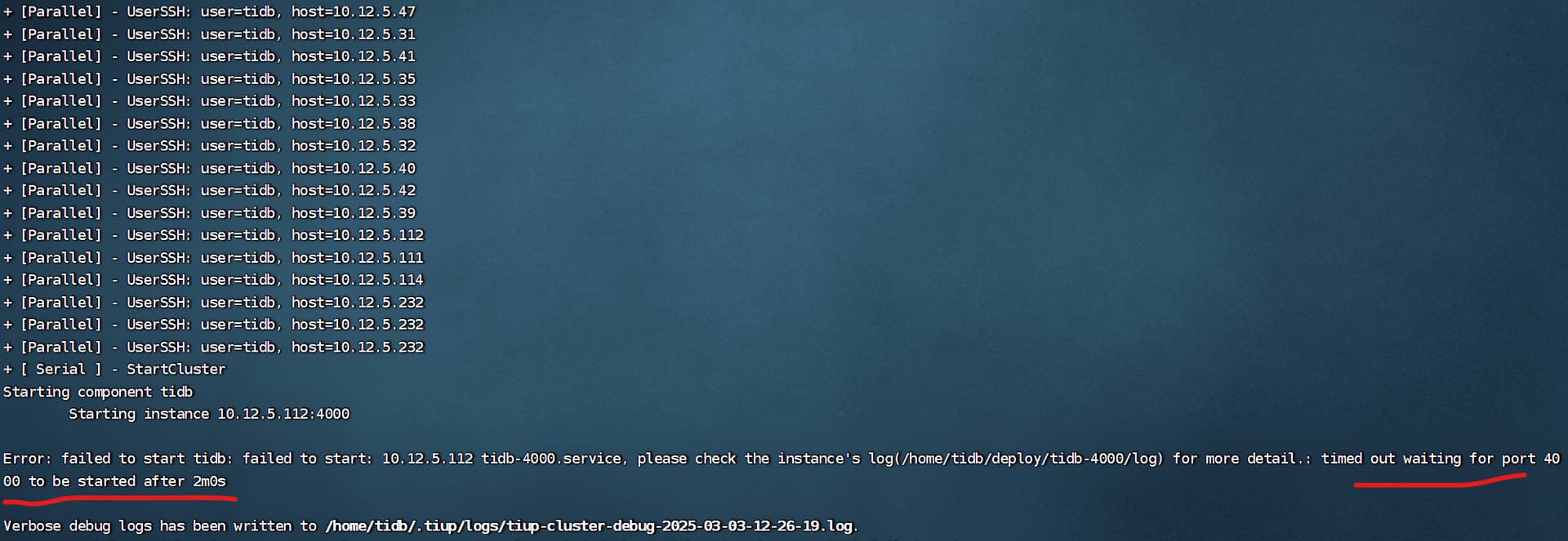
按照提示去找了tidb的log
tidb-server上发现没有最新的log文件。我进入tidb.log查看后,发现今天的log内容如下
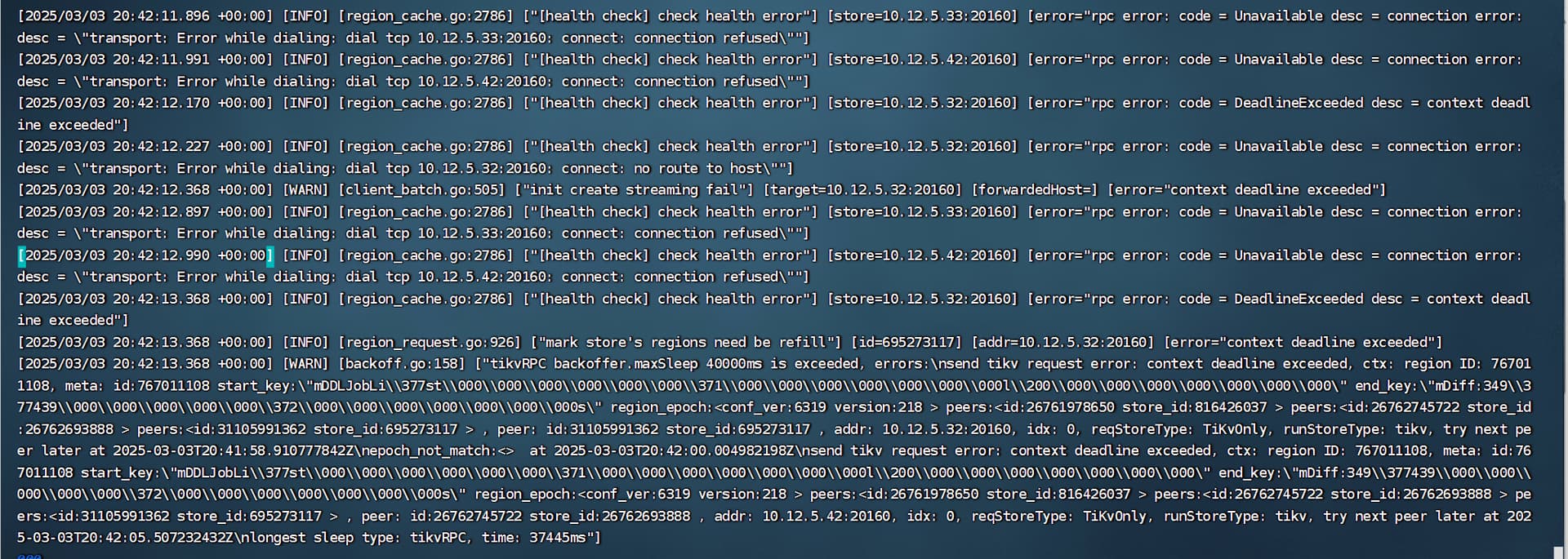
现在整个集群都启动不起来,急急急,求助大神,救救孩子
首先我tiup cluster start xxx,后 ,如下图。 (实际上,我们的kv37虚拟机现在由于某些原因无法启动,我没有开机)
display 如下
tidb-server上发现没有最新的log文件。我进入tidb.log查看后,发现今天的log内容如下
现在整个集群都启动不起来,急急急,求助大神,救救孩子
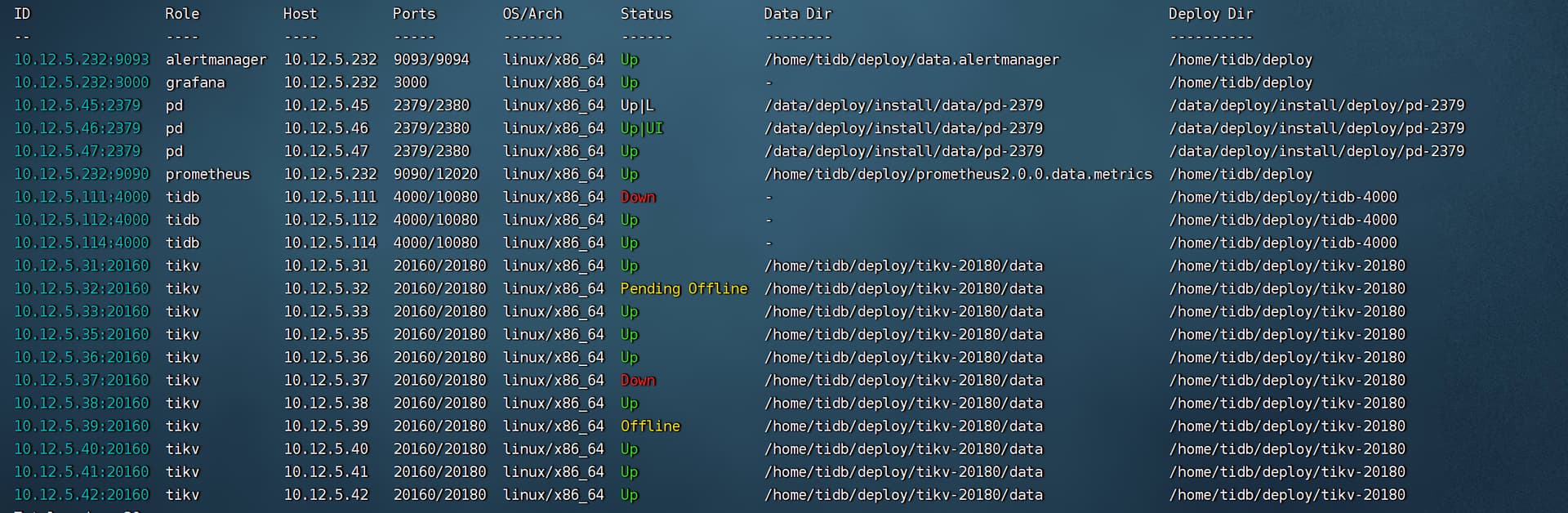
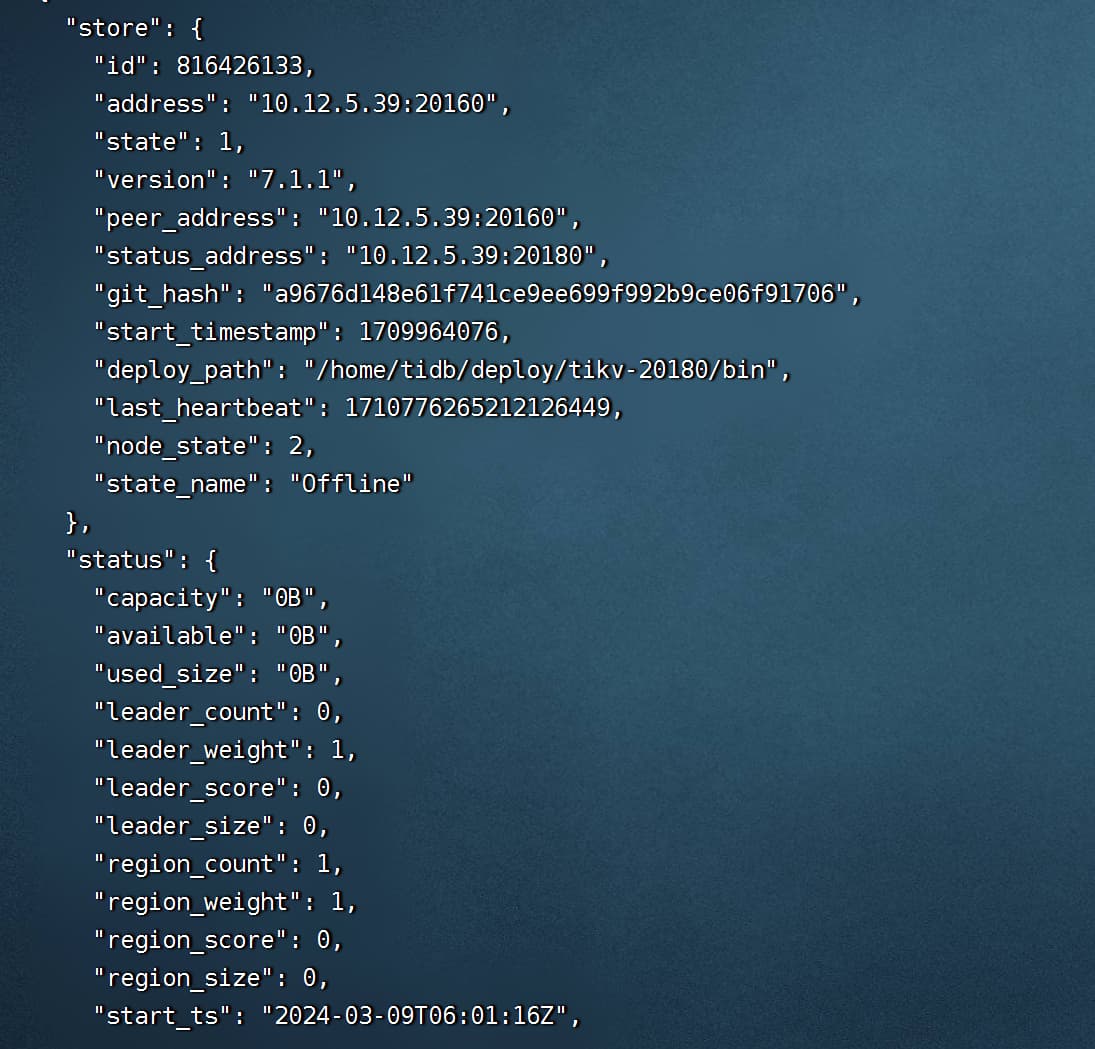
32已经是pending offline了,37还出了问题起不来。
如果是默认3副本的情况下,2个副本都出了问题,是起不来的。
问题应该是出在tikv没起来。tikv上有什么日志嘛?
另外集群的版本也补充一下。
是不是发生过服务器异常重启?kv日志检查下,看看是否磁盘出问题了。
别看tidb-server的日志,tidb集群的启动顺序是pd→tikv→tidb-server,现在你的tikv都起不来,先排查tikv不能启动的原因
好的谢谢,先去排查了tikv,发现磁盘满了清理了下,现在有两个tidb节点可以启动了。
谢谢 ,原因是kv磁盘满了,清理了下现在有两个tidb节点启动了
是的 谢谢!
https://docs.pingcap.com/zh/tidb/stable/tidb-scheduling/#信息收集
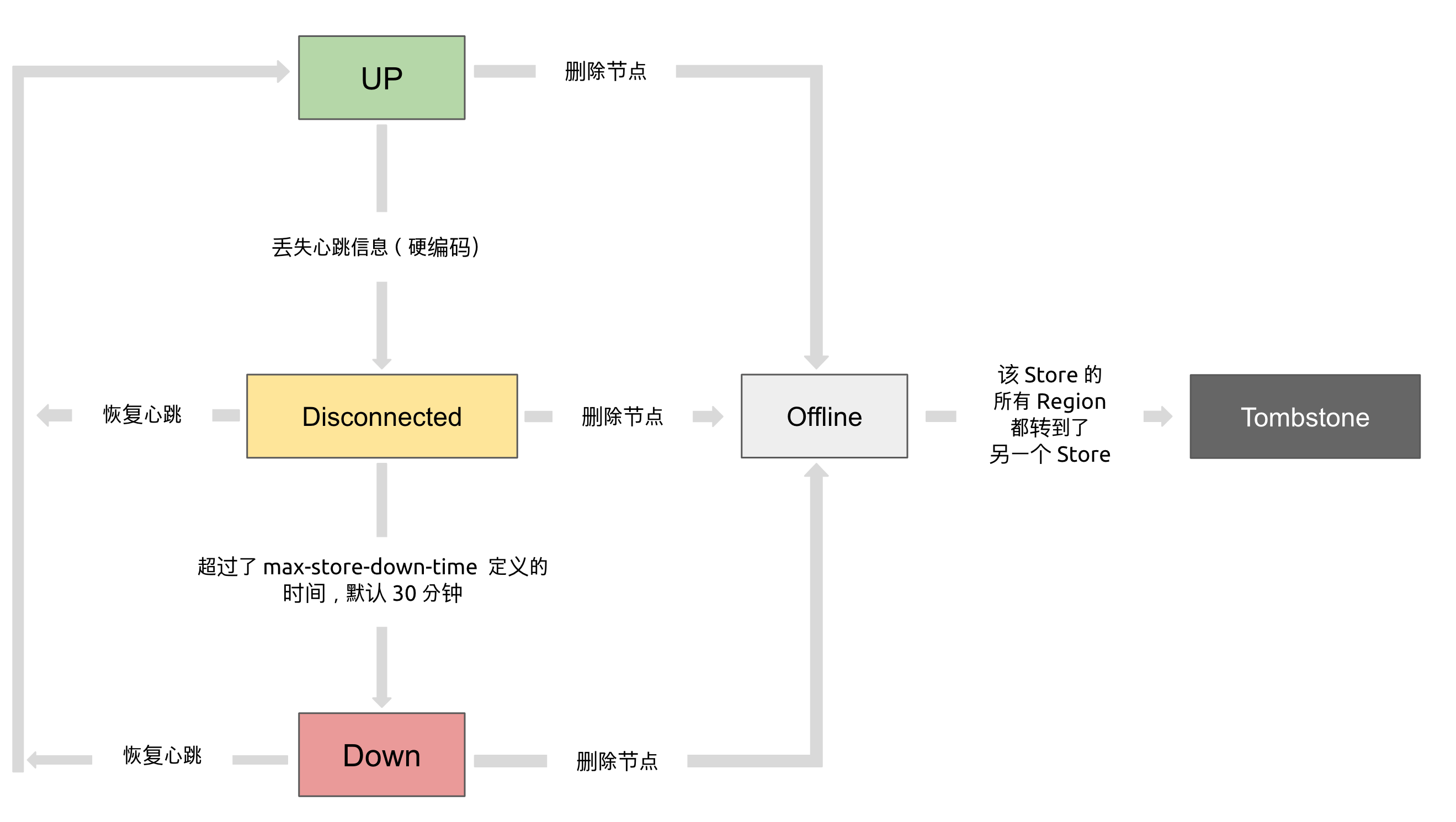
不管是什么状态开始向 offline状态转换。只能等这个转化状态结束,这个下线的过程别tikv会补副本,磁盘一定要够。等转换结束。转换结束到tombstone状态之后,用tiup cluster prune清理,然后再往32上重新扩容。
话说你们这是裁员裁到大动脉了,玩的很惊险啊。
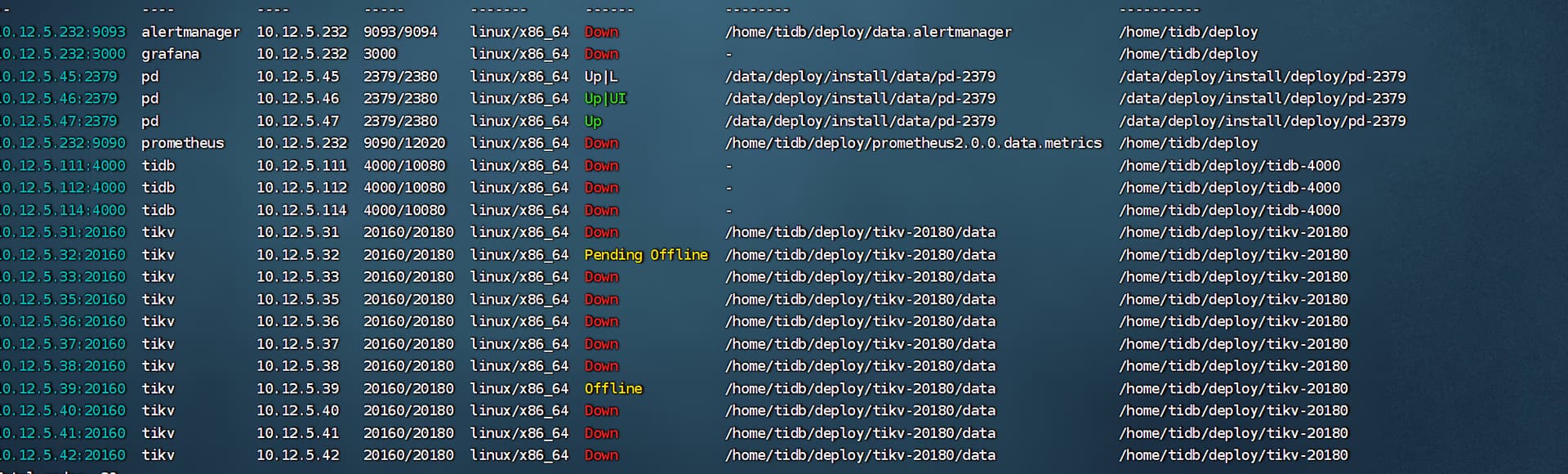
![]() 是啊老哥,懂的都不在了。 能麻烦帮我看下整体的问题吗。下边是整个集群的状态
是啊老哥,懂的都不在了。 能麻烦帮我看下整体的问题吗。下边是整个集群的状态
首先,检查端口冲突。用户提到 4000 端口超时,4000 端口是 tidb-server 的默认端口,所以需要确认这个端口是否被其他进程占用。可以使用 lsof 或者 netstat 命令检查端口使用情况。如果被占用,需要终止相关进程或者修改 tidb 的端口配置。
其次,连接 PD 的问题。虽然 pd 已经启动,但 tidb-server 可能无法连接到 pd 的客户端端口(如 2379)。需要检查网络连通性,确保 tidb-server 所在的机器能够访问 pd 的 IP 和端口。防火墙或安全组设置可能会阻止连接,需要检查 iptables 或者云服务的安全组规则。可以使用 nc 或 curl 测试端口连通性,比如用 nc -vz pd_ip 2379,或者 curl pd 的 API 端点。
接下来,启动参数错误也是一个可能的原因。用户可能在配置文件中写错了参数,比如 pd 的地址格式不正确,或者路径错误。需要检查 tidb 的启动参数,特别是 --path 和 --pd 的配置是否正确,确保没有语法错误或拼写错误。
然后,考虑升级相关的问题。如果集群是在升级过程中出现这个问题,摘要 4 中提到升级时同时启动所有 tidb-server 可能导致 ddl owner 选举失败。这时候需要手动启动一个 tidb-server,等待选举完成后再启动其他节点。检查日志是否有关于 ddl owner 选举的错误信息,比如 “upgrading get owner op failed”。
此外,资源不足也可能导致启动失败,比如内存不足或者文件描述符限制。检查系统资源使用情况,确保有足够的内存和文件句柄。查看 tidb-server 的日志,是否有 OOM(内存不足)的错误提示,或者无法打开文件的错误。
最后,软件版本兼容性问题。如果最近进行了升级,可能存在版本不兼容的情况,比如 tidb-server 和 pd 的版本不一致。需要确认所有组件的版本是否匹配,按照官方文档的升级步骤进行检查。
这个问题已经解决了,您能看下 我给“有猫万事足”的回复里的,最新的问题吗
111这个tidb是down的,这个不是大问题。可以不管。
现在是32 这个pending offline一定不能出问题。要让他能把leader迁走。这个最重要的。一定要保证。
确保其他tikv有足够的空间,能够承接这些迁走的leader,如果现有的tikv的空间已经不足,赶紧加机器,扩容tikv,哪怕磁盘差点。这点至关重要
37已经起不来了,如果32的offline还完不成,那肯定有一部分数据是要丢失的。
那个时候不得不尝试unsafe recovery。
https://docs.pingcap.com/zh/tidb/stable/online-unsafe-recovery/#online-unsafe-recovery-使用文档
现在最首要的问题,是需要对全部tikv节点都做检查,如果出现磁盘空间不够的,先清理一些过期日志紧急释放,然后考虑扩容。
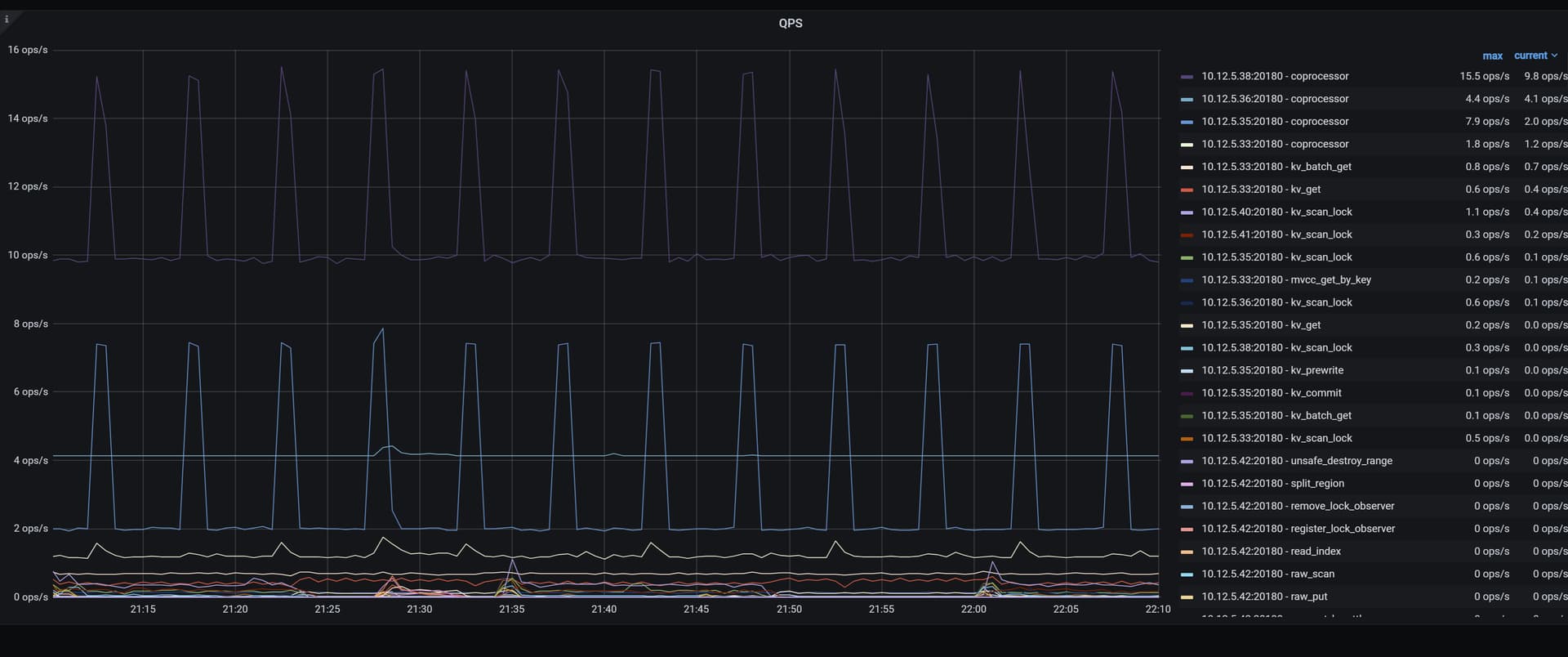
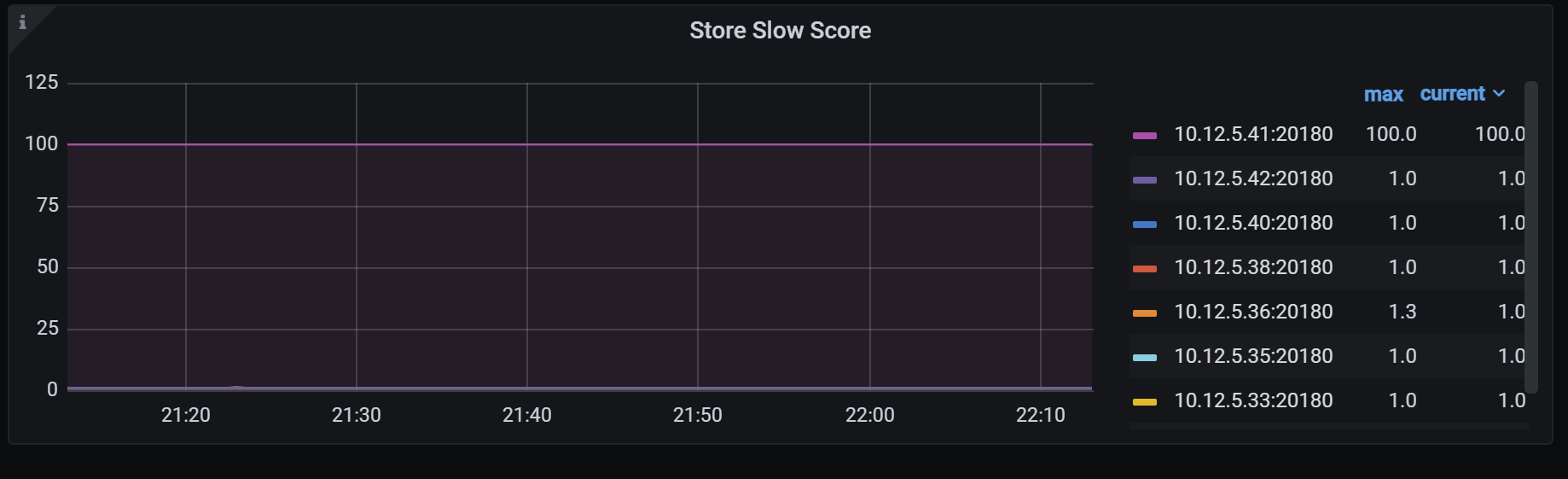
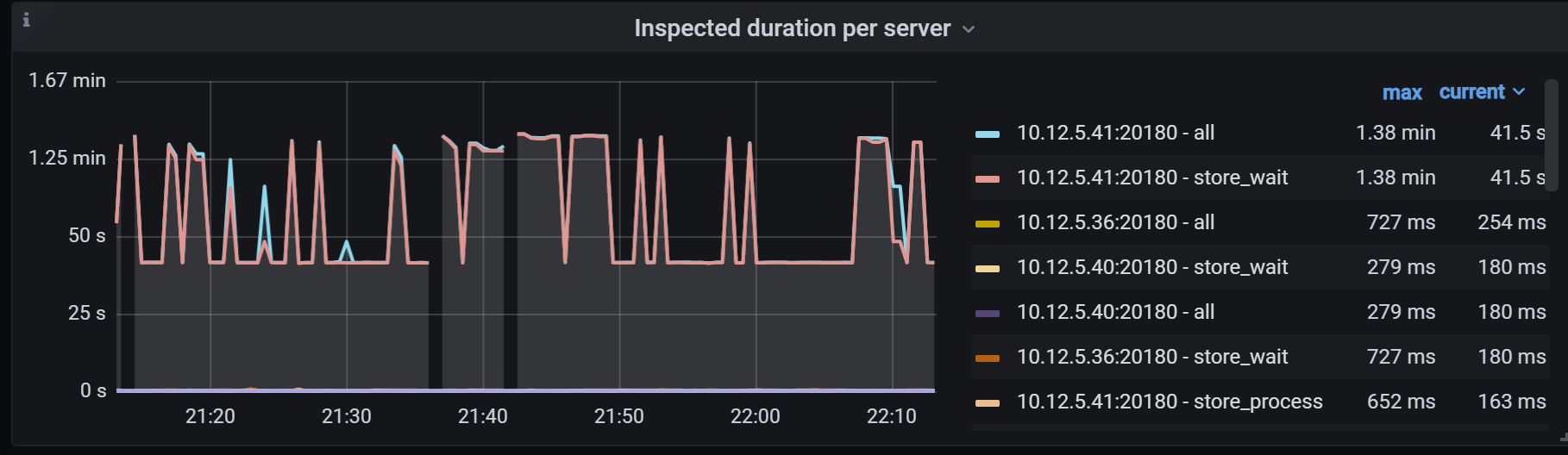
现在集群的访问是否正常,访问的QPS和延迟情况如何?可以从grafana的TiDB 面板查看到
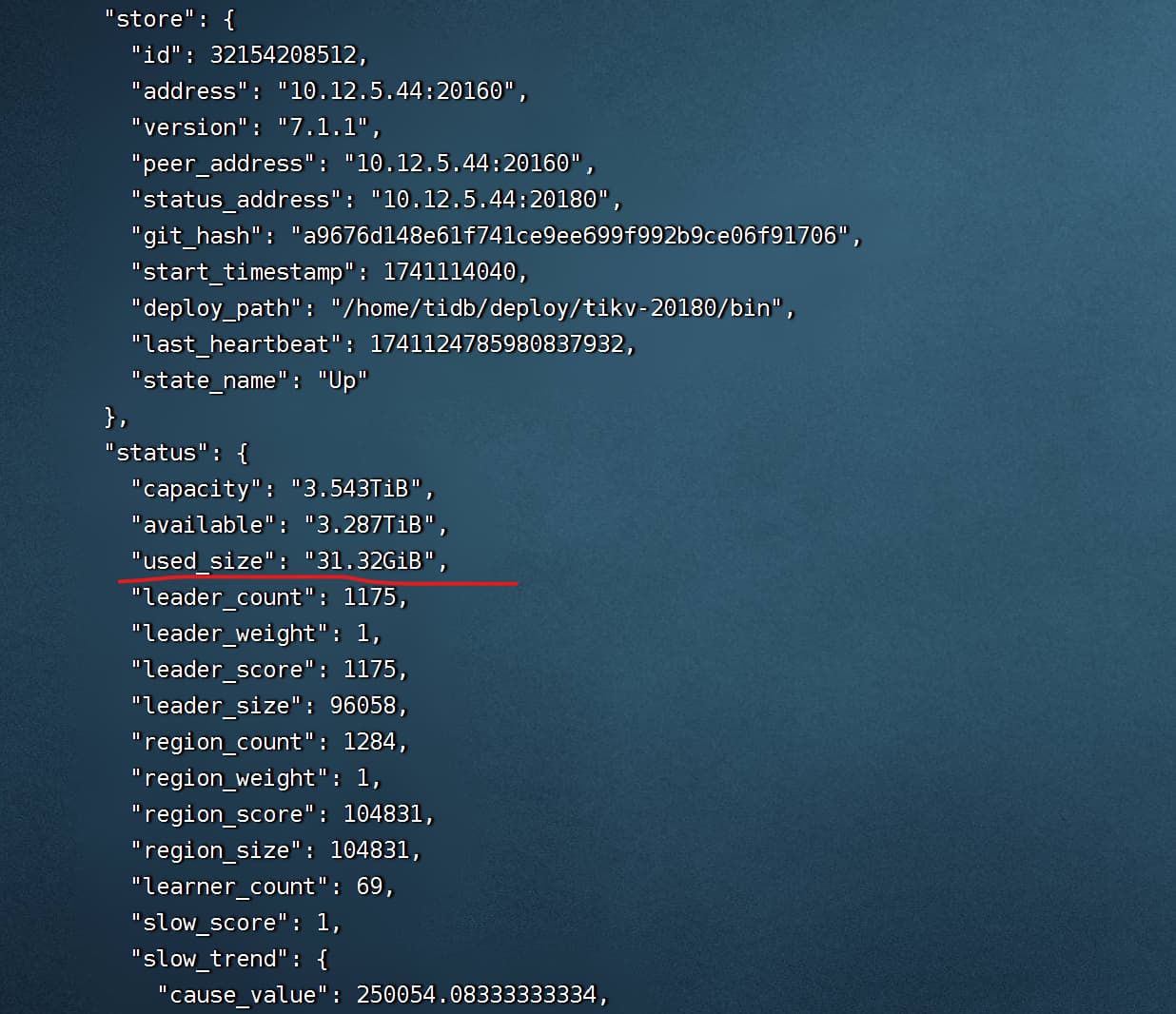
刚刚删除了kv节点的日志目前空出来一些空间 每个kv节点可用空间大小如下:
Qps是这样
我新扩容了一个kv节点,但是很慢。三个小时才迁移了30G,这个速度怎么提高呢。
集群现在无法正常使用,查询会报 tikv timeout和 region is unvailable
好的感谢,我先赶紧扩容了一下。现在扩容了一个固态,一个机械的,但是两个迁移的速度都比较慢, 固态那个三个小时迁移了大概30G
可以参考这个,调整一下速度。