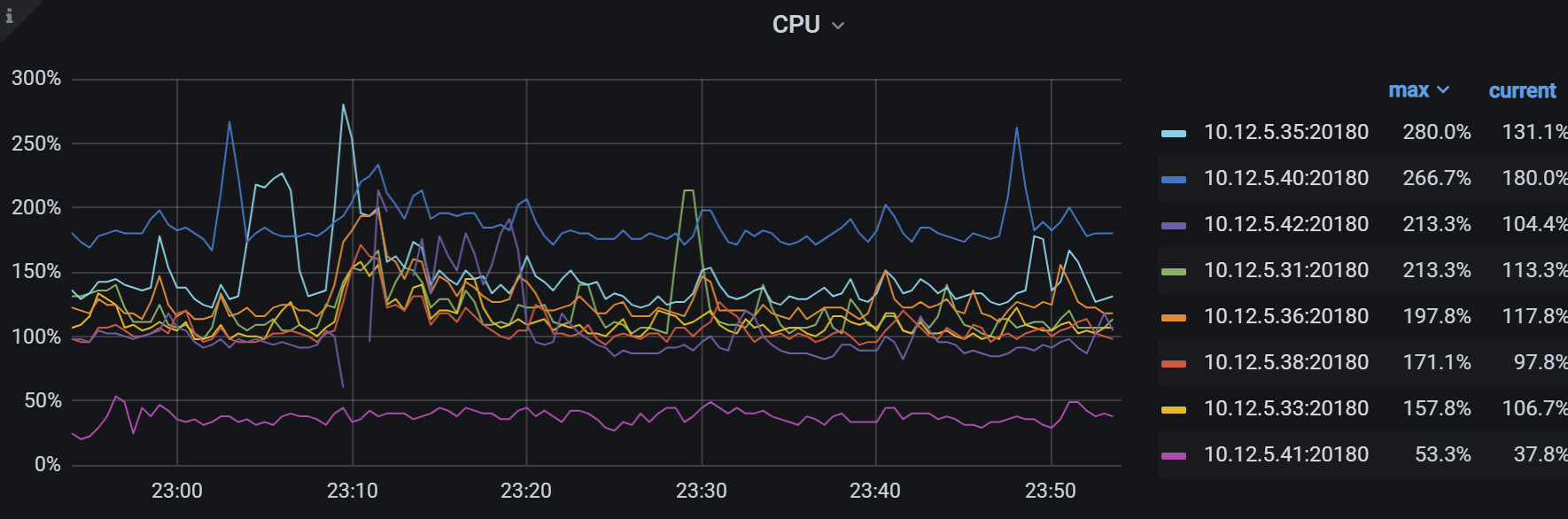
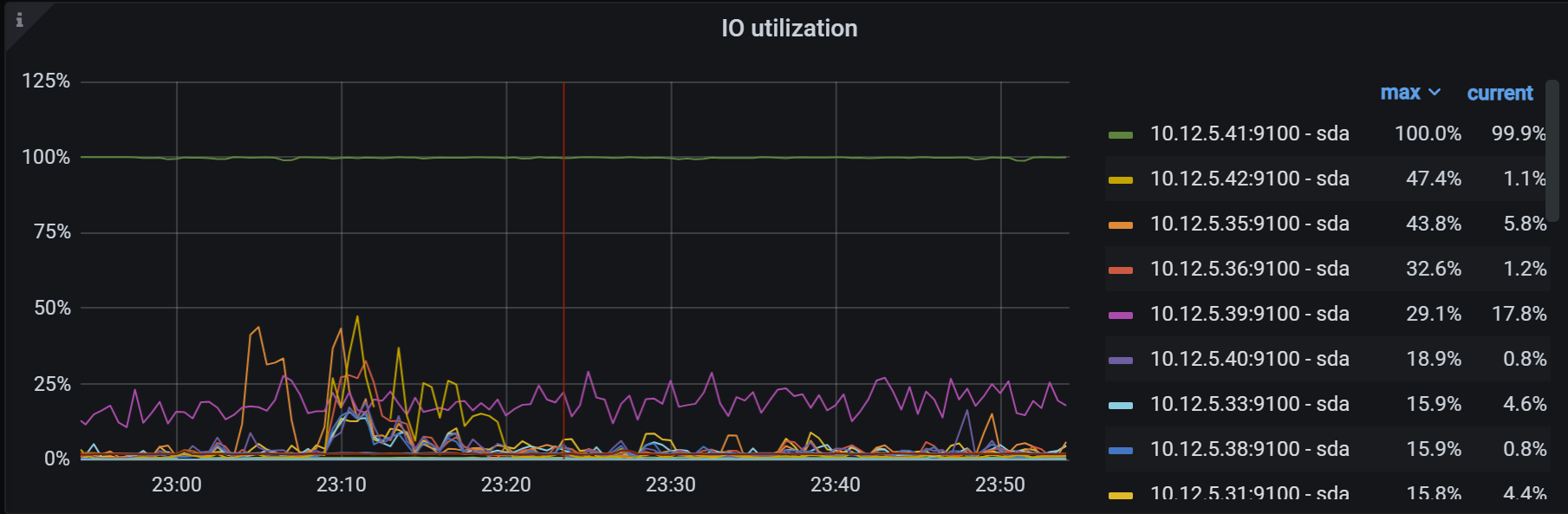
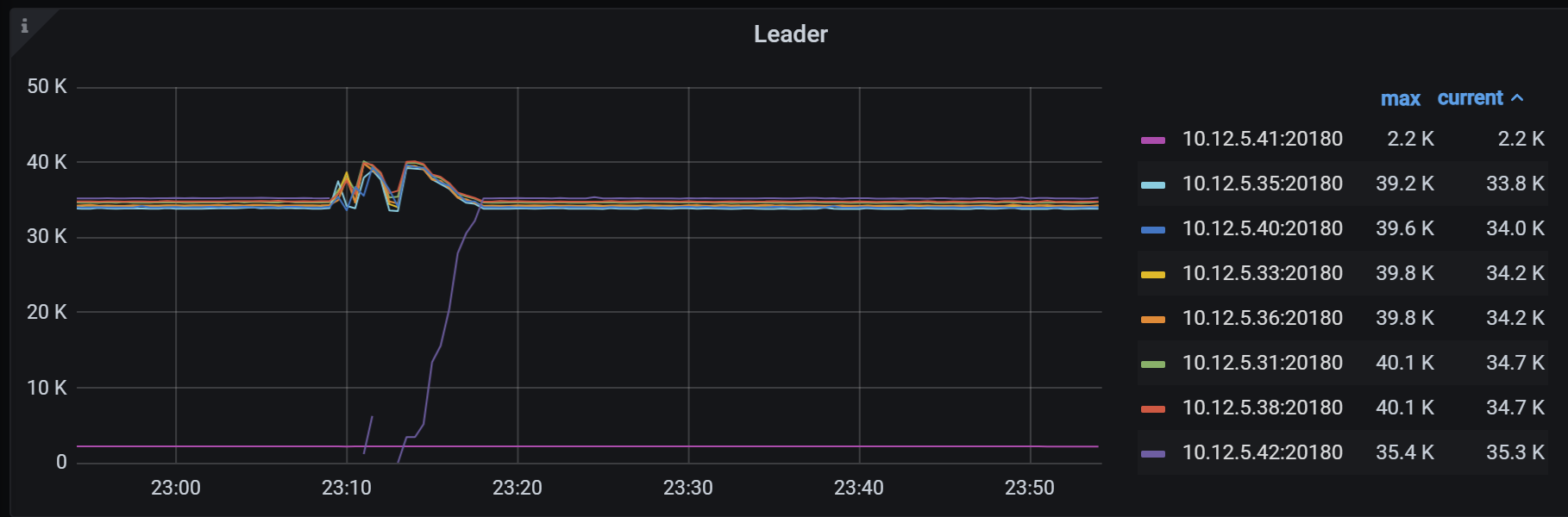
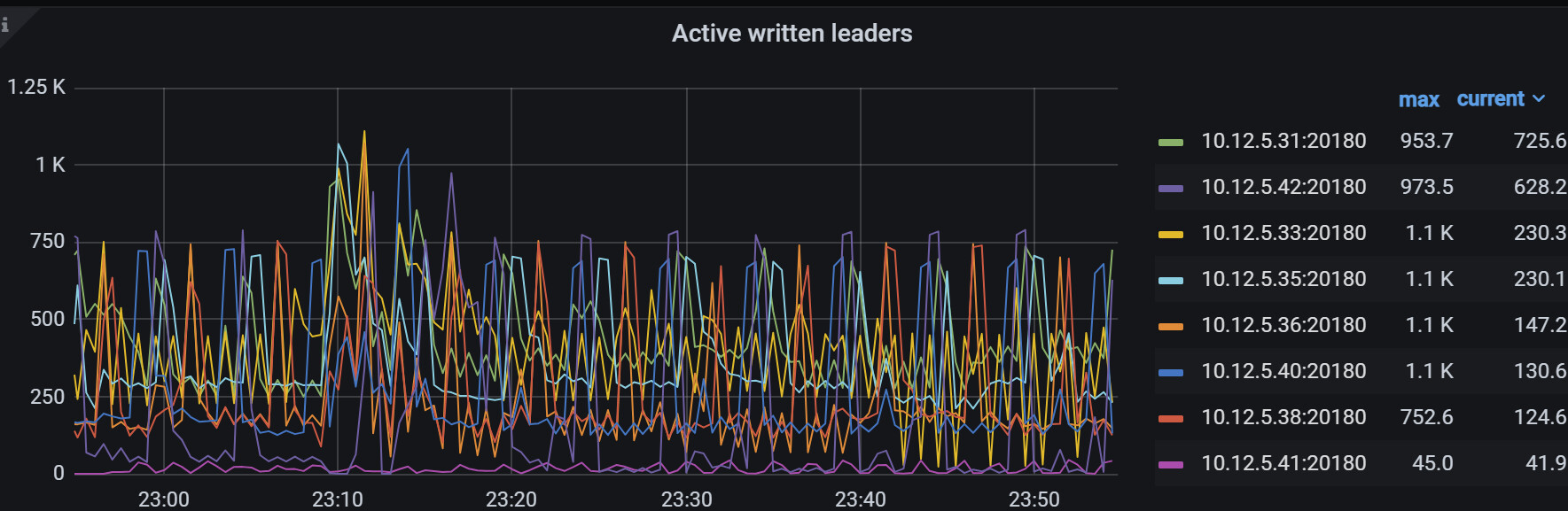
各个监控指标看起来41节点都不正常

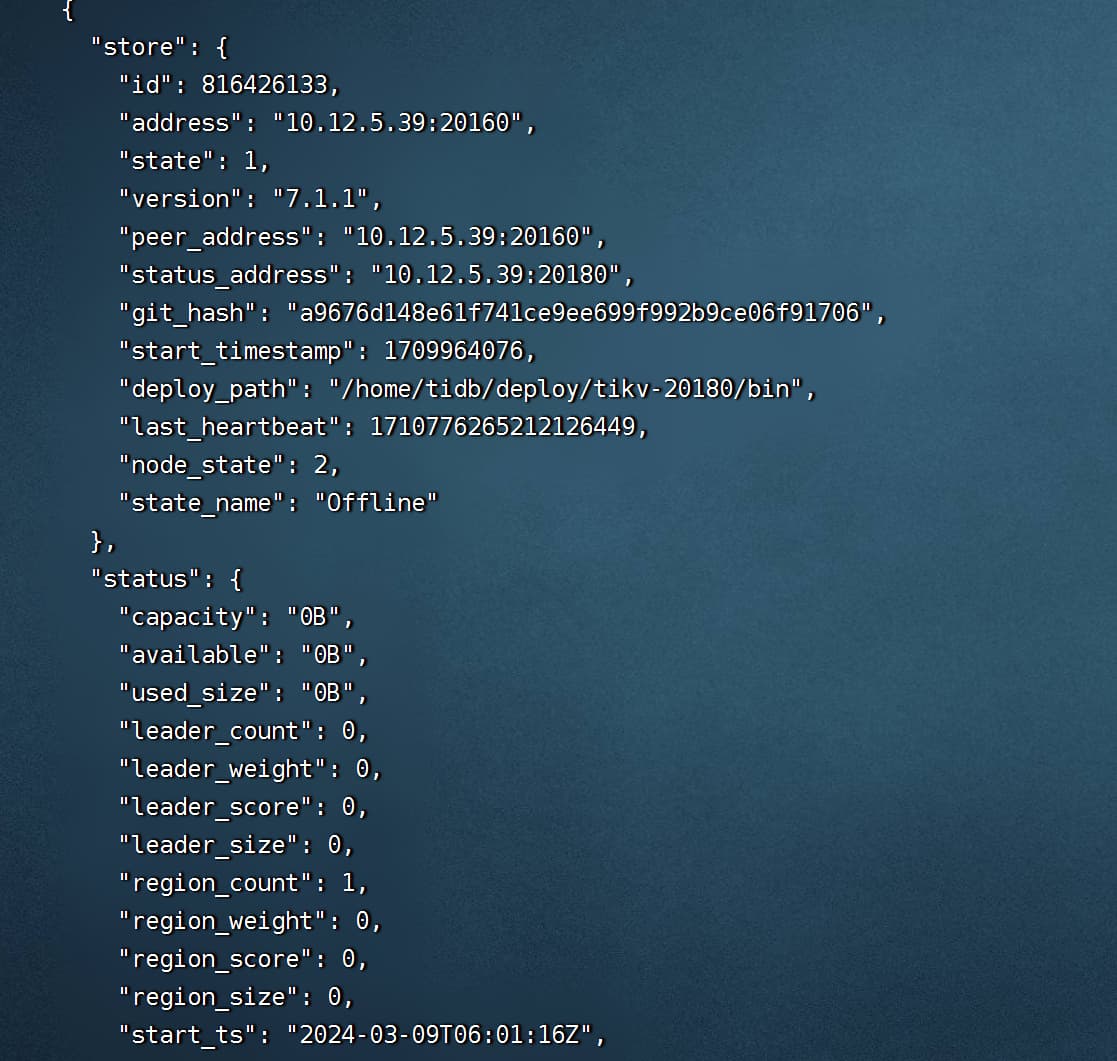
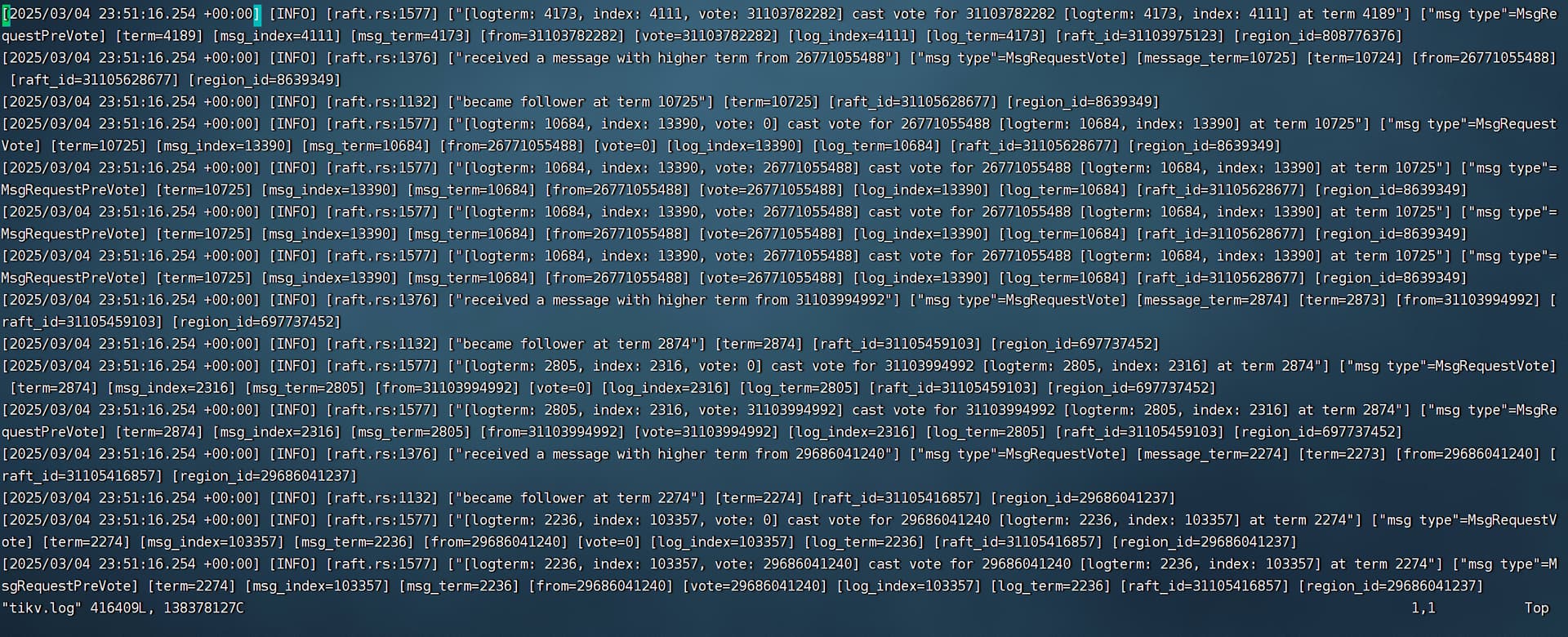
查看kv41的日志,最新信息有这个。
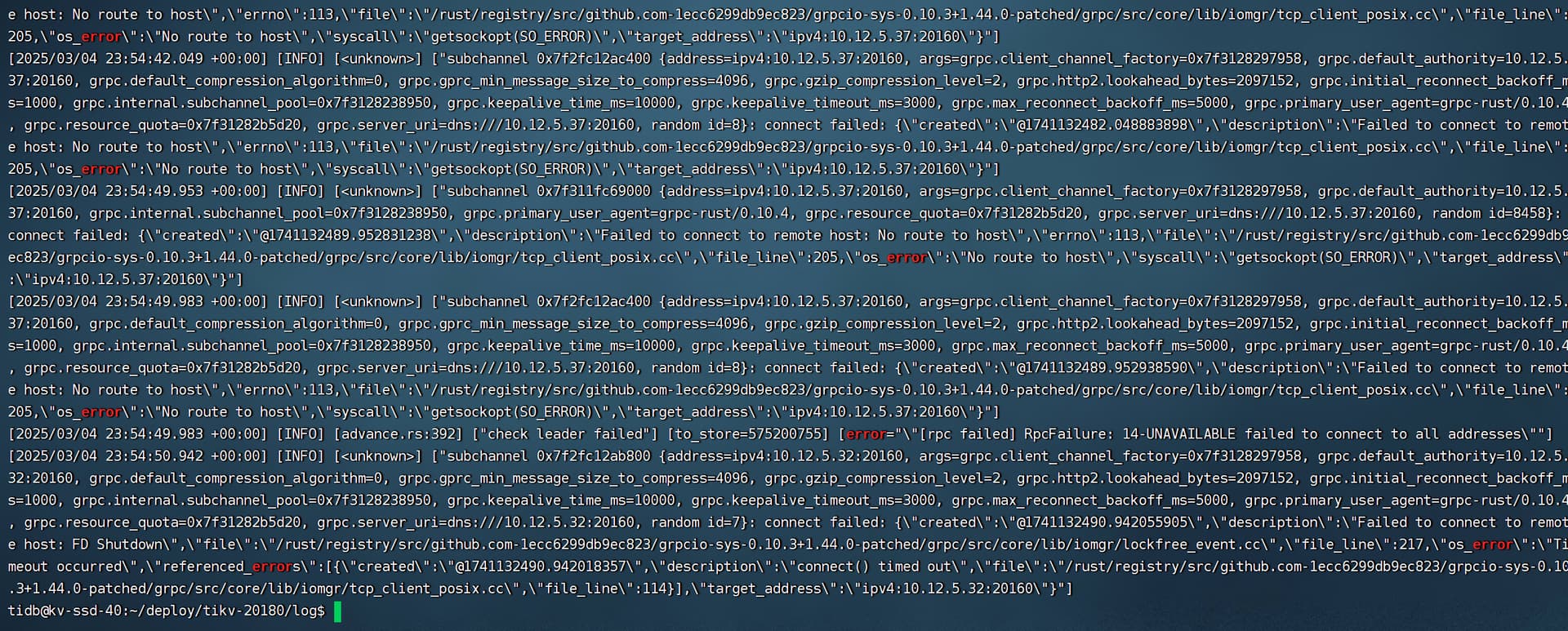
grep了一下error,好像基本都是和32节点和37节点有关。32和37节点都是异常节点,32节点目前pending offline ,37节点的物理机坏了。不过我去看一个其他slow-score=1的节点的日志,error相关日志也是与32和37节点有关。
求助,我目前该如何解决41节点slow-score=100的问题。我今晚又扩容了一个SSD和机械,SSD4个小时移过来了40G正常吗?
各个监控指标看起来41节点都不正常
查看kv41的日志,最新信息有这个。
求助,我目前该如何解决41节点slow-score=100的问题。我今晚又扩容了一个SSD和机械,SSD4个小时移过来了40G正常吗?
41我感觉可以先不管,先把32的pending offline的问题解决掉。参考上面这个帖子把缩容速度调大点。
里面给出的例子中的数值是5,注意不要照搬,改成500,让缩容速度快点。另外例子中单独指定store id的方式现在也别研究了。直接all,都调大点,pending offline的问题有个结果再说。
pd-ctl的安装看
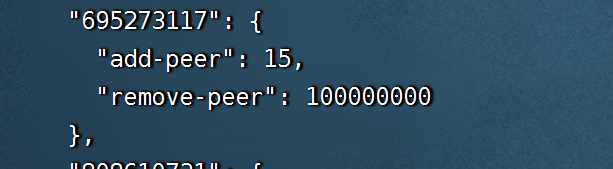
老师,我select查找到了kv39节点 仅剩的那个region_id是795615795,我直接执行命令pd-ctl operator add remove-peer 795615795 795615795 可以吗?
kv 39节点最好也先解决,一步一步排除异常,缩小范围。
剩下1个两个 直接收缩
tiup cluster scale-in 这个收缩,你怎么有operator add remove-peer这个操作?
我收缩都是先store weight xx 0 0 等region数量剩下10左右,直接scale-in 收缩掉 就没了。
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices/#tikv-节点故障处理策略
可以考虑用 pd-ctl 临时删除 slow store 机制。