想问一下,TiDB分页查询时候,他的执行流程是啥样的啊,网上没找到相关文档
两种情况:
第一种分页查询:order by id limit 50,200 也就是50-250的数据—这种是把所有tikv节点符合条件的数据拉回到tidb-server然后进行重排序,然后取符合条件的数据,可以保证offset的连续性
3 个赞
乡在人间
2025 年3 月 18 日 01:46
3
第一种分页查询:order by id limit 50,200,这个算子下推至tikv节点,根据条件,应该每个tikv节点也只需要返回前200行(这样进一步减少资源消耗),然后汇总至tidb server在进行刷选符合条件的就可以了。
1 个赞
Kongdom
2025 年3 月 20 日 08:23
5
tidb菜鸟一只:
每次查询都可能不一样的
应该是默认按主键排序吧,刚验证了一下,每次返回结果是一样的。也可能是样本太小的缘故。
tidb不保证返回顺序的,没有order by的话
1 个赞
Royce1220
2026 年3 月 30 日 05:55
11
是的,分布式的应该和mysql行为有些不一样,另外不知道有没有兼容的参数
你可以参考 TiDB 官方文档中关于“执行计划”和“分页查询”的部分,虽然它们没有画出你这种具体的 Region 图,但原理是一致的:
TiDB 执行计划介绍:解释了 TableReader和 TableRangeScan的工作原理。
分页查询最佳实践:解释了为什么深分页慢以及如何使用主键优化。
可以试下 “Where id > 上次最大的id”
北南南北
2026 年4 月 3 日 23:07
15
LSM-TREE架构的存储引擎,对于写入友好,对于读容易放大,放为数据存在多个节点。
有 ORDER BY(正确分页):
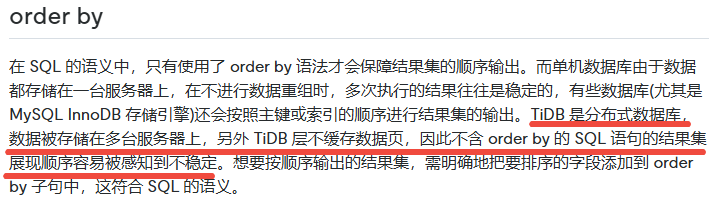
TiDB 分页 必须加 ORDER BY ,否则结果是分布式 “随机采样”,不是业务分页。
zhanggame1
2026 年4 月 7 日 05:58
20
tidb返回数据不加order by是乱序的,包括使用union all也不保证顺序
是的 ,ORDER BY 不是可选项,而是分页查询的必选项