前几天突然有两个tikv节点宕机,不分region不可用不可查,但是为什么正常的可以查看到的数据延迟变高?自从两个tikv宕机之后延迟一直是1min。慢查询可以看到一个insert一条常量的,update都是要四五十秒之前都是1s的。
现在问题是丢失的region暂时先稍后处理,这个延迟是什么导致的,怎么处理

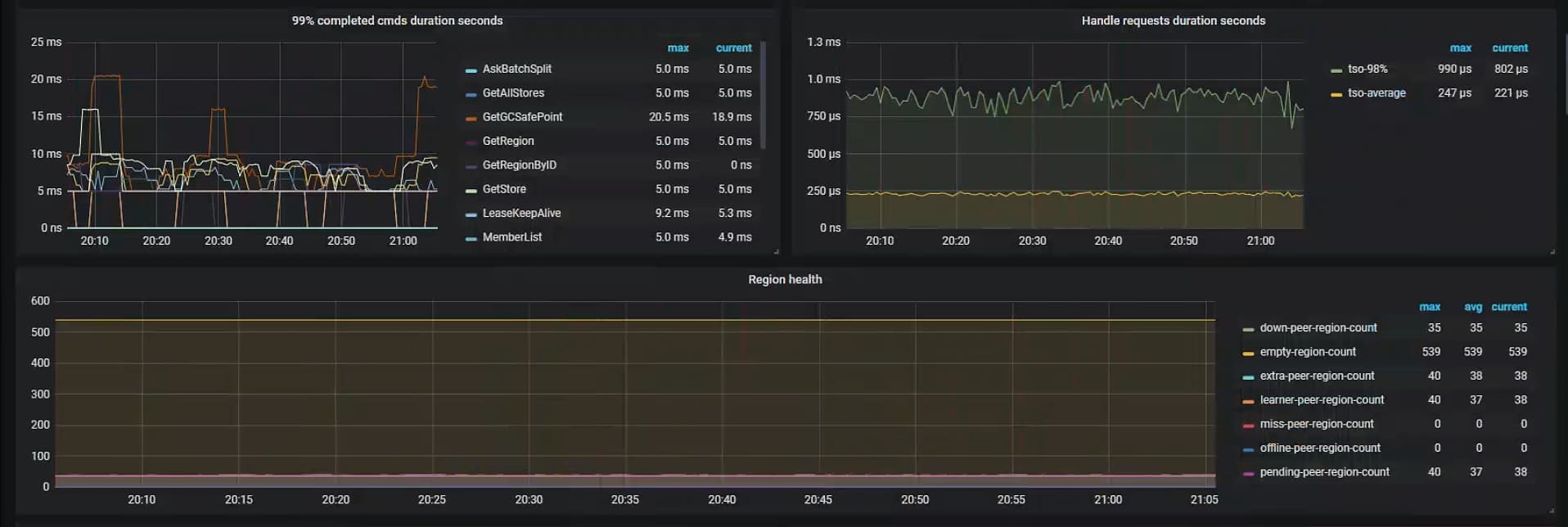
这个是pd-leader的部分日志
前几天突然有两个tikv节点宕机,不分region不可用不可查,但是为什么正常的可以查看到的数据延迟变高?自从两个tikv宕机之后延迟一直是1min。慢查询可以看到一个insert一条常量的,update都是要四五十秒之前都是1s的。
现在问题是丢失的region暂时先稍后处理,这个延迟是什么导致的,怎么处理
这个是pd-leader的部分日志
是不是region在重新调度,查一下tikv的监控,看看IO消耗情况呢
已经过去3天了。region调度应该已经结束了。我查了目前没有只有2副本的region,那就是当前就只有3副本和1副本的数据了这个down peer和pending-peer当时都是1万多现在过3天了都变成几十个不在降低了,一开始我以为是这个原因,现在这个已经稳定了。延迟还没变化
可以一步一步排查下延迟的点在哪里。下面两个可以参考下:
TiDB 性能分析和优化方法 | TiDB 文档中心
延迟的拆解分析 | TiDB 文档中心
目前检查发现。慢日志里面的sql都是 region RPC和region miss,初步判定为慢sql和延迟都是因为sql查到了丢失region数据的sql
不应该吧,region miss了系统可以感知到,不会再去有请求了吧
是用户发的sql包含了这一部分丢失的数据吧,然后客户端不就是会返回 region unvialbe。
不对吧,你修改过配置1副本吗?默认3副本的话,丢失的region数据可以在其它region副本里找到
挂了两台服务器,不是一台。同时丢了2个副本
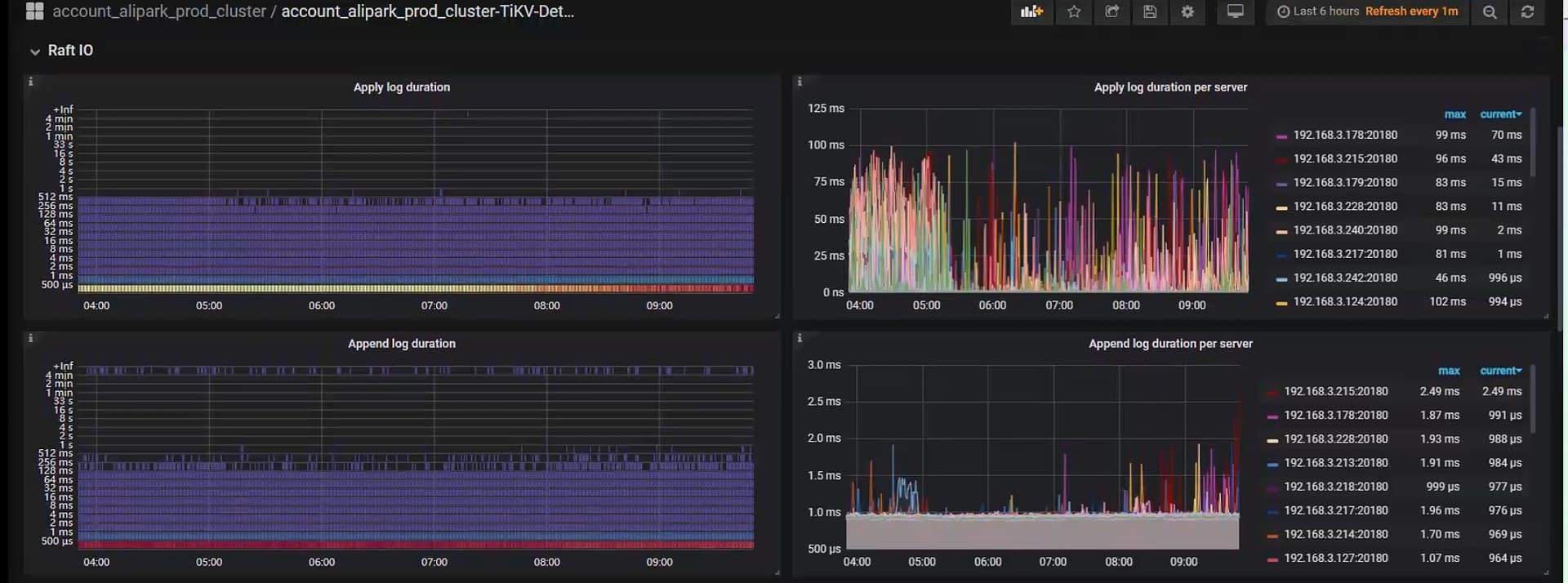
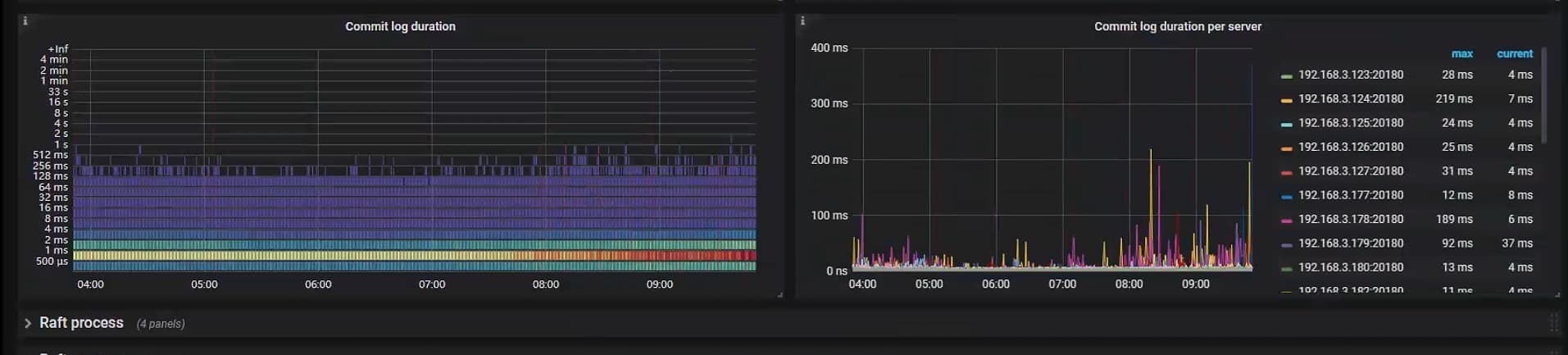
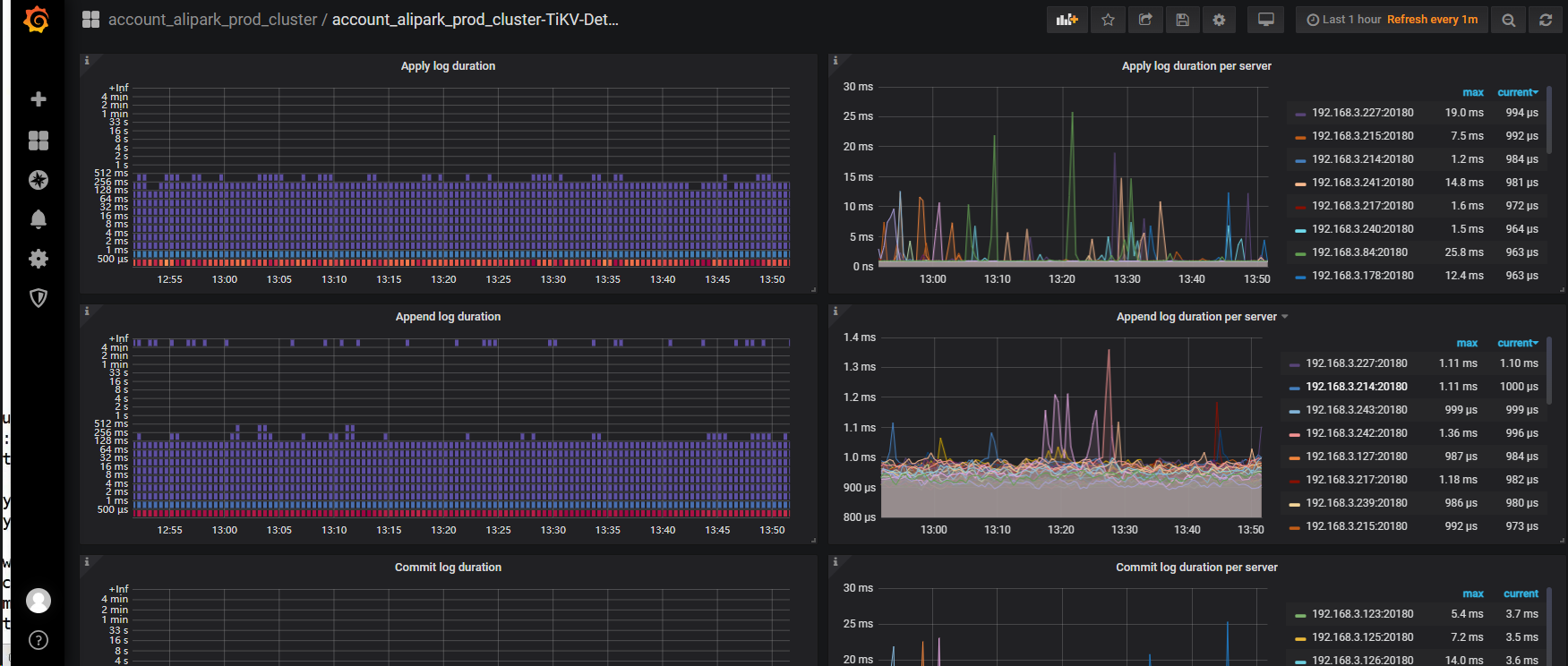
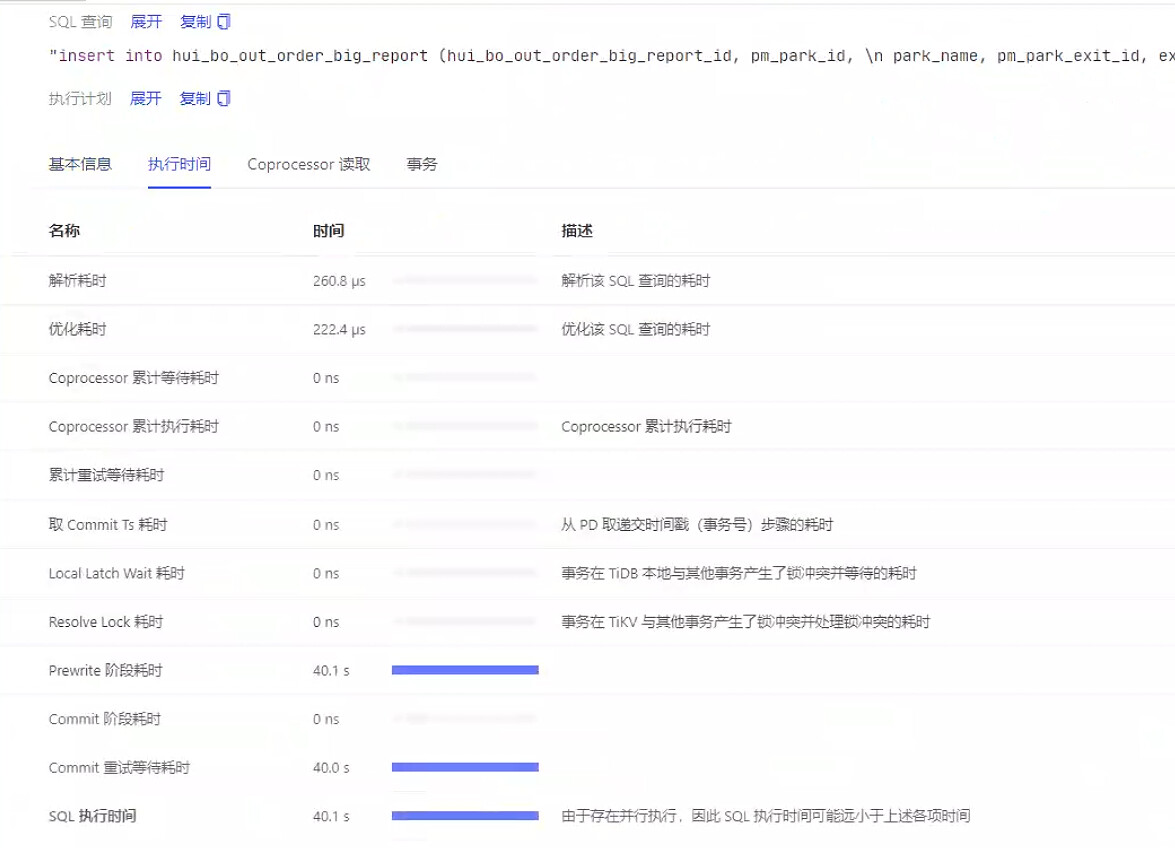
延迟在 priwrite 那,看下写入性能,raft-io 那块
这个集群的region副本数是多少呀,之前有没有打上label呢。
副本数 4万多个吧。lable没有。这是前任安装的2.0版本然后又升级到4.0.配置很简陋
raft-io 这里看着还行, commit 重试等待时间比较长,你看下这个 sql 是执行成功还是失败的
失败的,看样子应该都是查到故障region才爆出的错。
那这个时间长就是一直在重试,重试到超时失败了啊 ![]()
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。