【 TiDB 使用环境】生产环境
生产出现了,资源超出配额(初始配了500),导致查询报错的问题。已经进行了配额调整(1500),还配置了超出配额允许使用系统剩余的资源。
我想找到到底是哪个SQL,或者是哪些SQL导致的RU使用超标?
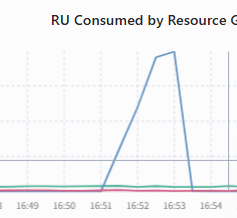
在这个时间区间内并没看找到明显资源占用多的SQL,反而有很多是由于 “RC 等待累积耗时” 过高导致整体执行时间很长的SQL。不知道是我排查的方式有问题还是其他原因?请教各位大佬,遇到这种问题你们是怎么排查的?
【 TiDB 使用环境】生产环境
生产出现了,资源超出配额(初始配了500),导致查询报错的问题。已经进行了配额调整(1500),还配置了超出配额允许使用系统剩余的资源。
我想找到到底是哪个SQL,或者是哪些SQL导致的RU使用超标?
https://docs.pingcap.com/zh/tidb/stable/information-schema-slow-query/#slow_query
slow_query和cluster_slow_query表上,有
Field Type Null Key Default Extra Resource_group varchar(64) YES NULL Request_unit_read double YES NULL Request_unit_write double YES NULL
这3个字段。
https://docs.pingcap.com/zh/tidb/stable/statement-summary-tables/#statements_summary
statements_summarystatements_summary_historycluster_statements_summarycluster_statements_summary_history这4个表也有和资源管控相关的字段:
AVG_REQUEST_UNIT_WRITE:执行 SQL 语句平均消耗的写 RUMAX_REQUEST_UNIT_WRITE:执行 SQL 语句最大消耗的写 RUAVG_REQUEST_UNIT_READ:执行 SQL 语句平均消耗的读 RUMAX_REQUEST_UNIT_READ:执行 SQL 语句最大消耗的读 RUAVG_QUEUED_RC_TIME:执行 SQL 语句等待可用 RU 的平均耗时MAX_QUEUED_RC_TIME:执行 SQL 语句等待可用 RU 的最大耗时RESOURCE_GROUP:执行 SQL 语句绑定的资源组
查询执行时间长或消耗资源多的 SQL:
SELECT query, exec_count, avg_rpc_duration, max_rpc_duration
FROM information_schema.cluster_slow_query
WHERE start_time > ‘2025-07-14 00:00:00’ – 设置为你要检查的时间段
ORDER BY max_rpc_duration DESC LIMIT 10;
Dashboard中看TOP SQL
这么多天了。问题解决了么
RU是个什么参数
CREATE RESOURCE GROUP ... WITH RU_PER_SECOND = ...),避免单条 SQL 耗尽集群配额。我们一边是看dashboard的慢查询去排查。
RU应该是指资源单元,应该是配了资源隔离,但是用超了吧。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。