【TiDB 使用环境】生产环境
【TiDB 版本】V7.1.0
【操作系统】
【部署方式】tiup 物理机
【集群数据量】45TB
【集群节点数】
【问题复现路径】
【遇到的问题:问题现象及影响】
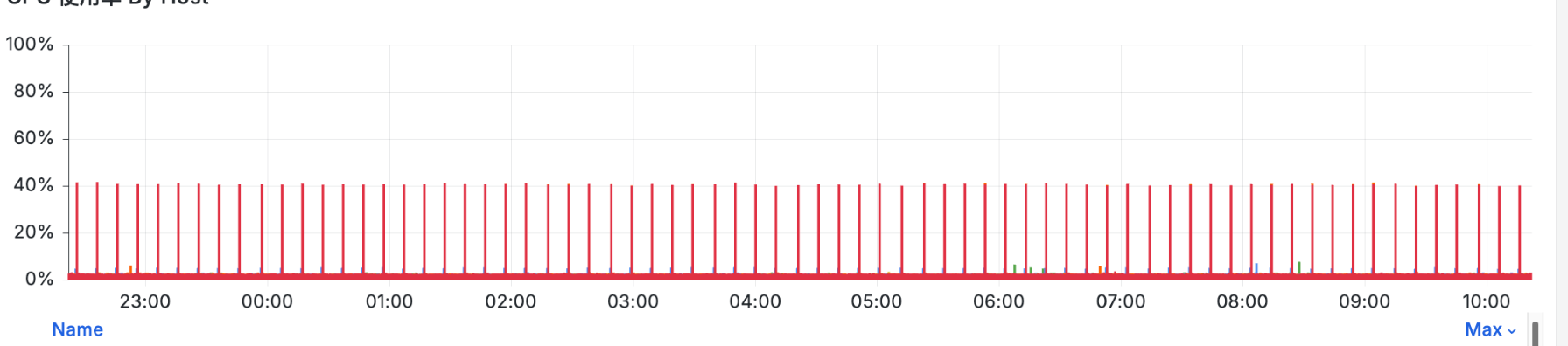
每十分钟 tikv 的机器 CPU 就飙升一次,同时主机负载也从 5% 飙升到 40%
【资源配置】

【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
【TiDB 使用环境】生产环境
【TiDB 版本】V7.1.0
【操作系统】
【部署方式】tiup 物理机
【集群数据量】45TB
【集群节点数】
【问题复现路径】
【遇到的问题:问题现象及影响】
每十分钟 tikv 的机器 CPU 就飙升一次,同时主机负载也从 5% 飙升到 40%
【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
第一张图里的QPS是不是也是10分钟一次飙升?
看qps的飙升周期与cpu是一致的,看看有没有对应的定时任务。 或者看看对应的期间的sql
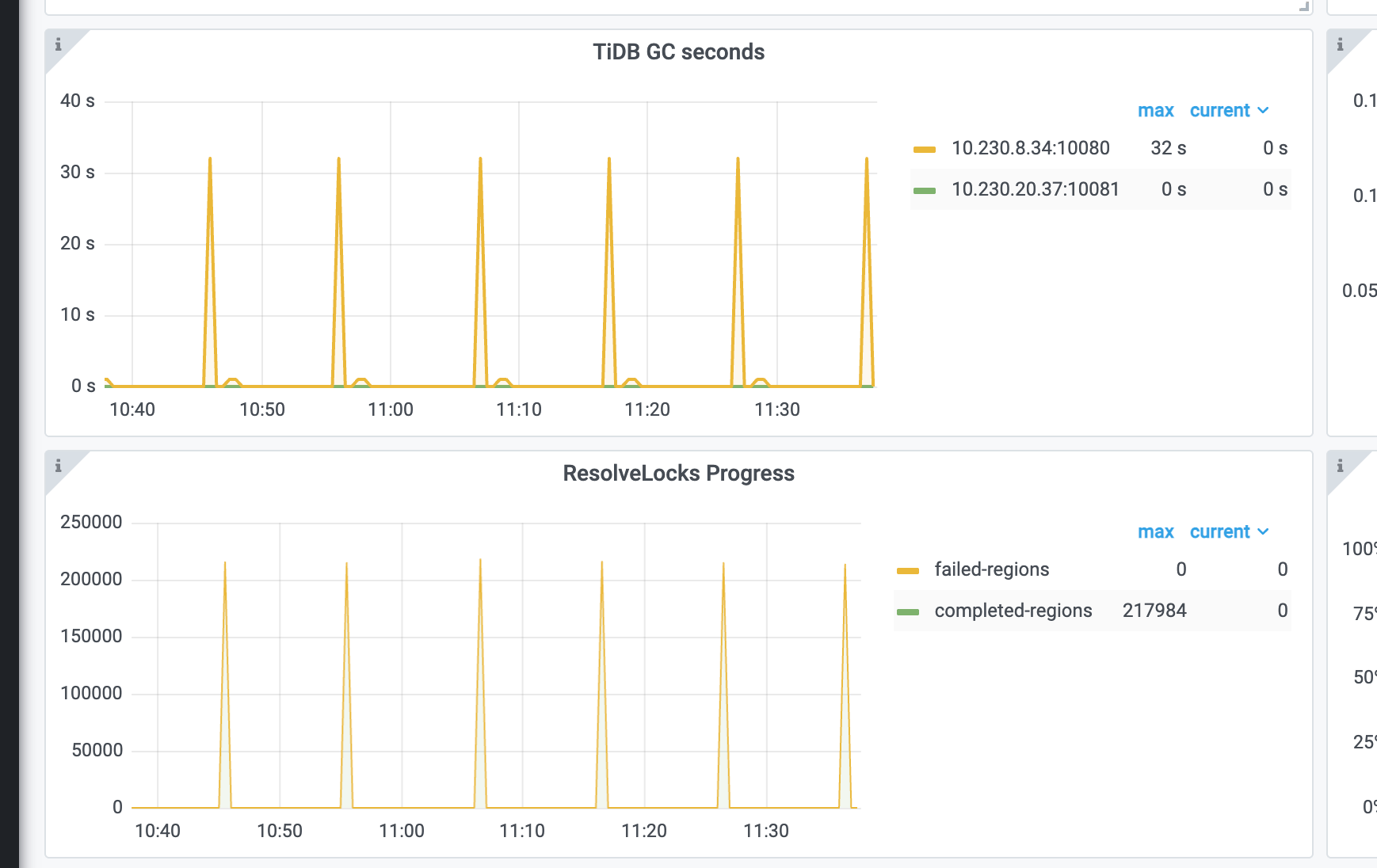
十分钟应该是gc的时间,可以看下与gc时间是否对应
会不会是有其他定时作业?
目前集群是新建的,没有任何业务流量。在独立的新机房
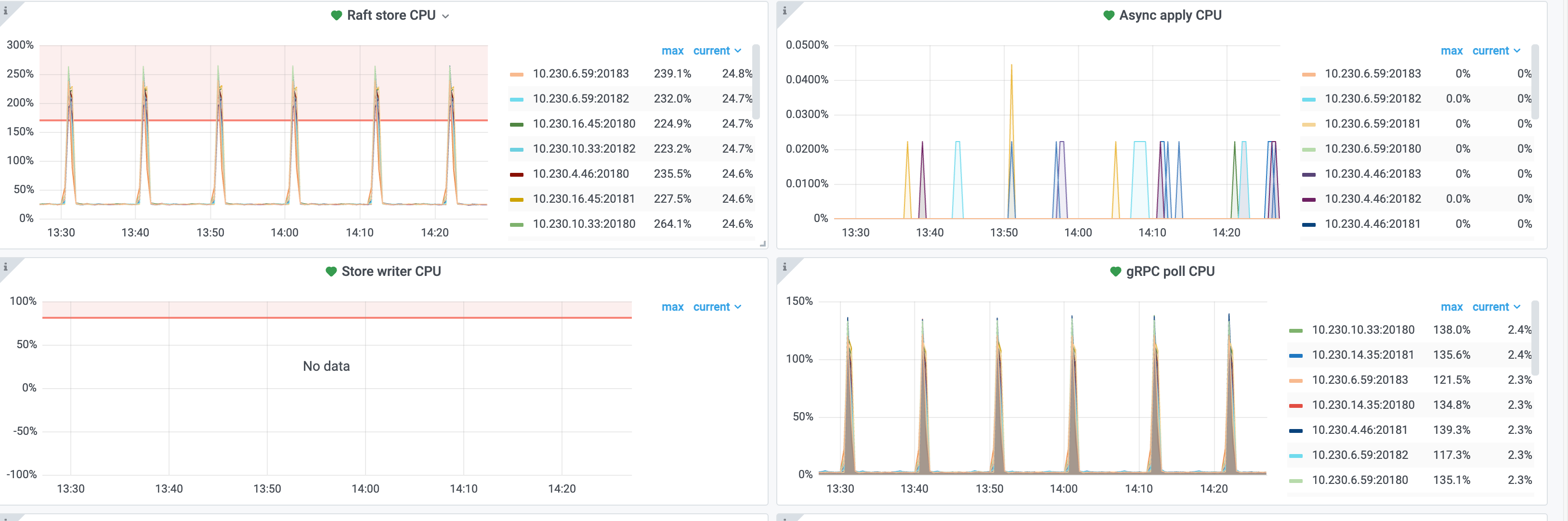
你的tikv是混布的吧,一台机器几个tikv,一共多少个kv,当前单个kv的数据量多少,region总量多少,如果很多的话也是有可能的
一个物理机的规格是 80C 768G 4 * 3.84Tnvme,运行了 4 个 TIKV 节点,都做了 NUMA 绑定和 CORES 绑定。
当前的 regions
单个 kv 存储的数据量是 1.2TB
下面是 CPU用量截图
看你是7.1.0的版本,试下关闭这个参数,看看有没有效果
https://docs.pingcap.com/zh/tidb/stable/garbage-collection-configuration/#gc-in-compaction-filter-机制
介绍raft同步这章内容确实多
ops和sql语句分析里面的按执行时间排序看看
好像有个参数是每10分钟做一件什么事,可以查查
是不是有大量数据操作,人为的迁移数据什么的,然后GC10分钟操作的时候引起CPU飙升。
看下统一读呢
有定时的大事务吗
看看是不是gc任务导致的,可以调整参数后再观察