案例1
explain analyze
select t1.user_id,t2.cust_curr_bal,cust_distr_amt from dtl.t_gm_ec_lon_dubil t1 left join(select
user_id – 客户编号
,sum (ifnull (curr_bal,0)) as cust_curr_bal --汇总到客户的贷款余额
,sum (distr_amt) as cust_distr_amt --汇总到客户的放款金额
from dt1.t_gm_ec_lon_dubil --小微贷款明细
where data_dt - date_format(‘20241231’,‘%Y-%m-%d’)–20210615 将网商批处理改为次日下午 group by user_id) t2
on t1.user ide2.user_id 0 ta_at - date_format(‘20241231’.‘%Y-m-d’)
–案例2
explain analyze select
user_id – 客户编号
.sum (ifnull (curr_ba1, 0)) over (partition by user_id order by lp_id,dubil_id) as cust_curr_bal – 汇总到客户的贷款余额
,sum (distr_ant ) over (partition by user_id order by lp_id,dubil_id) as cust_distr_amt – 汇总到客户的放款金额
from dt1.t_gm_ec_1on_dubil 小微贷款明细
where data_dt- date_format('20241231’,‘Y-%m-&d’)-- 20210615将网商批处理改为次日下午
查询结果一致,在性能方面案例1和案例2哪一个更优一点

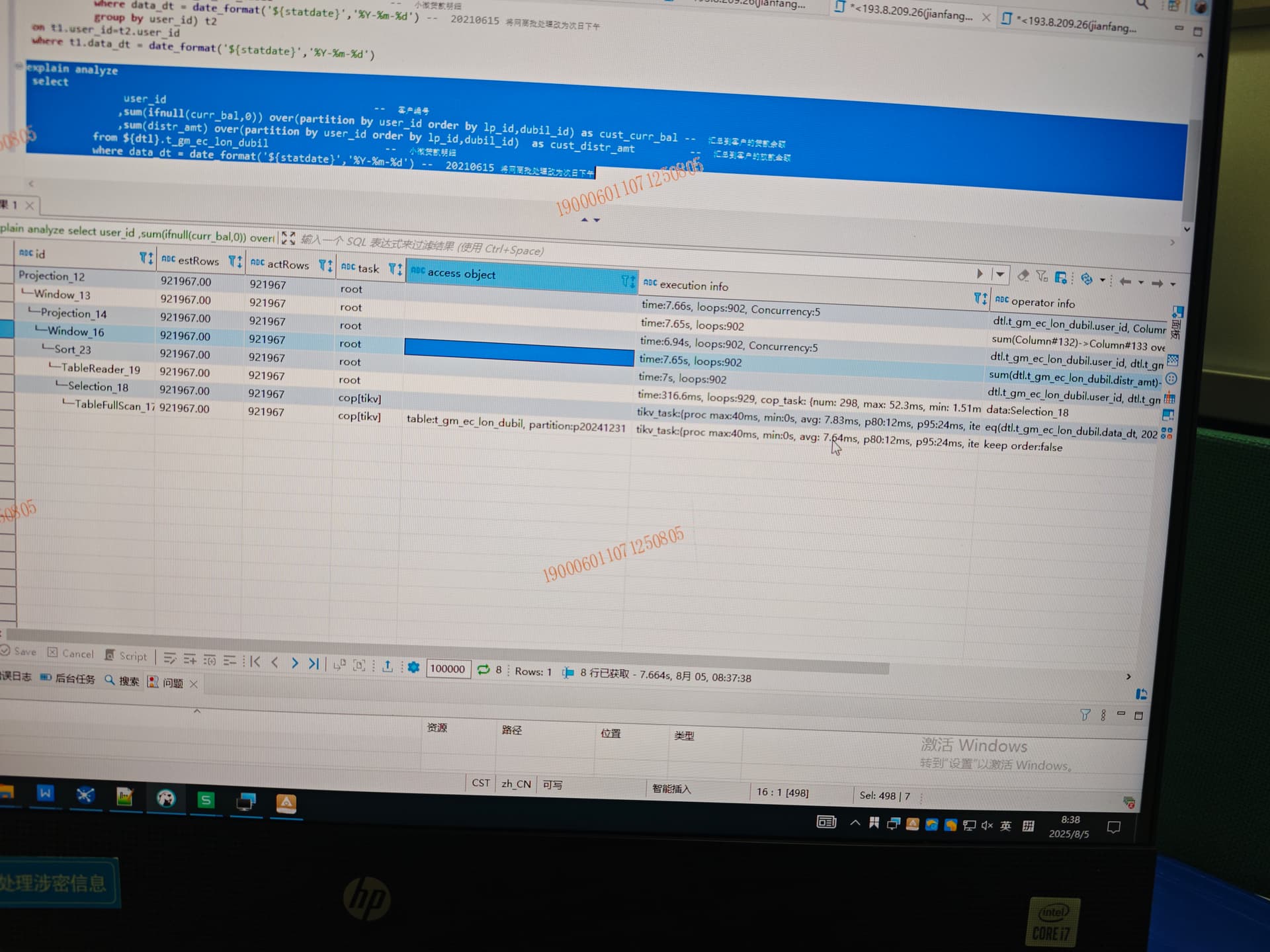
执行计划贴出来吧,只看语句也看不出来。
已贴,有劳大佬帮忙瞧瞧
我看sql感觉应该第二个好一点,但是看你的实际执行计划,第一个的执行效率要更高
首先这两个sql不是等价的。结果一致是因为当前数据刚好满足,或者表里的所有数据都满足。
sql2的窗口函数用了order by,指的是按行累加。sql1是分组总和。
你把order by删了后应该是等价的,并且从执行计划看,时间应该都是在order by了。
第一个sql都放到tikv里处理了,tikv是多节点并行,tidb端处理的少了。第二个sql都放到tidb端处理了,tidb端是单节点处理,明显慢了很多。
第一个执行效率高点吧
图片不是执行计划吗
一开始没有,后来补充的。别考古了。
学到了。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。