【TiDB 使用环境】生产环境
【TiDB 版本】8.5.1
【操作系统】
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)
【集群数据量】
【集群节点数】
【问题复现路径】
【遇到的问题:问题现象及影响】tidb集群经常告警tidb_memory_abnormal;我看官方的处理方法就是说通过 HTTP API 来排查 goroutine 泄露的问题。这个有没有具体一点的排查手段哇 ![]()
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
【TiDB 使用环境】生产环境
【TiDB 版本】8.5.1
【操作系统】
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)
【集群数据量】
【集群节点数】
【问题复现路径】
【遇到的问题:问题现象及影响】tidb集群经常告警tidb_memory_abnormal;我看官方的处理方法就是说通过 HTTP API 来排查 goroutine 泄露的问题。这个有没有具体一点的排查手段哇 ![]()
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
https://docs.pingcap.com/zh/tidb/stable/configure-memory-usage/#tidb-内存控制文档
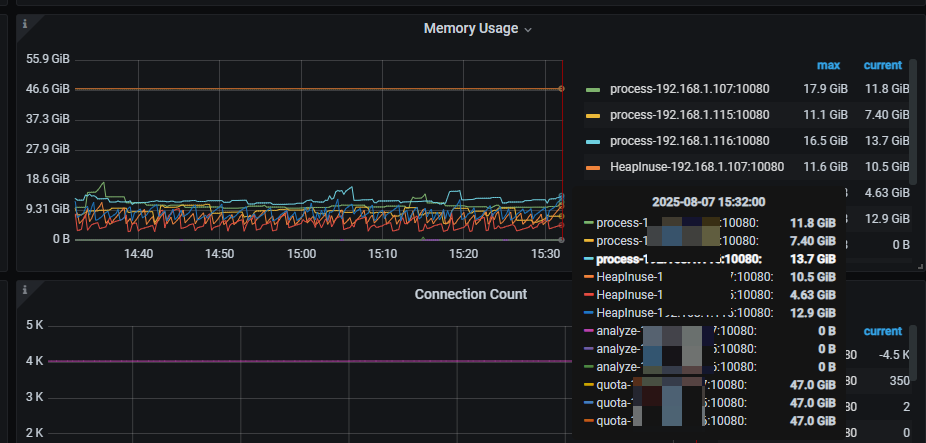
谢谢您的回复,我的问题貌似跟这个文档没有关系;这个监控应该是说的heap使用内存大于10G才告警;我的三个tidb实例的heap内存经常大于10G;我是想排查heap内存大于10G的原因;而不是配置tidb-server实例使用内存的阈值
dashboard 检查慢sql? 还是说要定位内种中包含了哪些库表信息
把阈值调高就好了,大于 10g 很正常
我也类似的问题想知道server占用内存的具体情况。 请问这里的大于10g很正常有什么说法吗?
机器有那么多内存,为啥不能超过 10g 呢
![]() 不应该这么问
不应该这么问
正常heap堆内存只要不超过process对应的tidb server最大内存,server就不会真的OOM,是吧
只不过实际heap堆内存超过 tidb_server_memory_limit * alarm_ratio 就会出现 risk of oom的告警,调整alarm_ratio 可以减少这类告警, 你是这个意思吧?
tidb 进程内存不超过操作系统限制就好,操作系统内存过少会导致进程申请内存时报错,触发操作系统保护机制 oom-killer。
减少监控告警可以调整告警表达式。
嗯嗯这个了解。
另外就是能有什么办法可以有效分析server的heap中都是那些占用内存,占用多少内存么
TiDB Dashboard 上有个 高级调试 =》 实例性能分析 =》 手动分析 功能
当 TiDB 集群出现 tidb_memory_abnormal 告警,使用 HTTP API 排查 goroutine 泄露,可参考以下具体的排查手段:
/debug/pprof/goroutine?debug=2 接口,能获取详细的 goroutine 堆栈信息。示例命令如下:bash
curl http://<tidb-server-ip>:<port>/debug/pprof/goroutine?debug=2 > goroutine_dump.txt
其中,<tidb-server-ip> 是 TiDB Server 节点的 IP 地址,<port> 是对应的端口号(默认 10080 )。获取的 goroutine_dump.txt 文件会包含所有 goroutine 的堆栈跟踪信息,包括 goroutine 正在执行的函数、调用链等。
goroutine_dump.txt 文件,主要关注以下几个方面:block 状态的 goroutine ,例如等待锁(sync.Mutex 或 sync.Cond 等)、网络 I/O 阻塞(如 net/http 相关的等待)等。如果存在大量长时间阻塞的 goroutine,可能会影响内存的正常回收,甚至导致内存泄漏。比如,频繁创建新的数据库连接且未及时关闭,会导致网络相关的 goroutine 一直处于等待状态,占用内存资源。information_schema.statements_summary 表,查看在告警时间段内执行的 SQL 语句。某些复杂的 SQL,如全表扫描、大量数据的聚合操作等,可能会触发大量的 goroutine 来处理数据。如果这些 SQL 没有进行优化,或者执行过于频繁,就可能导致内存使用异常。sql
SELECT digest_text, sum_exec_count, sum_duration
FROM information_schema.statements_summary
WHERE query_time >= '开始时间' AND query_time <= '结束时间'
ORDER BY sum_duration DESC
LIMIT 10;
tidb_server_memory_limit、mem-quota-query 等。如果 tidb_server_memory_limit 设置过高,可能会允许 TiDB Server 使用过多内存,而 mem-quota-query 设置过低可能导致一些正常查询因内存限制而触发异常行为,间接影响 goroutine 的管理。sql
SHOW VARIABLES LIKE 'tidb_server_memory_limit';
SHOW VARIABLES LIKE'mem-quota-query';
go_goroutines(goroutine 数量)、process_resident_memory_bytes(进程常驻内存字节数)等。分析这些指标的变化趋势,结合告警时间点,判断内存增长与 goroutine 数量变化之间的关系。go_goroutines 指标在某个时间段内突然上升,同时 process_resident_memory_bytes 也随之增加,那么可以进一步深入排查在该时间段内发生的操作,如是否有新上线的业务功能导致了大量并发请求。promql
sum(go_goroutines{instance="tidb-server-ip:port"})
[image]
根据查询结果,结合业务请求量等信息,判断 goroutine 数量增长是否合理。
通过上述一系列具体的排查手段,基本可以定位到导致 tidb_memory_abnormal 告警以及可能存在的 goroutine 泄露问题的根源,进而采取针对性的优化措施,如优化 SQL 语句、调整配置参数或修复代码逻辑等。
嗯嗯,也尝试了,就是这个文件的结果,在学习中 ![]()
多谢回答,很好的参考,我了解下
TiDBer_sheldon 宣恩裕 回答的很靠谱,我也提升学习一下看看
我们一般遇到tidb内存高的原因,都是有大sql在tidb server聚合导致的。一般都是通过dashboard的慢查询来解决的。
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。