【TiDB 使用环境】生产环境
【TiDB 版本】5.2.3
新增一个 TIKV节点 ,REGION迁移了一天半 都是正常的,突然早上状态变为DISCONNETED ,崩溃前几分钟频繁报错
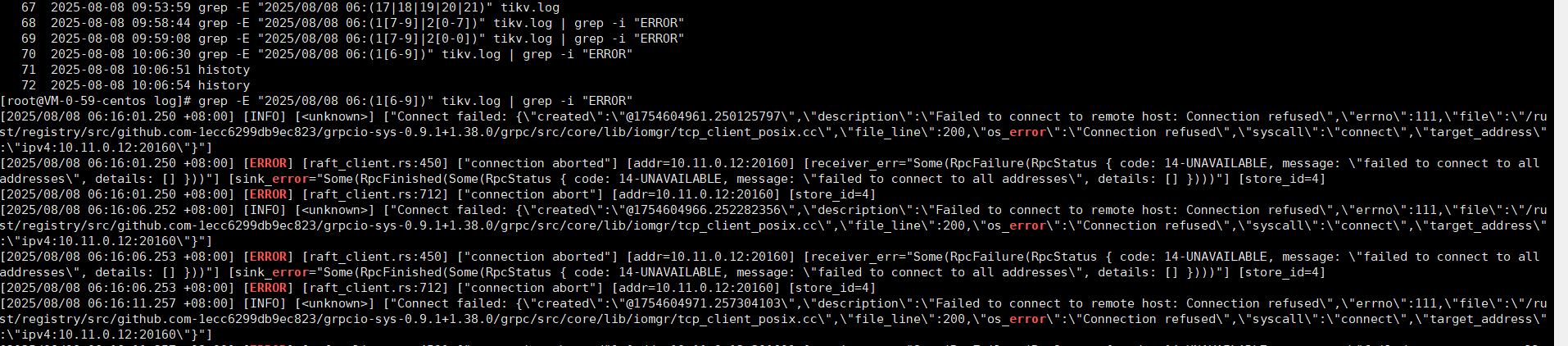
然后过了几分钟频繁报错
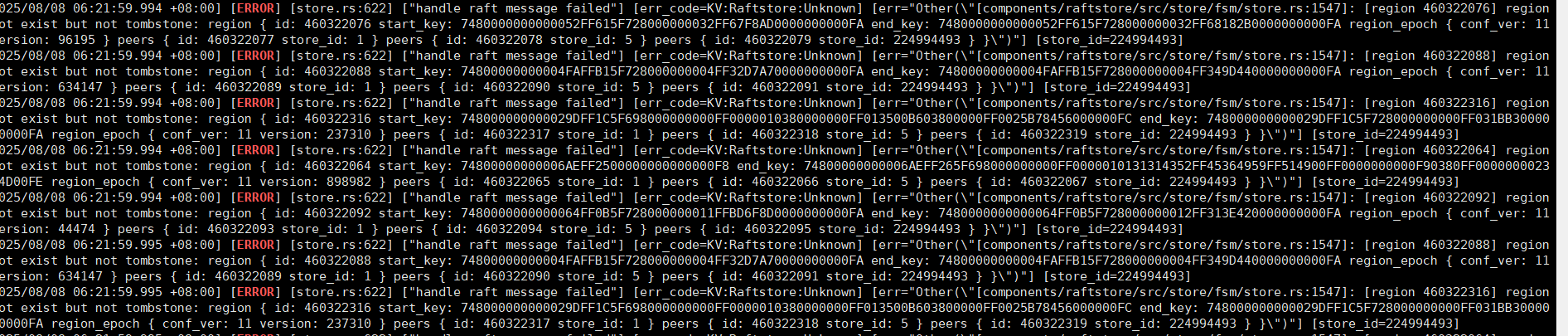
重启也起不来 显示DISCONNETED 这是啥问题嘛
error1.log (5.3 MB)
error3 (2).zip (7.6 MB)
【TiDB 使用环境】生产环境
【TiDB 版本】5.2.3
新增一个 TIKV节点 ,REGION迁移了一天半 都是正常的,突然早上状态变为DISCONNETED ,崩溃前几分钟频繁报错
从你提供的信息来看,新增 TiKV 节点在 Region 迁移过程中崩溃前出现报错,主要可从以下方面排查:
failed to connect to remote host: Connection refused 这类报错,说明 TiKV 节点之间、TiKV 与其他组件(如 PD、TiDB )之间网络连接存在问题。检查新增 TiKV 节点与集群内其他节点(PD、TiDB、已有 TiKV )的网络连通性,可使用 telnet、nc 等工具测试对应端口(如 TiKV 对外通信端口默认 20160 ),确认是否存在防火墙规则限制、网络 ACL 策略拦截、网络设备(交换机、路由器 )故障导致连接被拒。ping、mtr 等工具检测新增 TiKV 节点与 PD 节点、其他 TiKV 节点之间的网络质量。free -h 等命令查看 ),可能因内存不足导致进程崩溃、连接失败。结合你之前提到的内存相关问题,确认是否因内存限制不合理,导致 TiKV 无法正常分配内存处理 Region 迁移任务,可适当调整 TiKV 内存相关配置(如 storage.block-cache.capacity 等 ,但调整需谨慎,要结合节点实际内存大小 )。iostat -xdk 1 10 查看磁盘设备的 IO 统计信息 ),若磁盘 IO 使用率过高(如 % util 接近 100% )、磁盘带宽达到瓶颈,会造成 Region 迁移缓慢、甚至因磁盘繁忙无法响应请求而报错。同时检查磁盘剩余空间,若空间不足(比如低于 20% 可用空间 ),也可能影响 Region 数据的写入,导致迁移失败。tiup cluster display <集群名称> 等方式,确认新增 TiKV 节点版本与集群整体版本是否匹配,若不匹配,需考虑升级或降级节点版本(生产环境升级需提前做好备份、测试,避免业务影响 )。max-pending-peer-count 等参数设置不当,导致 Region 迁移任务积压 ),或 PD 自身存在性能问题(如 PD 节点内存不足、CPU 负载过高影响调度决策 ),会引发 Region 迁移异常。检查 PD 相关配置(可查看 PD 配置文件 pd.toml ),以及 PD 节点的资源使用情况(通过 top、htop 等查看 CPU、内存使用率 ),必要时调整 PD 调度参数(如适当调大 max-pending-peer-count 允许更多并行迁移任务,但要结合集群资源情况 )。pd-ctl )查看 Region 状态信息,检查报错 Region 的 peers 情况、leader 选举情况等,确认 Region 是否处于正常状态,尝试对异常 Region 进行修复(如通过 pd-ctl 触发 Region 同步、leader 重新选举等操作 ,但操作需谨慎,避免数据丢失 )。你可按照上述方向逐步排查,先从网络和资源方面入手(相对直观易查 ),再深入到集群配置、组件自身问题,结合具体报错信息和集群实际情况,定位并解决新增 TiKV 节点 Region 迁移报错的问题 。
我看了下我的内存 确实达到了 87% 和这个有关是吧
方便贴一下完整的日志吗
error1.log (5.3 MB)
我看这个日志只有6.30左右的。
重启时间是什么时候,重启是没有报错吗?
和内存应该无关的,还没到极限呢
那不是资源 怎么排查是其他问题啊
日志打印太多了 一分钟时间内日志就有100M
error3 (2).zip (7.6 MB)
怎么判断是PD调度策略与配置问题呢
这个日志里有一行是[signal_handler.rs:20] [“receive signal 15, stopping server…”]
查一下主机message日志,有没有oom关键字
messages (663.9 KB)
并没有OOM
我手动停止了 这台机器
kill -15杀的进程?
手动关机导致的?
没有 我用的STOP命令 就是因为 他崩溃了 我不STOP的话 系统就一直报错
tiup cluster stop tidb-cluster -N 10.11.0.59:20160
没崩溃吧?我看日志6:29是接收到的正常的关闭信号,是你手动stop的吗?
我6点29重启了一下这个节点,重启前状态是DISCONNETED