但是过一会他会自己恢复正常
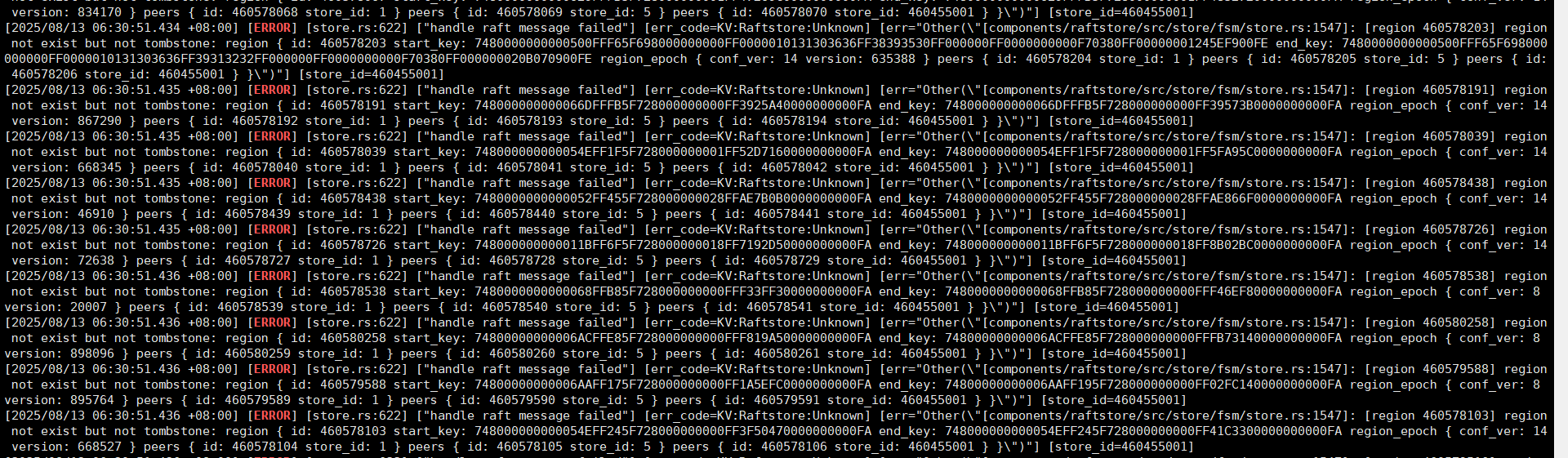
TIKV日志报错
生产群报警访问超时

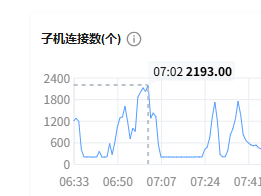
腾讯云监控子机连接数剧增,正常是几百
看你的日志里主要原因是“region not exist but not tombstone”,可能跟分布式一致性协议和数据分区有关,当region自动合并或者分裂的时候,如果其他region正在进行这些操作时,可能会出现短暂的不可用状态,建议你在等待期间,执行pd-ctl region merge-check命令来检查region的状态,确认是否有其他正在进行的合并或分裂操作。
当时应该是有的,但是 我怎么 避免呢 还报下面的错误INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29283987]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29283992]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284030]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284040]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284041]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284334]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284335]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284347]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284377]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284378]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284387]
[2025/08/14 06:20:29.646 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284418]
[2025/08/14 06:20:29.647 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284432]
[2025/08/14 06:20:29.647 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284436]
[2025/08/14 06:20:29.647 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284454]
[2025/08/14 06:20:29.647 +08:00] [INFO] [scheduler.rs:458] [“get snapshot failed”] [err=“Error(Request(message: "peer is not leader for region 219075885, leader may None" not_leader { region_id: 219075885 }))”] [cid=29284456]
还有这个错误
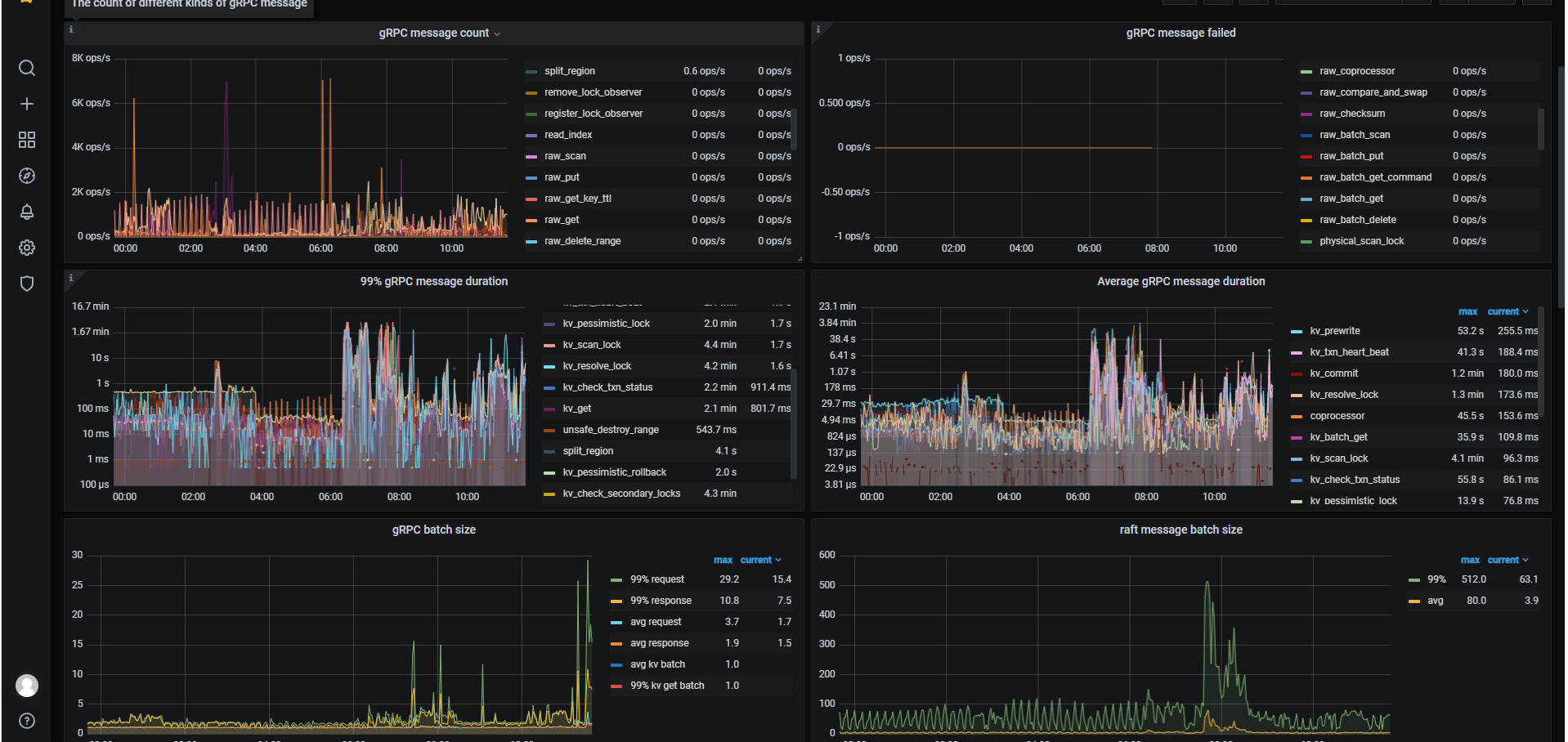
看起来是网络问题,查下 gRPC 是否被打满了
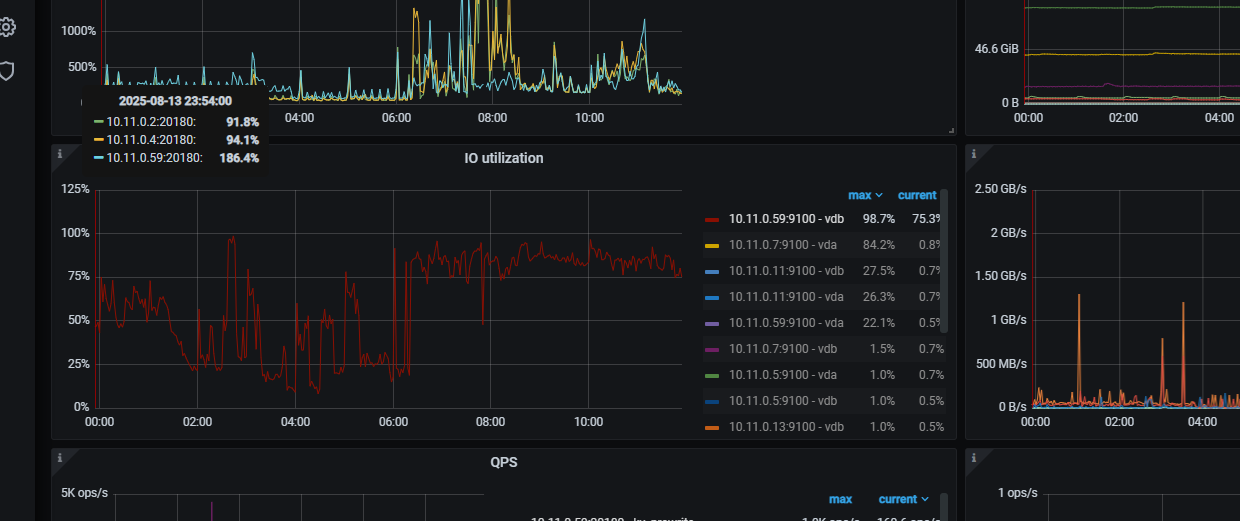
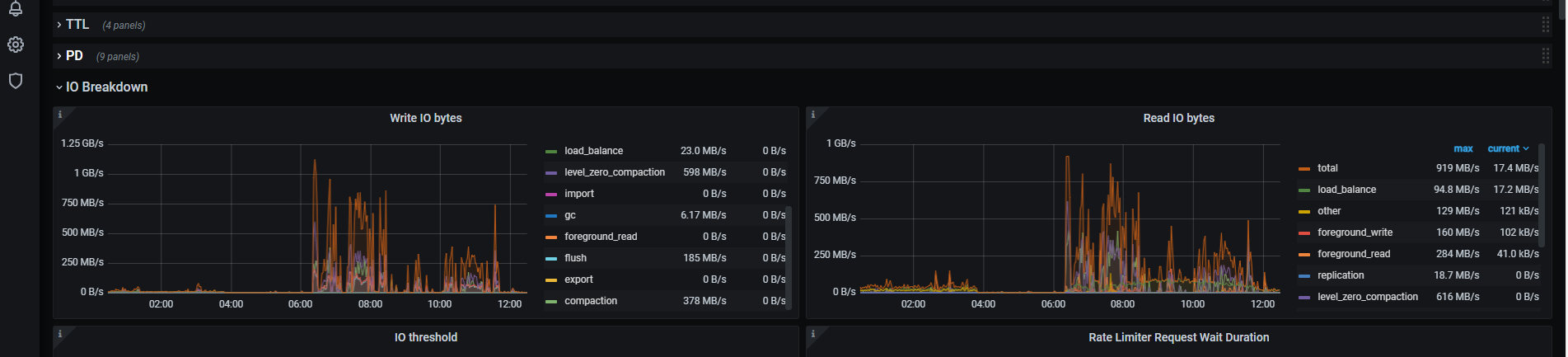
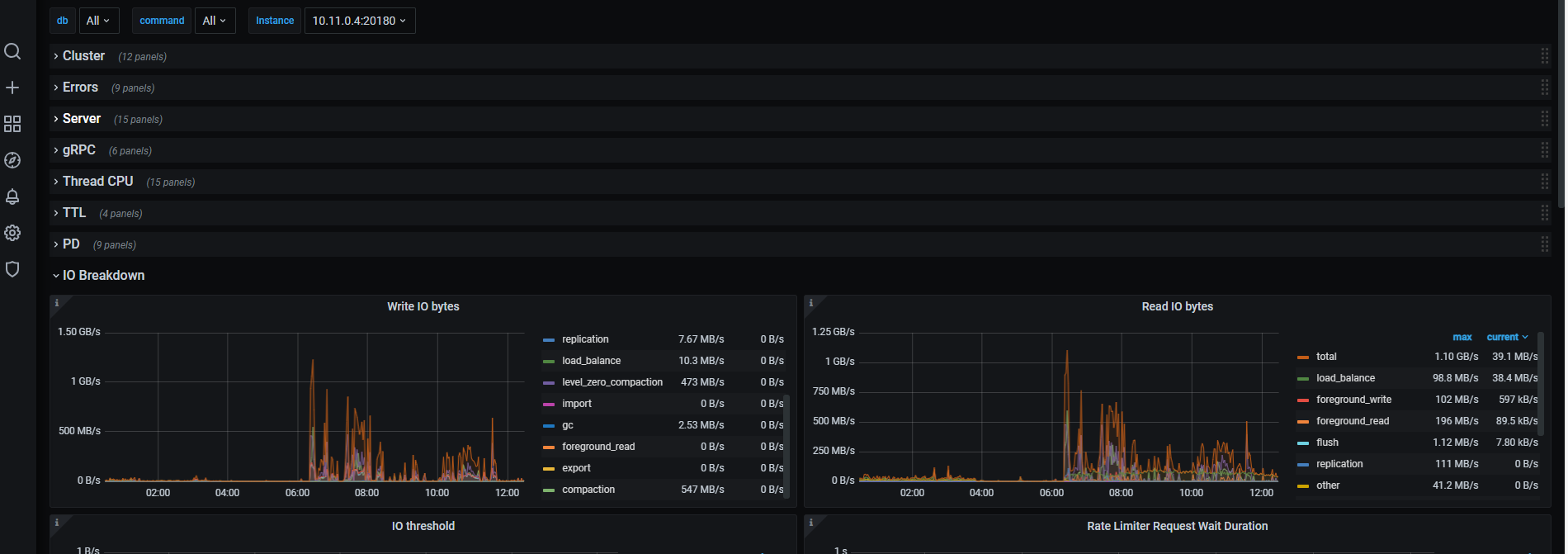
峰值到 1.6 min, 继续检查 磁盘 IO 的情况,同一时间
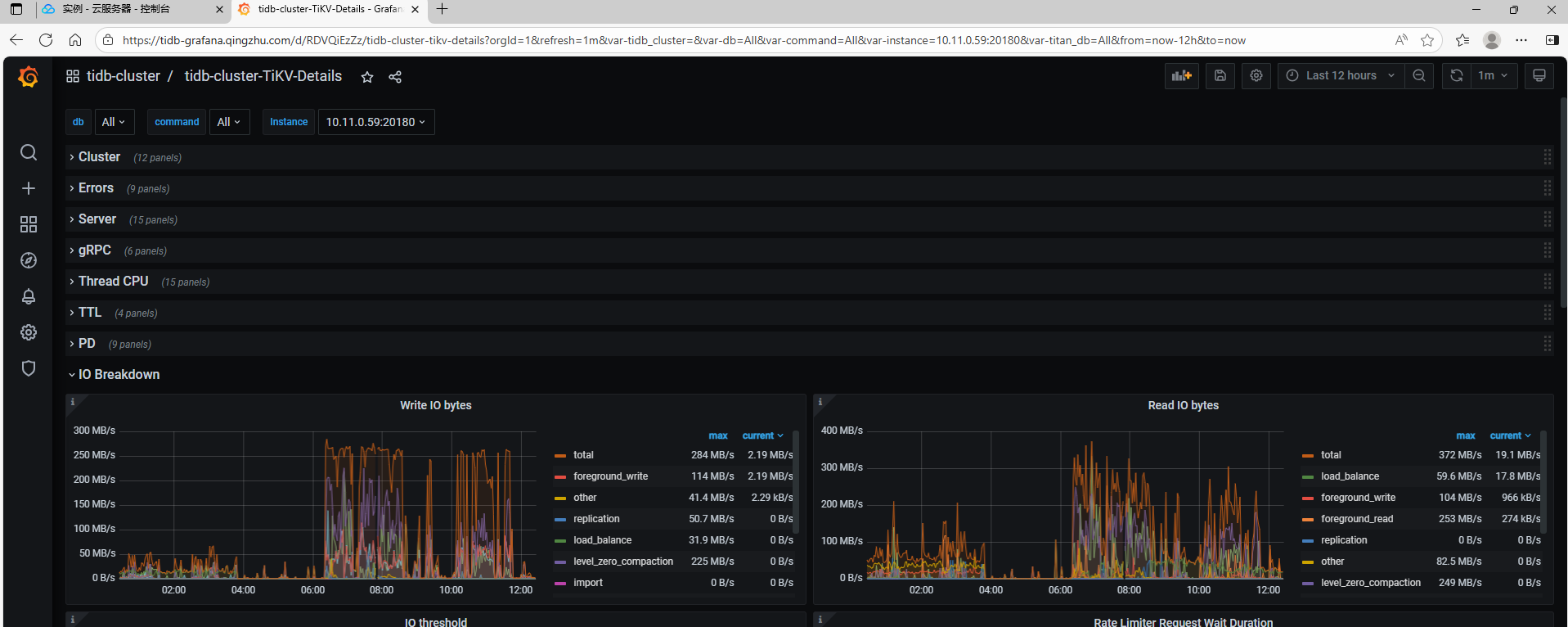
也是用GRAFANA看嘛
yes, pls check it with grafana in the different module
对,看看各个 tikv 的 IO 是否正常。在那个峰值时间周期内
2 和 3 节点会比较热,读写都到了 GB级了,
磁盘硬件最高能支持到这个规模的读写的 IO 么? 不行的话,会有延迟了。
2 3是没问题 的 就是1 有问题 1的配制比较低
我说的报错 就是1这个节点 点上的日志,超时也是1这台机器
难怪了,配置要一样才可以。不然就是木桶短板了
木桶最短的一块板,限制装水的能力
那这种有临时解决方案嘛
没,这是规划就要考虑清楚的
公司想降本 就想着一台一台这样换上去 ![]()
降本降的服务器配置很差?盘至少得 ssd 的。尤其看起来你们业务压力还是蛮高的。