
我记得pending-peer-region-count、extra-peer-region-count 这几个我记得之前都是0的。现在都涨了。这个有问题吗
做过的操作:上周缩容1台机器,然后扩容一台机器。没有做其他操作了。

我也看过这个文档,就是不太理解他说的 如果持续很高。这个很高是多少。我这里是一只是3-5.对于之前一直是0来说 应该是高了吧。 ![]()
应该算很高了,不减少
之前max是4k,现在是3,应该是降低了,剩下这个3个可能是learner吧?


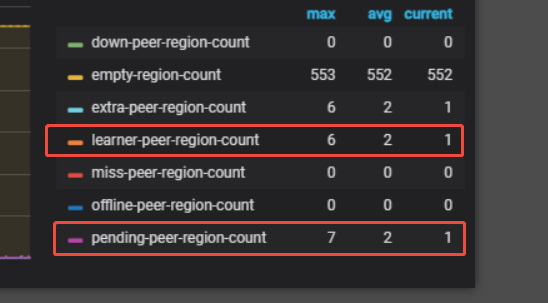
这个pending还真有可能就是指的tiflash的副本和tikv的有差距。不过才几个,应该是正常范围内。
https://docs.pingcap.com/zh/tidb/stable/glossary/#pendingdown

应该是扩缩容那个时间点的吧。
我这没有tiflash。一闪而过的。时间点差不多就是我扩容、和缩容的时间,但是也几个不是执行扩容缩容的时间点。那按照这个理解,就是我tikv服务器写入速度慢。也会导致有pending,写入速度慢,导致follower的raft log和ledaer有一点差距
![]() 不可能吧,learner就是tiflash啊。会不会是之前有,但是强制下线了?
不可能吧,learner就是tiflash啊。会不会是之前有,但是强制下线了?
个位数的话感觉不影响,可以进入pdctl命令行
使用region check miss-peer等命令检查各种异常peer的情况
1 个赞
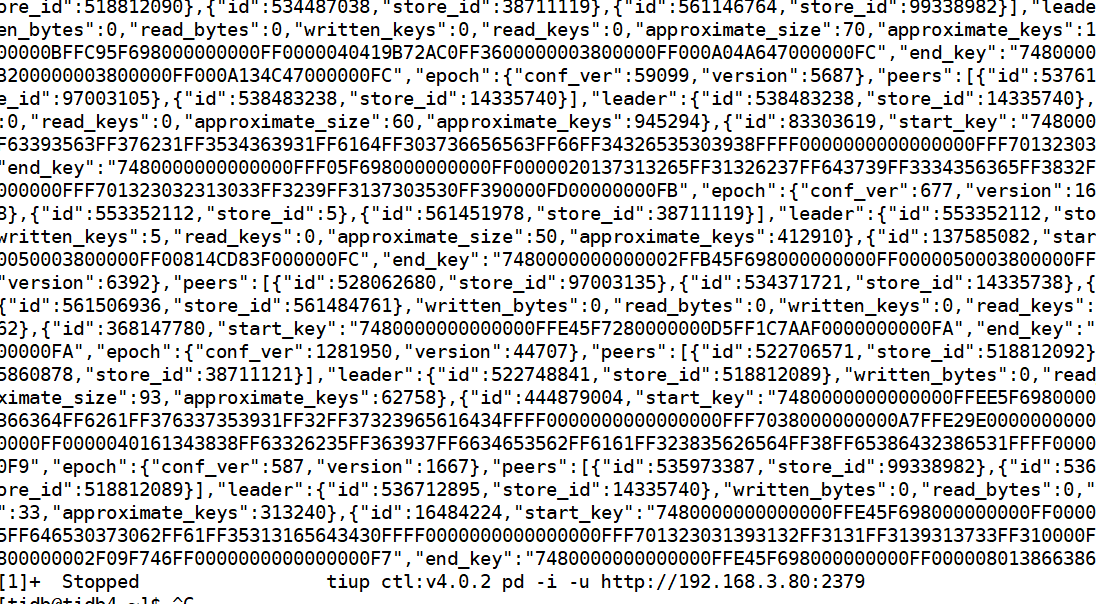
https://docs.pingcap.com/zh/tidb/v6.5/pd-control/#region-check-miss-peer--extra-peer--down-peer--pending-peer--offline-peer--empty-region--hist-size--hist-keys---jqquery-string
我的意思你检查你异常的region情况,但是你监控上miss-peer是0啊,
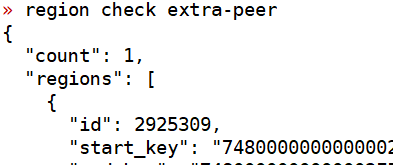
region check pending-peer或者region check extra-peer
你执行这个呢?
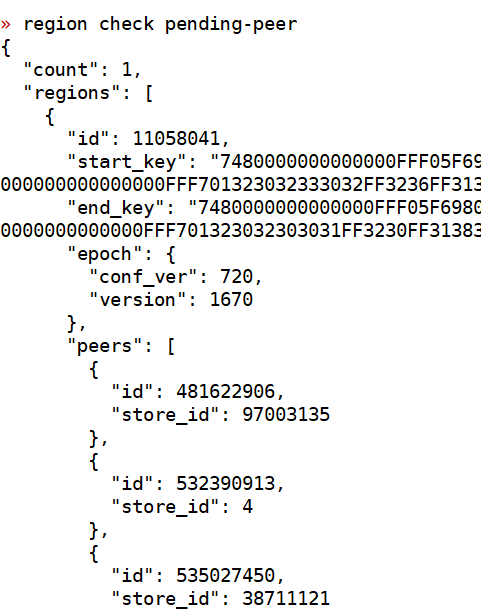
找到对应的region之后,可以去information_schema.tikv_region_status里面看下对应的是哪个表,确认下使用没问题就行了,因为你的region都是3副本的,如果其中有一个副本Pending了,或者例如调度出错,多了一个副本,自动调度会很快补充异常的副本或者删除多出的副本,所以一会是0,一会有数据
他会一直变。前一秒差的region id 是1.手动去navciate登录检查他就是3个副本。正常的。再去pdctl里面检查就是0 。在检查他就是region id 2了。对应的表也是不一样的。可能就是因为一直在调度,一直在转移peer产生的。
我直接手动在navicate里面gourp by region_id 也能看到有4副本的。再查他就变了。
我感觉不太需要处理这点数据,不影响使用。如果有长期缺失副本,或者多副本,或者pending副本,再通过ptclt去人工干预即可。