【TiDB 使用环境】生产环境
【TiDB 版本】tidb-5.4.0
【操作系统】cenos 7.9
【部署方式】AWS EC2 自建 8c 32G 1.5T SSD(什么机器配置、什么硬盘)
【集群数据量】1 套集群
【集群节点数】
3 个 tidb-server
3个 pd-server
3个 tikv-server
2 个tiflash
1个tiup 管理服务器(包括:prometheus、grafana、alertmanager)
【问题复现路径】
【遇到的问题:问题现象及影响】
1、新接手服务器,运维人员手动修改过 3 个 tikv 的 date,
3、tidb-server-01~03 的log 中出现比较频繁的 ERROR

4、tikv-03 的 log 中出现大量的 [WARN] [kv.rs:1092] [“call CheckLeader failed”] [err=Grpc(RemotStopped)] 的告警

5、tiup 管理机有周期性的高IO,经过排查监控如下:
(1)grafana 监控:

(2)top
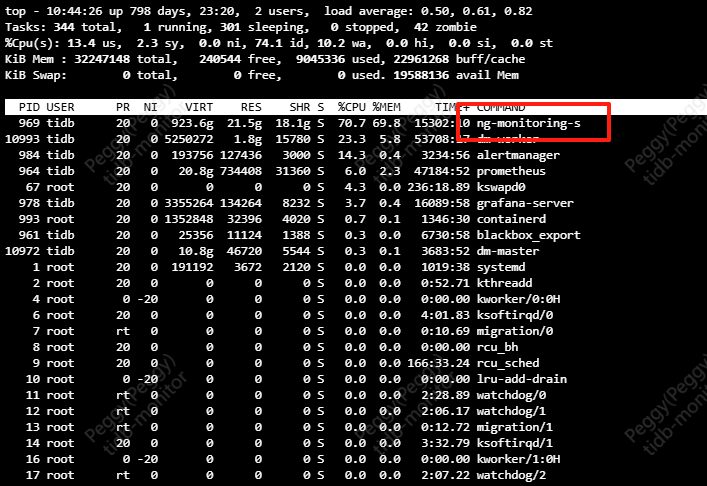
(3)进程:

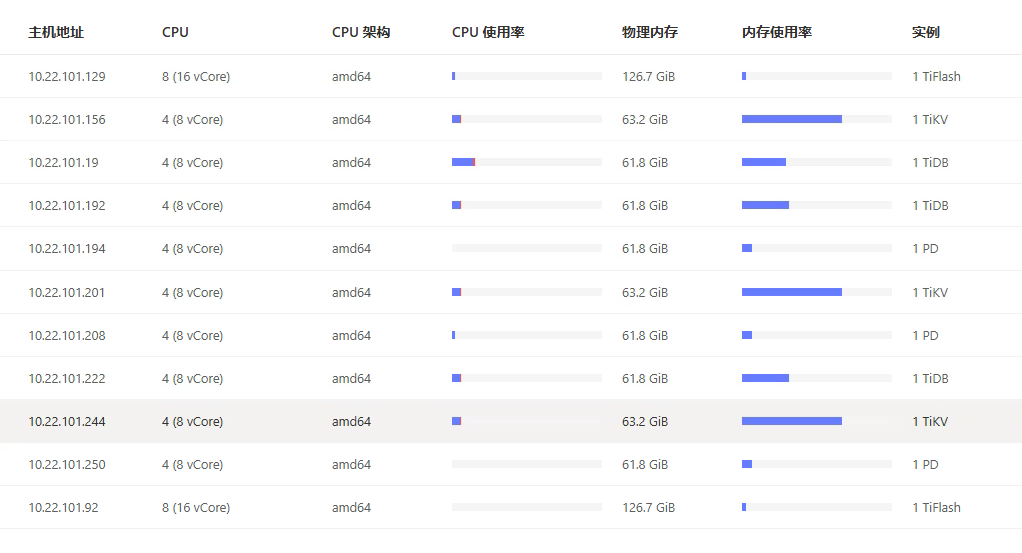
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面