【TiDB 使用环境】生产环境
【TiDB 版本】V8.1.0
【操作系统】BCEuler-21.10
【部署方式】云上部署
【集群数据量】21
【集群节点数】13
【问题复现路径】
【遇到的问题:问题现象及影响】
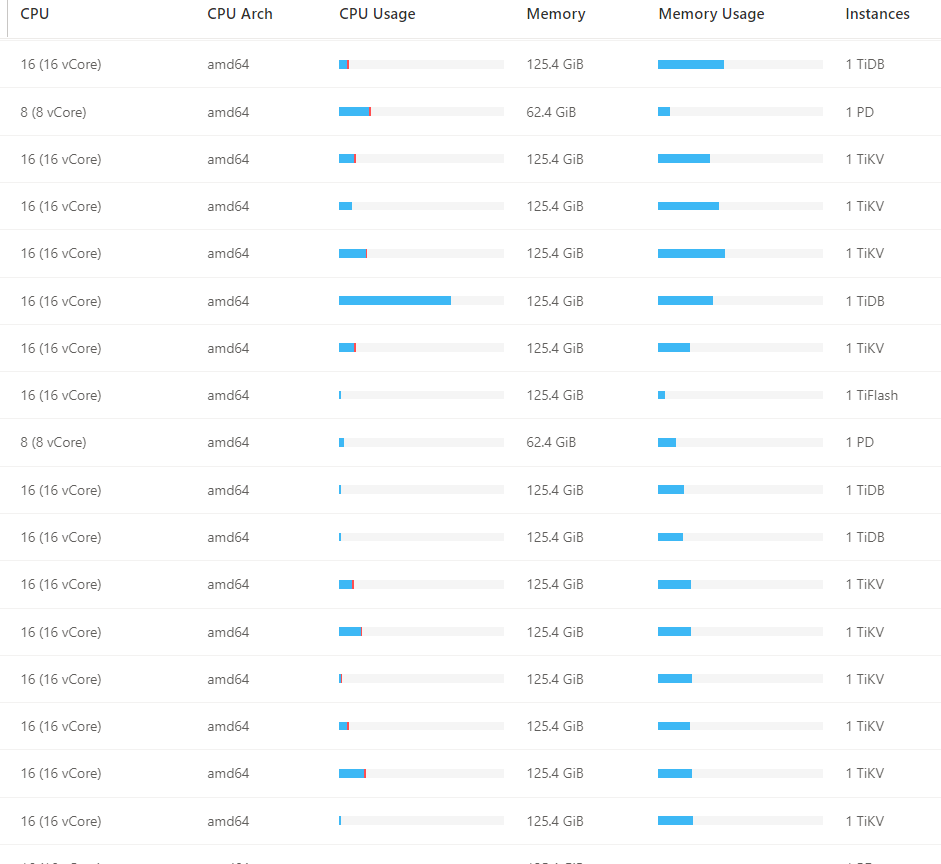
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
[2025/08/18 20:43:09.324 +08:00] [ERROR] [gc_worker.go:744] [“resolve locks returns an error”] [category=“gc worker”] [uuid=662377be638000a] [error="epoch_not_match:<> "]
【其他附件:截图/日志/监控】
有猫万事足
3
这个错误一般来说不严重,如果是region正好在分裂或者合并都会有这个报错。仅从这个报错不能充分的证明gc被卡住了。
建议查一下grafana 上的 tikv-details->GC->TiKV auto GC safepoint, 观察 gc safepoint 推进是否符合预期。这个才是决定性的gc卡住的证明。
Liucy
(Liucy)
4
默认情况下GC 每10分钟执行一次。。检查一下日志
xfworld
(魔幻之翼)
7
1 个赞
lllzd
(时光旅行者)
9
看日志报了一个TiDB集群在GC过程中出现的常见错误,虽然日志类型为error,但在某些场景下属于可恢复的临时性错误,不一定表示集群处于严重故障状态。
system
(system)
关闭
13
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。