【TiDB 使用环境】生产环境
【TiDB 版本】8.1.0
【部署方式】纯内网部署
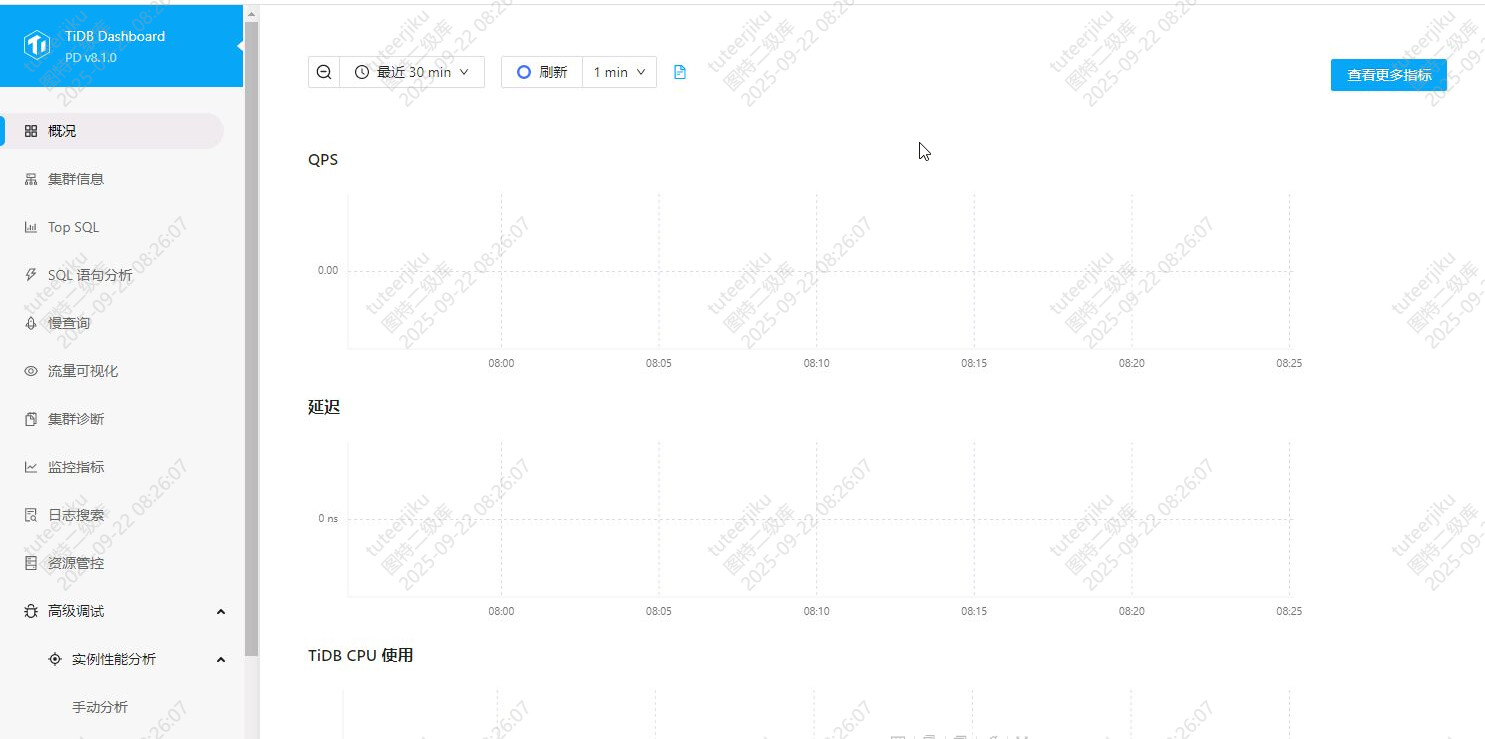
生产环境DashBoard面板没有数据,所有节点的组件(PD、KV、TIDB我都挨个看过了,普罗米修斯跟Grafana也看过了)没有发现ERROR日志,所有节点组件状态正常,F12看网络请求有404报错,请问各位专家这是怎么回事?
1 个赞
别的面板或者界面的数据,指标正常么?还是所有的都不行?
你可以看下PD Leader 是哪个节点,看看上面的日志
1 个赞
怎么部署的集群?是标准部署吗?感觉有点像微服务部署找不到微服务了
https://docs.pingcap.com/zh/tidb/stable/tiup-cluster-topology-reference/#scheduling_servers
单独访问pormetheus 的监控页面数据正常吗?
1 个赞
是不是prometheus设置 Basic Auth 了
1 个赞
我看了就是所有的折线图都没有数据。流量可视化、慢sql等模块都有数据。
所有的PD节点日志没有ERROR级别的日志。
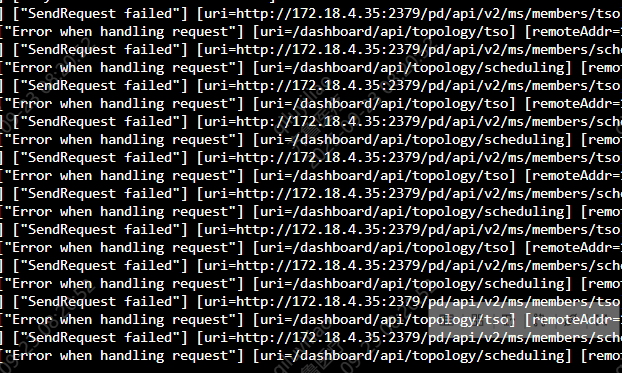
警告级别的日志就是:
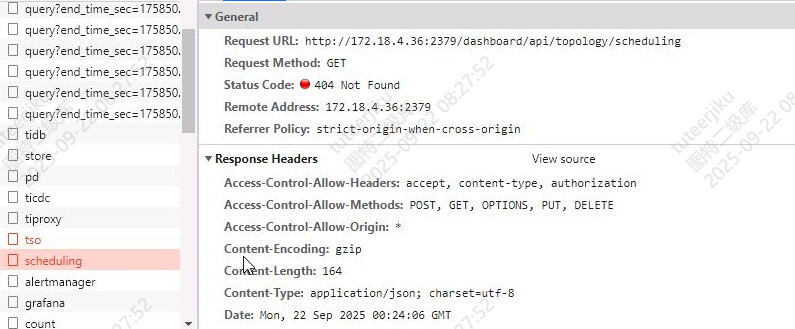
[2025/09/22 10:27:09.517 +08:00] [WARN] [client.go:121] [“SendRequest failed”] [uri=http://172.18.4.36:2379/pd/api/v2/ms/members/scheduling]
[2025/09/22 10:27:09.517 +08:00] [WARN] [error.go:89] [“Error when handling request”] [uri=/dashboard/api/topology/scheduling] [remoteAddr=172.18.3.99:60547] [errorFullText=]
[2025/09/22 10:27:11.297 +08:00] [WARN] [client.go:121] [“SendRequest failed”] [uri=http://172.18.4.36:2379/pd/api/v2/ms/members/tso]
[2025/09/22 10:27:11.297 +08:00] [WARN] [error.go:89] [“Error when handling request”] [uri=/dashboard/api/topology/tso] [remoteAddr=172.18.3.99:60549] [errorFullText=]
[2025/09/22 10:27:11.298 +08:00] [WARN] [client.go:121] [“SendRequest failed”] [uri=http://172.18.4.36:2379/pd/api/v2/ms/members/scheduling]
[2025/09/22 10:27:11.298 +08:00] [WARN] [error.go:89] [“Error when handling request”] [uri=/dashboard/api/topology/scheduling] [remoteAddr=172.18.3.99:60548] [errorFullText=]
[2025/09/22 10:28:23.795 +08:00] [INFO] [grpc_service.go:2115] [“updated gc safe point”] [safe-point=460982164819279872]
应该就是我F12看到的失败的请求。
1 个赞
请求失败,数据的问题?
1 个赞
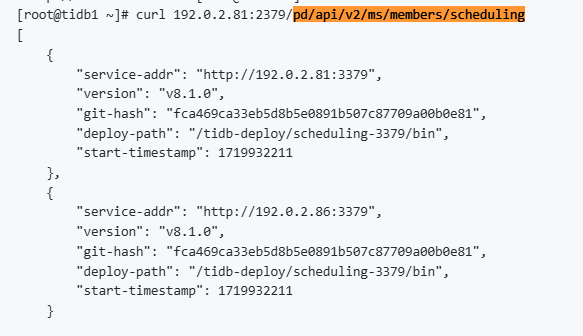

这是在PD主节点直接请求的
1 个赞
这么奇怪,切换下试试看
https://docs.pingcap.com/zh/tidb/stable/dashboard-ops-deploy/#切换其他-pd-实例提供-tidb-dashboard-服务
1 个赞
确认tidb-dashboard是否正常运行,查看进程状态。若进程异常,重启服务后观察是否恢复。
2 个赞
![]() 是不是防火墙限制了访问?
是不是防火墙限制了访问?
可以排查
我觉得您说的很有可能,但是几个节点的防火墙都是关闭的,如果有限制只可能是中央机房统一配置的安全策略限制了。我如何确定是那个IP跟端口的策略限制导致的呢?因为我是直接在dashboard所在的PD节点做请求都是出错的
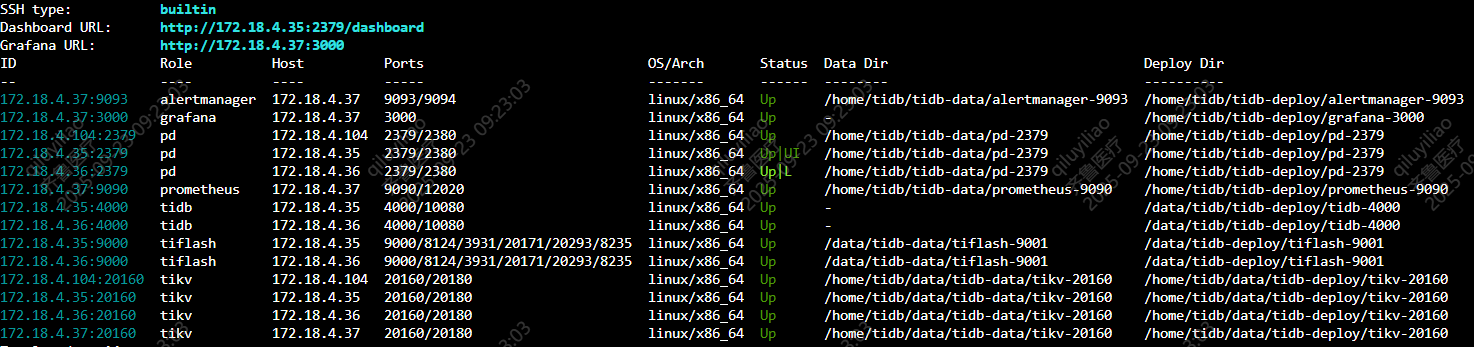
首先ip+端口应该是开放的,因为如果ip+端口不开放,集群应该是会报错。tiup cluster display看一下集群各组件状态是不是正常的?
本地访问也报错?集群是怎么部署的?tiup还是k8s?不会真的是缺少组件吧。
所有节点的所有组件log无ERROR,发现的WARN日志也就是题中访问Dashboard的请求出错。
本地tiup部署标准集群,
生产环境用了一年了,周末的时候重启了一下dashboard就看不到数据了
让 infra team 帮助跟进吧,你自己来排查就需要网络工具了,需要很熟悉哪些infra 的基础设施才可以,不限于网络交换机,路由器,防火墙之类的…
这个是重启的服务器,还是通过tiup cluster restart 重启某个组件?