三十柒号
(Ti D Ber I9h Npype)
1
【TiDB 使用环境】生产环境,没有使用tidb,只用了tikv
【TiDB 版本】5.0.0
【操作系统】Linux x86_64 3.10.0-957.el7
【部署方式】物理机部署(内存256GB, cpu 80, 系统盘hdd, 数据盘nvme)
【集群数据量】58TB,100.3w Region
【集群节点数】3个,每个节点7个 tikv实例
【问题复现路径】使用pump和drainer同步数据
【遇到的问题:问题现象及影响】
生产有个 Tikv 集群,3个节点,每个节点7块nvme,部署7个tikv store。
这个集群是用来做备集群的,用pump和drainer在做数据同步。写入量大概在1k qps。
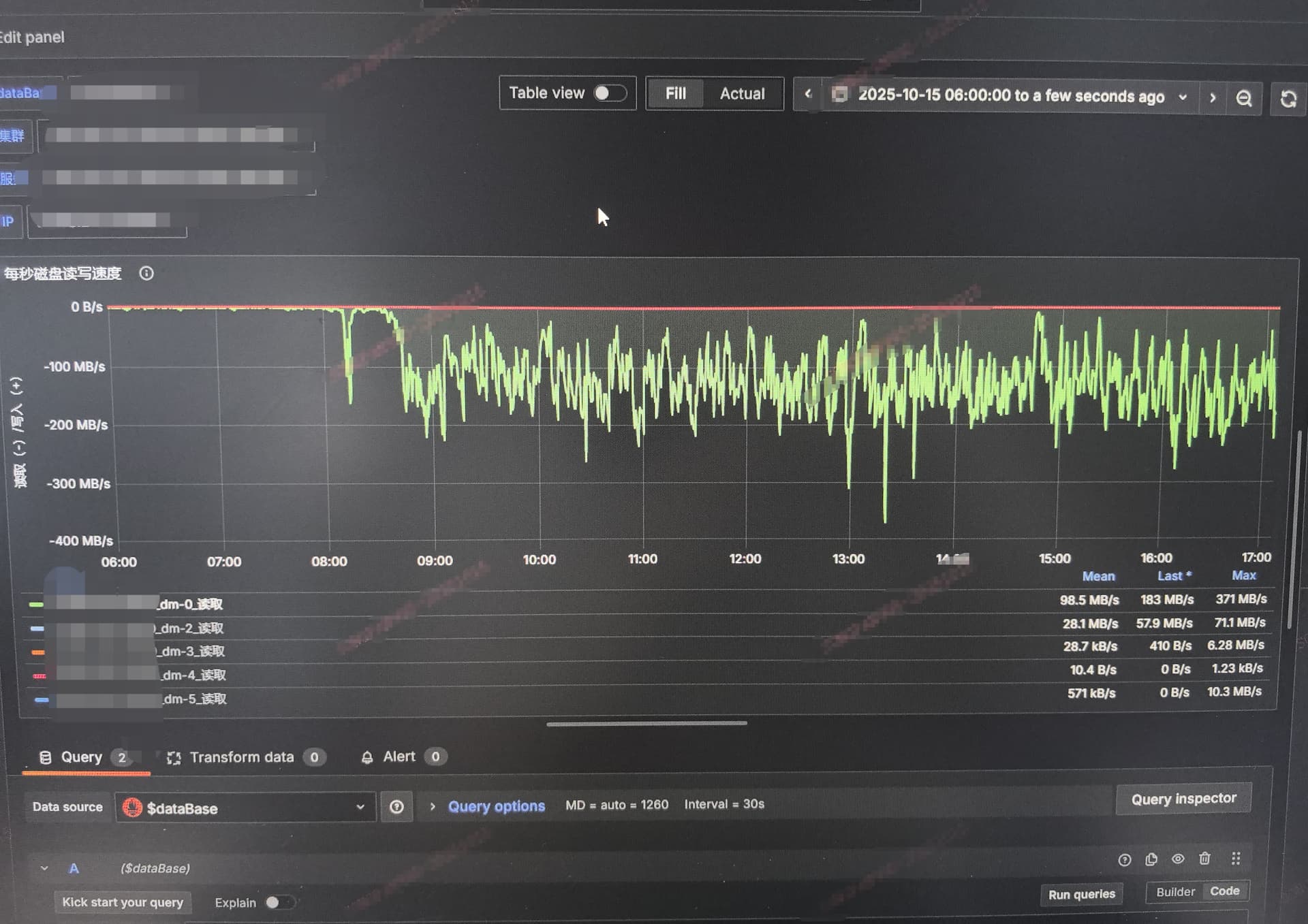
然后,有个节点特别奇怪。运行一段时间,根分区(/)dm-0 读带宽会突然变高(200+MB/s),节点登录会变卡,命令执行也变卡。只有系统盘会卡,数据盘不受影响,tikv本身的业务是正常的。
看到监控,读流量出现时,节点会突然出现大量的 MajorPageFault,看了 /proc/stat 确实是 tikv 进程在猛增,怀疑就是 tikv 缺页导致一直在读数据到内存。
但 tikv 是单独挂的数据盘,理论上不会读取根目录dm-0分区的数据,也不会持续产生200MB/s的带宽。
其他发现:
-
通过bcc的filetop,看到tikv只读了数据盘文件(SST、log等)
-
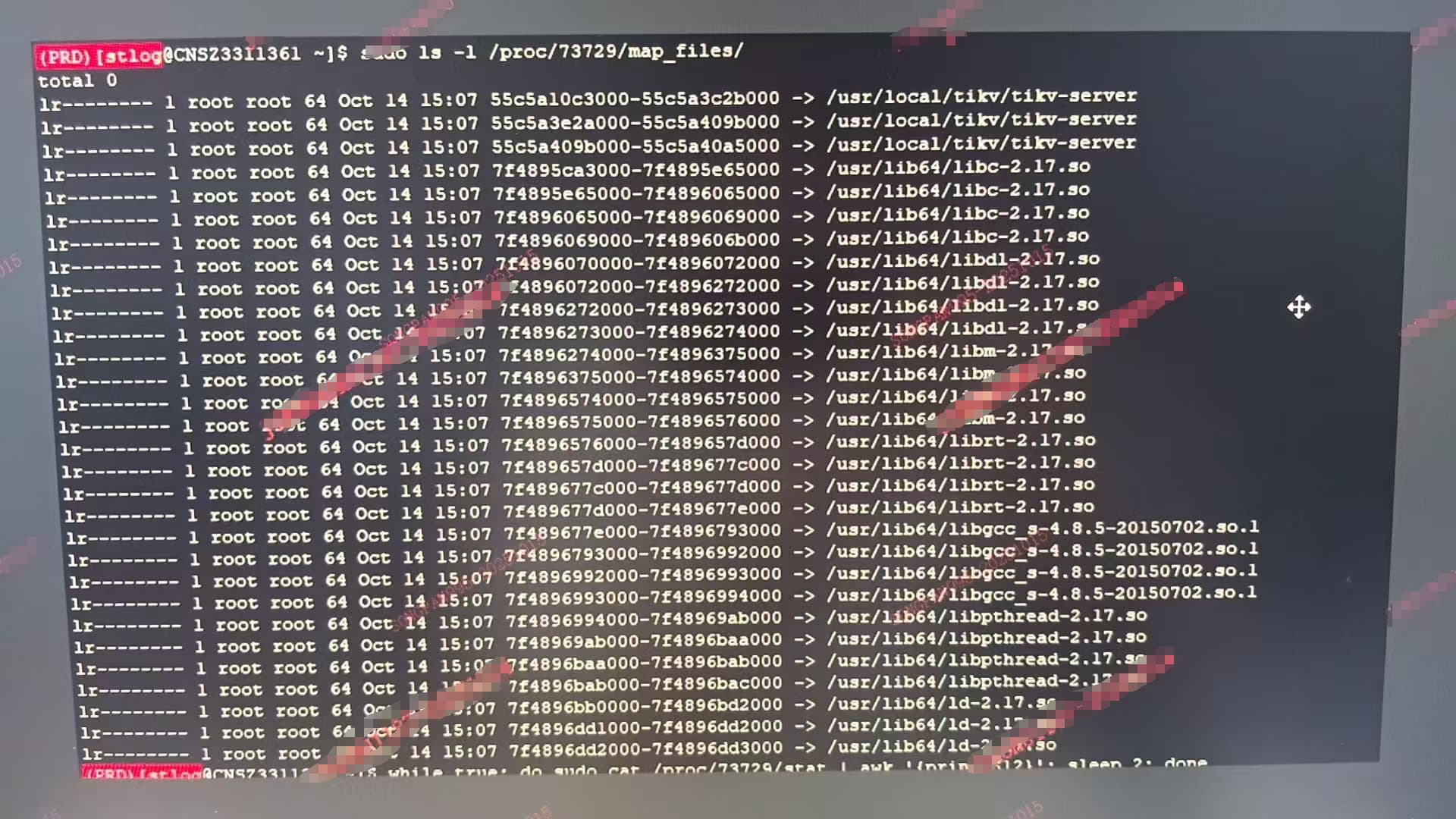
mmap仅映射了二进制文件(tikv-server)和一些lib.so文件,这些确实都在dm-0,但不大可能产生这么大且持久的流量
-
节点内存充足,没有swap使用情况
-
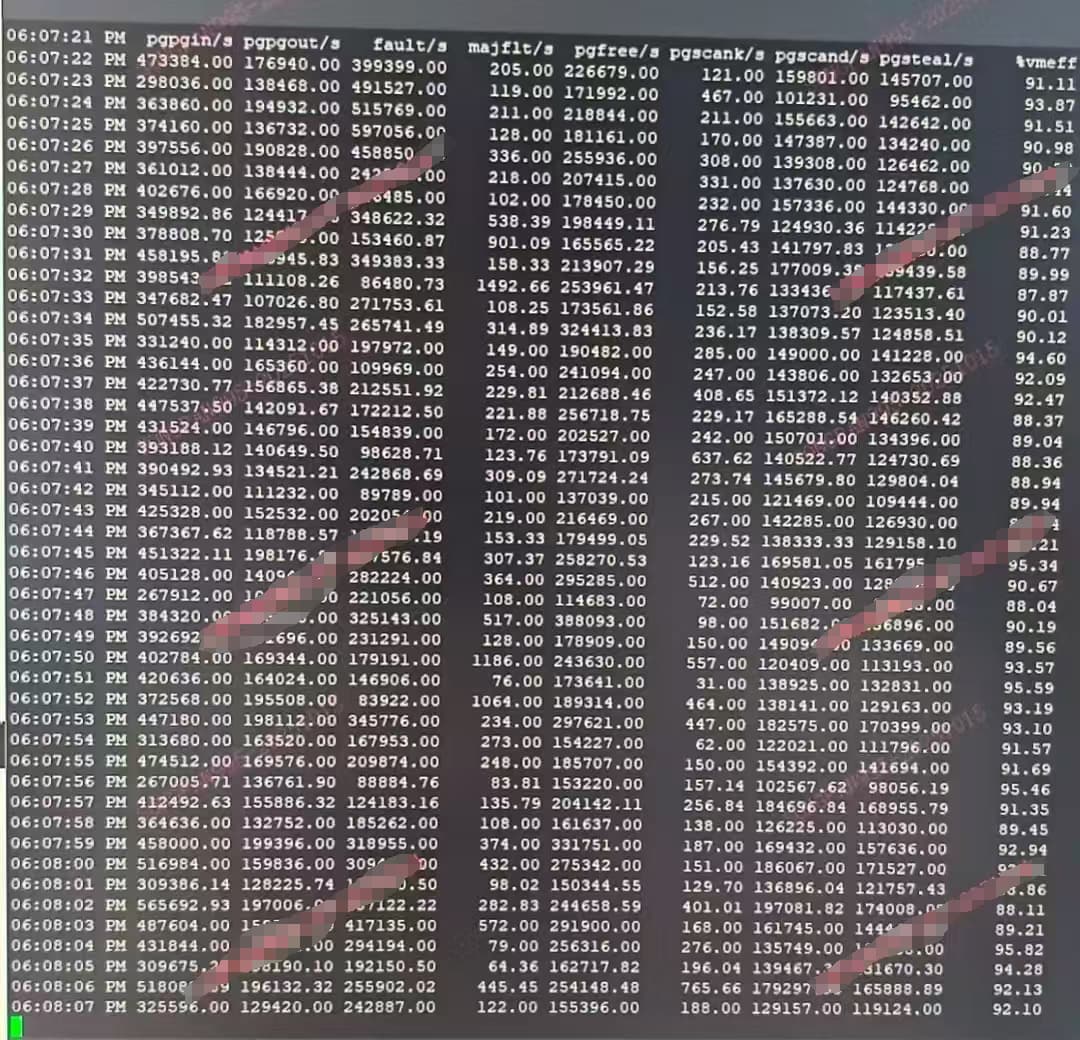
sar看到节点持续发生大量内存回收,pgscank/s达到300,正常节点为0
-
停止drainer,集群业务没了后,读流量会消失,但再启动后,经过一段时候,又会出现;
任意重启一个tikv实例(一共7个),流量会消失,同样过一段时间后,又会出现
-
perf工具看到的 page fault应该都是mmap的匿名页
各位大神,帮忙看下有没有类似的问题出现过,tikv的内存管理是不是会导致类似的问题。
1 个赞
lllzd
(时光旅行者)
2
建议先排查临时文件是不是落在了HDD系统盘上,所以在同步过程中引发大量 I/O操作,导致系统卡顿?
1 个赞
三十柒号
(Ti D Ber I9h Npype)
3
用 filetop 和 fuser 看了,没有看到 tikv 有读系统盘下的临时文件。除了一个占用端口的锁文件
1 个赞
WalterWj
(王军 - PingCAP)
4
卡的盘上面有部署什么 tidb 相关东西么?如果有,感觉可以考虑换个目录?试试呢 
1 个赞
三十柒号
(Ti D Ber I9h Npype)
6
系统盘上面没有部署tidb的东西,这个节点只部署了tikv
1 个赞
三十柒号
(Ti D Ber I9h Npype)
7
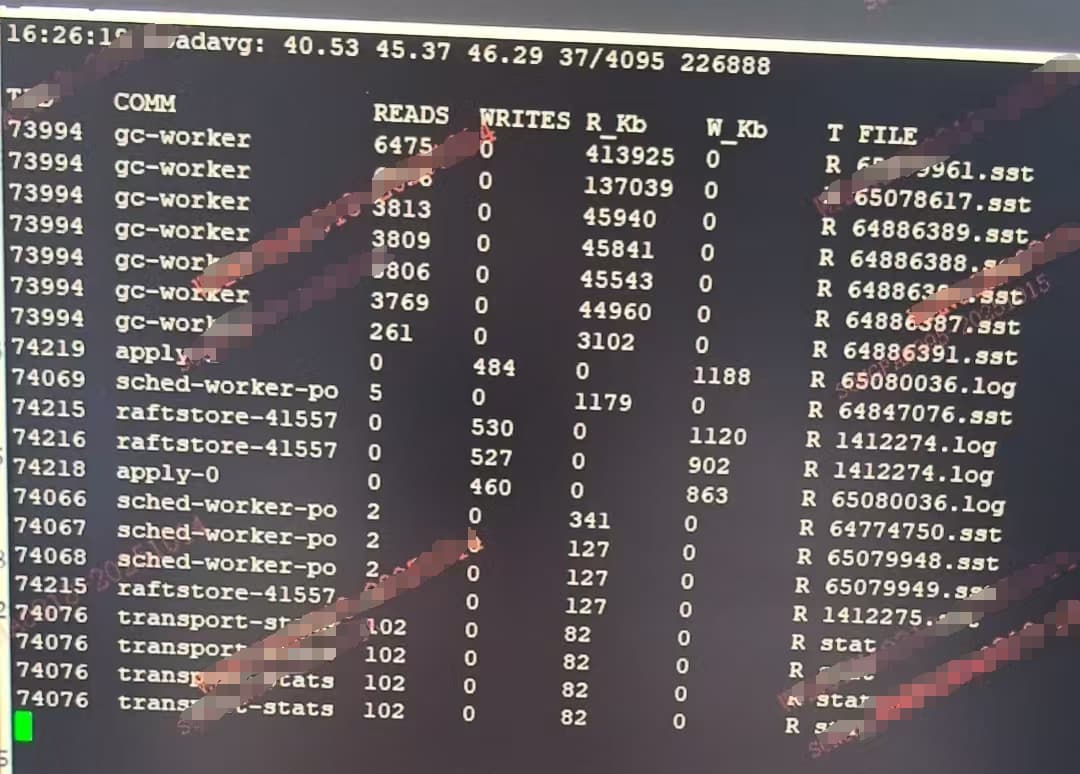
更新一下进展,使用biosnoop分析后,发现系统盘的读流量确实是tikv产生的。
下面这些线程都会读:
rocksdb:low
gc-worker
raftstore-4155
grpc-server
region-collect
tso
但这很奇怪,tikv为什么会读系统盘,而且还会产生这么大的流量 
1 个赞
三十柒号
(Ti D Ber I9h Npype)
10
再更新一下进展。
dmesg发现持续有内存分配失败的日志。
节点内存还有100多GB,但是碎片化很严重,连4个连续的16KB页都分配不出来了。
用compact_memery手动整理后,效果不好,并且整理出来的内存页,会马上被消耗完。
1 个赞
WalterWj
(王军 - PingCAP)
11
三十柒号
(Ti D Ber I9h Npype)
12
从64MB调整到2GB了,没有效果,内存碎片化还是很严重,系统盘读流量还是有
WalterWj
(王军 - PingCAP)
15
试试服务器做一次重启。
然后按照这个文档检查下:https://docs.pingcap.com/zh/tidb/stable/check-before-deployment/,系统配置调整有没有做,比如大页等。
min_free_kbytes 可以调整到 4GB。
tikv 会缓存占用较大内存,但是频繁触发内存碎片话整理是不常见的。
三十柒号
(Ti D Ber I9h Npype)
16
重启tikv进程的话,直接就恢复了,异常流量会消失。
现在是想定位根因,不去恢复。
大页一直设置的never。
三十柒号
(Ti D Ber I9h Npype)
20
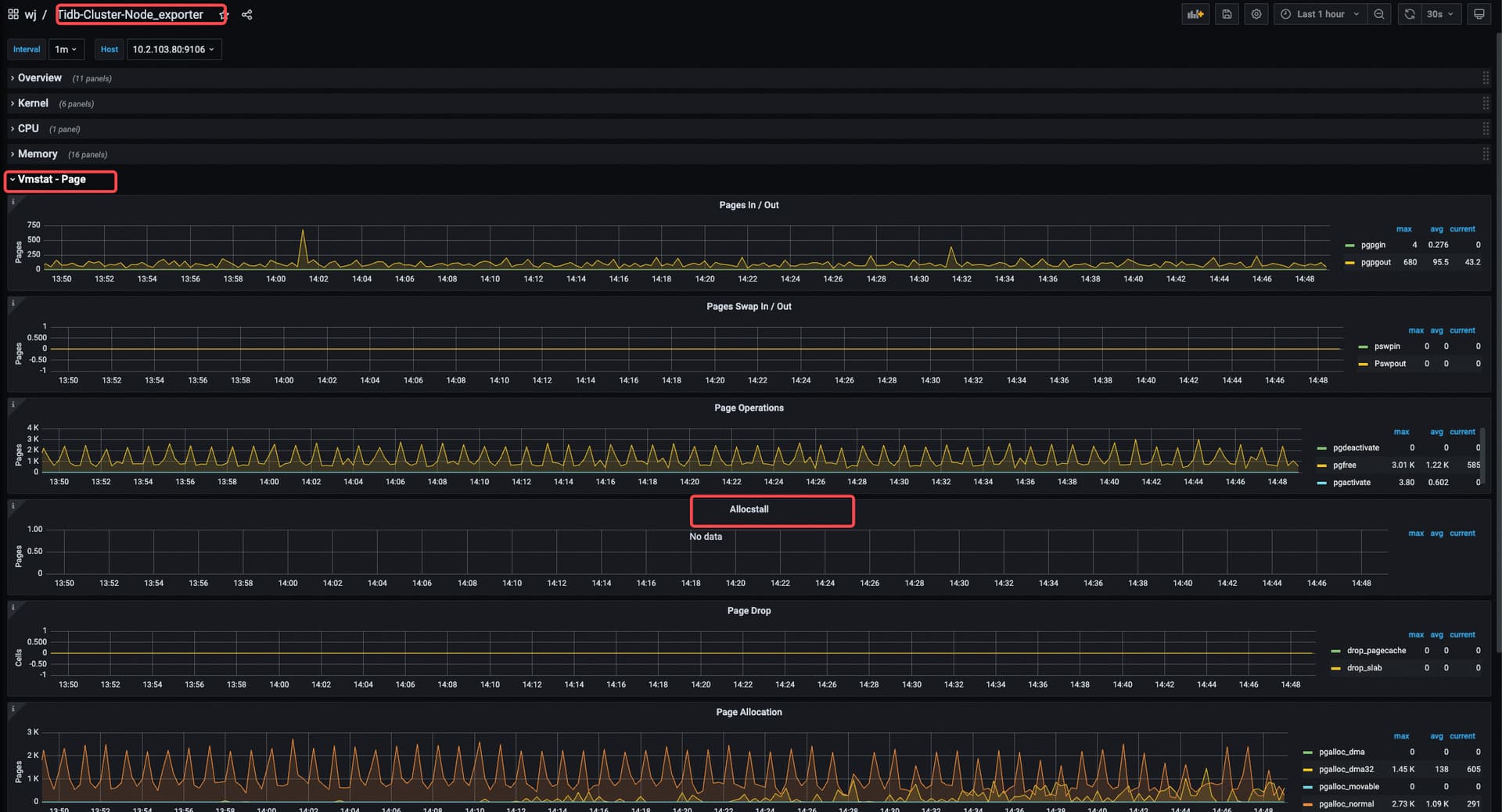
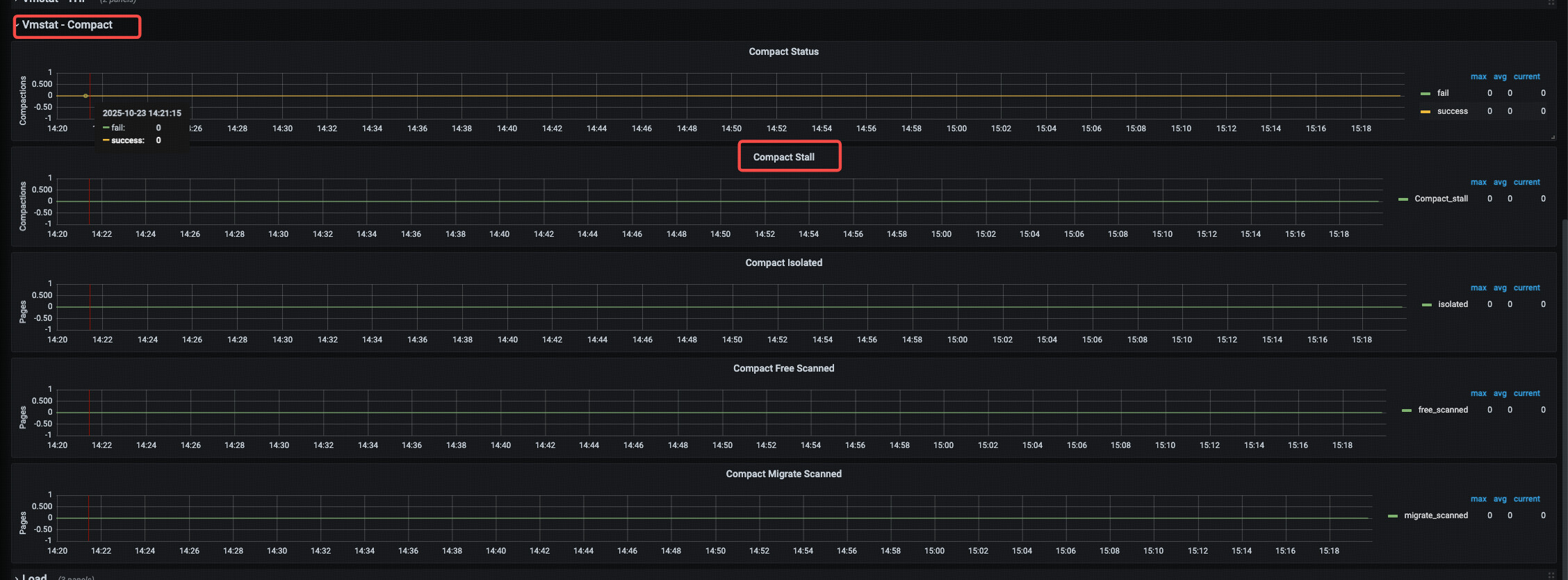
也没有数据,我们的node exporter版本太低了