【TiDB 使用环境】生产环境
【TiDB 版本】V8.1.0
【操作系统】rocky linux
【部署方式】机器部署(16C 32GB 1TB)
【集群数据量】1
【集群节点数】3
【问题复现路径】
【遇到的问题:问题现象及影响】从 INFORMATION_SCHEMA.cluster_processlist 中找出来的进程ID被KILL后依然还在
状态变成什么了?
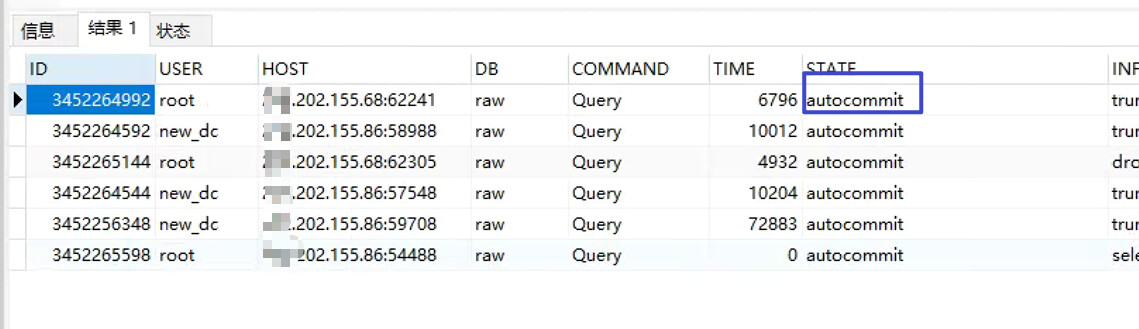
这个sql可能已经失败了。可以通过查对应tidb节点的日志,过滤一下该 session id ,是否出现关键字“command dispatched failed” 来确认。
这可能是个已知问题: https://github.com/pingcap/tidb/issues/44009。
可以通过重启对应的tidb节点来解决,或者升级集群。
1 个赞
执行的是truncate table 语句?是不是在回滚?
kill的什么进程
看一下日志吧
cluster_processlist 中的信息来源于各 TiDB 节点的内存状态,可能有延迟。
应该还有进程没有完成内部更新操作
语句是什么呢,是不是后台还在处理
KILL 仅触发终止信号,需等待事务回滚、资源释放完成后才会从列表消失,回滚耗时与数据量正相关
– 1. 查看全局进程(含 INSTANCE 列,定位节点)
SELECT ID, USER, INSTANCE, INFO, COMMAND, TIME FROM INFORMATION_SCHEMA.CLUSTER_PROCESSLIST;
– 2. 正确终止(二选一)
KILL TIDB <进程ID>; – 终止整个连接(彻底清理)
KILL TIDB QUERY <进程ID>; – 仅终止当前查询(连接保留)
1 个赞
他这个应该是kill会话吧,不是终止查询
请问该问题解决了吗,方案是什么
![]() 估计解决了,要不然会追问的。
估计解决了,要不然会追问的。
解决方案咋样,也学习一下
一般就是重启tidb节点
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。