集群升级的我测试过了,一样的结果
batch-dml-enable这个参数我现在试下
看下下游 v8.1.1 的执行 sql,是不是有 SELECT xxx FROM information_schema.ddl_jobs 这样的 查询耗时较高呢?
这个参数也没效果
没有的,我现在新建一个测试的集群,是没有业务接入的,只跑这个 cdc 的测试
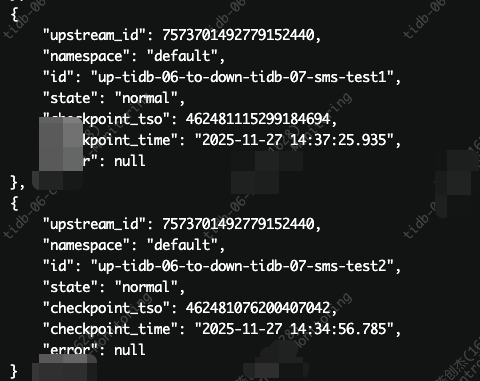
第一个任务是没有 update 语句的,延迟正常,第二个是insert 跟 update 1:3 比例,就是一条 insert 语句后大概有 3 条 update 语句,就一直延迟堆积了,从 6.5.9 版本的过去 8.1.1 是正常的,现在切换到 8.5.3 过去 8.1.1,就有这个问题了
看下下游的 tidb dashboard上面的 Top SQL 吧,看下是不是下游执行速度慢 https://docs.pingcap.com/zh/tidb/stable/top-sql/
跟下游没关系
你这种情况确实没遇到过了,根据你的描述,当有 update 语句时,就出现延迟堆积了,但是 tikv 到 cdc 的链路看起来是正常的,试下把 safe-mode 设置为 true 吧, cdc 会把所有的 UPDATE 语句转换为 DELETE + REPLACE INTO 语句,这样看下延迟会不会升高
还是一样的结果 ![]()
tiup cdc cli changefeed create --server=http://172.22.142.243:8300 --config /data/tidb-cdc-config/ticdc-tidb-06-test2.toml --sink-uri=“mysql://root:xxx@172.27.0.xxx:4000/?worker-count=1024&max-txn-row=2048&max-multi-update-row=256&max-multi-update-row-size=8192&safe-mode=true” --changefeed-id=“up-tidb-06-to-down-tidb-07-test2” --start-ts=462499496797405191
# 1. 降低批处理等待时间,减少高延迟下的堆积
batch-wait-time = "10ms" # 还原v6.5.9默认值,避免等待叠加延迟
# 2. 调整批处理大小,平衡吞吐与延迟
txn-batch-size = 128 # 从256下调,减少单批传输耗时
# 3. 优化同步并发数,匹配网络延迟特性
replica-sync-concurrency = 8 # 保持高版本并发优势,无需下调
mounter-concurrency = 8 # 解析并发数与同步并发数匹配
# 4. 关闭动态流控,手动指定带宽适配延迟
enable-dynamic-flow-control = false
# 5. 关闭不必要的加密(若跨网络无需加密)
enable-tls = false
# 6. 调整心跳间隔,减少状态同步开销
heartbeat-interval = "10s" # 还原v6.5.9默认值
- 检查 v8.1.1 的
tidb_replica_read参数,确保未开启 “从副本读取”(会增加查询延迟)。 - 查看目标端 TiKV 的
import.batch-size和import.concurrent-write-threads,确保接收端写入能力匹配发送端。
- 查看 CDC 日志中的
pending-rows(待发送行数):若持续增长,说明发送速率跟不上捕获速率,需调小txn-batch-size或关闭动态流控。 - 监控
network-round-trip-time(网络往返时间):若稳定在 200ms 左右,需确认batch-wait-time不超过往返时间的 1/10。
谢谢,我尝试一下
network-round-trip-time这个在哪里看
这些配置我咋一个都没找着 ![]()
cdc 任务新建的时候,需要订阅 region,你大概等了多久?
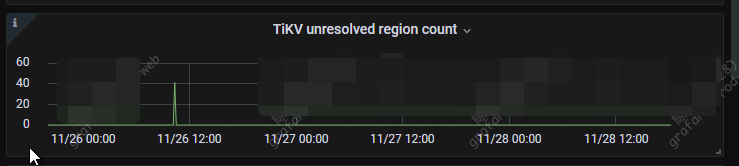
看下 ticdc 监控,unresolved region 数量当时有降到 0 么?
你发下 当时是不是在订阅,理论上 unresolved region 变为 0 才开始同步的。
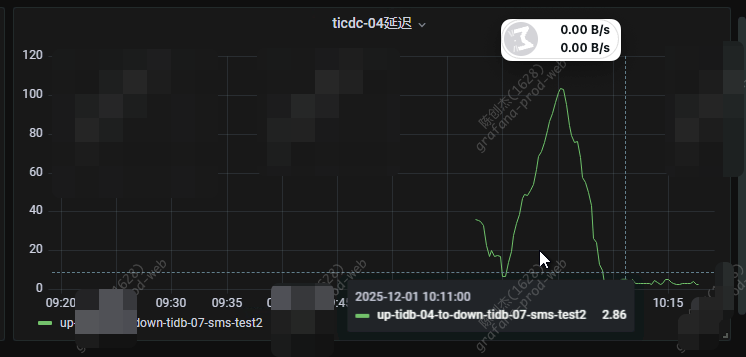
你延迟加大是有在同步但是同步不过来还是没有同步数据呢。
有在同步,同步不过来,update 太多了,其他的表insert 多的正常