【TiDB 使用环境】生产环境
【TiDB 版本】v7.5.0
【操作系统】centos
【部署方式】3台机器部署(64核128G)
【集群数据量】
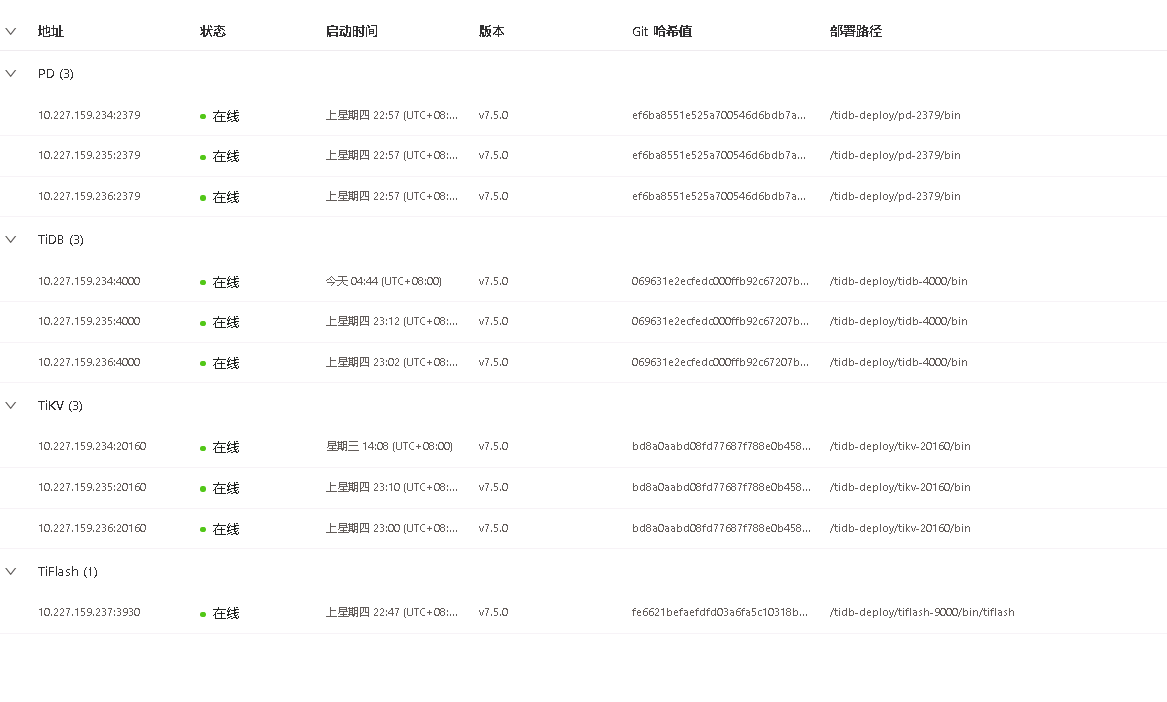
【集群节点数】3
【问题复现路径】tiup部署
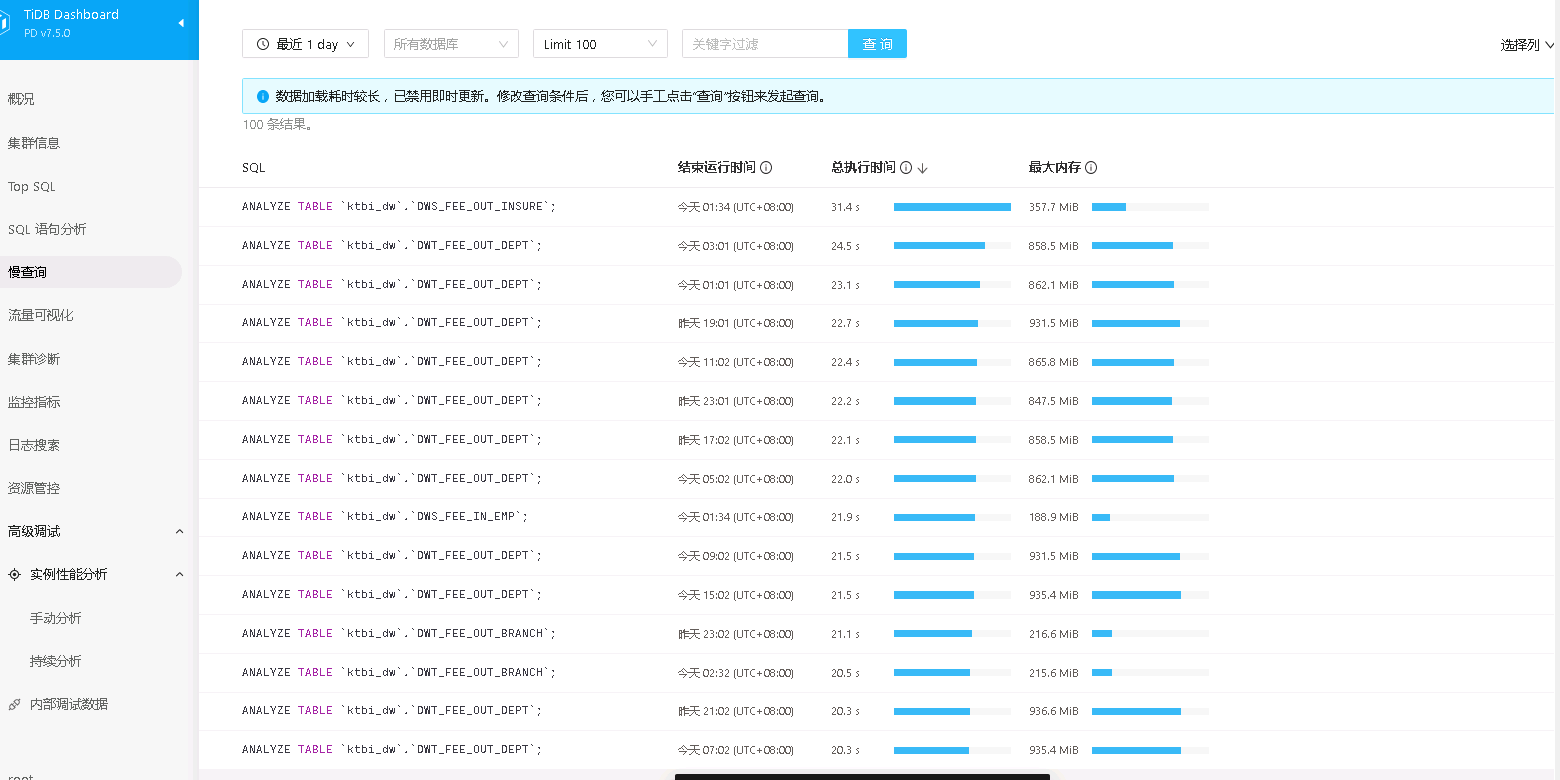
【遇到的问题:问题现象及影响】慢查询过多,这种情况是该优化db、pd、kv的参数设置还是增加物理机内存?
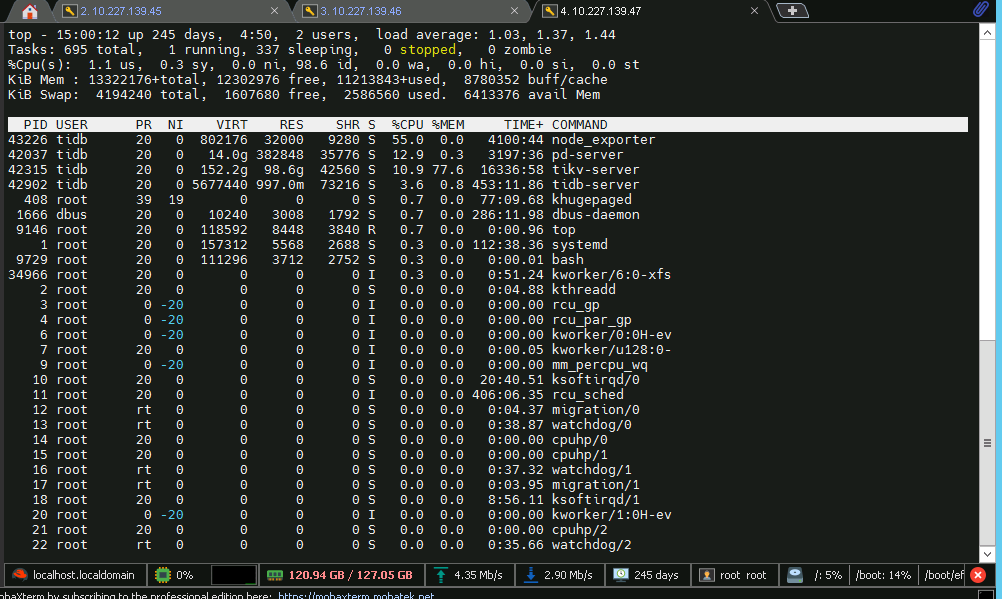
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
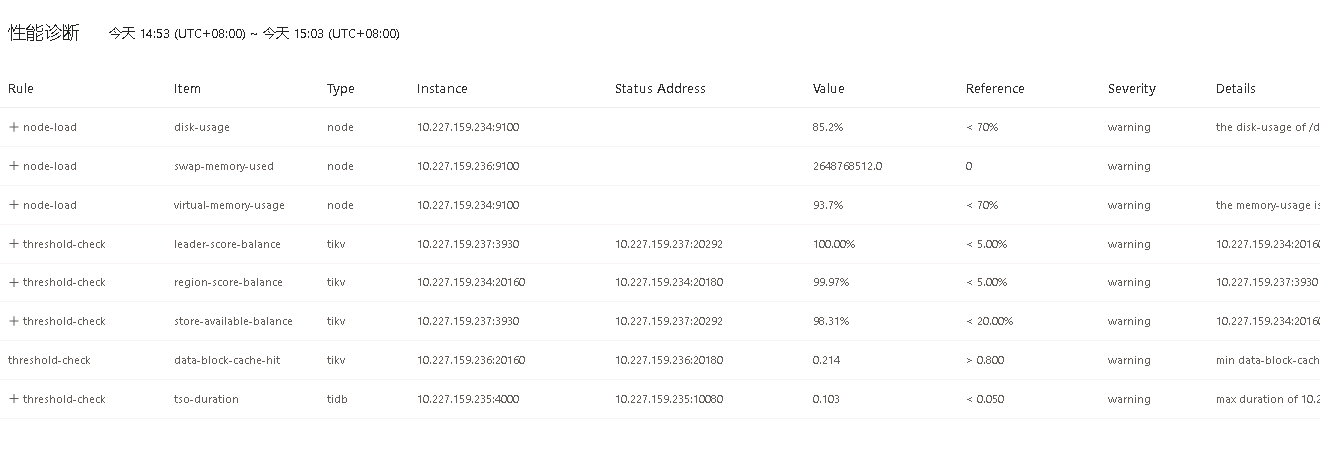
【复制黏贴 ERROR 报错的日志】性能诊断各项数据异常
【其他附件:截图/日志/监控】
服务器情况如图
analyze是系统sql,一般不会影响整个集群性能,无需过于关注,除了analyze之外有没有其他业务sql慢的
随缘天空
(Ti D Ber Ivw R7o Pj)
3
analyze语法不是业务sql,所以可不用太关注。此外,你得tidb和tikv是混合部署的,同一台服务器上两个组件都有,容易相互抢资源
异乡的大人
(Ti D Ber 2 Qs S2z Ws)
5
10.227.159.234 节点磁盘使用率 85.2%、内存使用率 93.7%(均超 70% 阈值);236 节点 Swap 内存占用过高
资源利用率5分钟内不能超过80%. tidb distsql scan concurrency , tidb executor concurrency 这些可以试下减少
先排查非 ANALYZE 的业务慢 SQL,同时优化节点内存 / 磁盘负载与 TiKV 集群均衡性
看你这种情况相互抢资源呢,tidb和tikv混合部署
analyze table本来就是慢, 这个没关系的把
三个节点的leader和region监控上看着都保持一样,均衡应该没有啥问题吧
select * from某些很简单的表的时候都会由timeout的情况,网络之前有丢包,现在解决了,但是还是由超时的情况,在硬件内存占用如此高的情况下,是否也导致超时?
WalterWj
(王军 - PingCAP)
14
一切的根源都是表扫描或高频SQL引起的资源占用,先从SQL计划入手分析
捕获慢 SQL → 分析执行计划 → 定位瓶颈 → 优化验证
需要排除掉峰值期间整体慢而引发的误报问题,找到出现性能问题时最初的SQL进行分析
1 个赞
Royce1220
(Ti D Ber Kwxb3 N7 I)
20
是不是表上main数据比较多,导致收集统计信息过慢