一个好的问题描述有利于社区小伙伴更快帮你定位到问题,高效解决你的问题
【TiDB 使用环境】生产环境
【TiDB 版本】v8.5.3
【部署方式】虚拟机
【操作系统/CPU 架构/芯片详情】
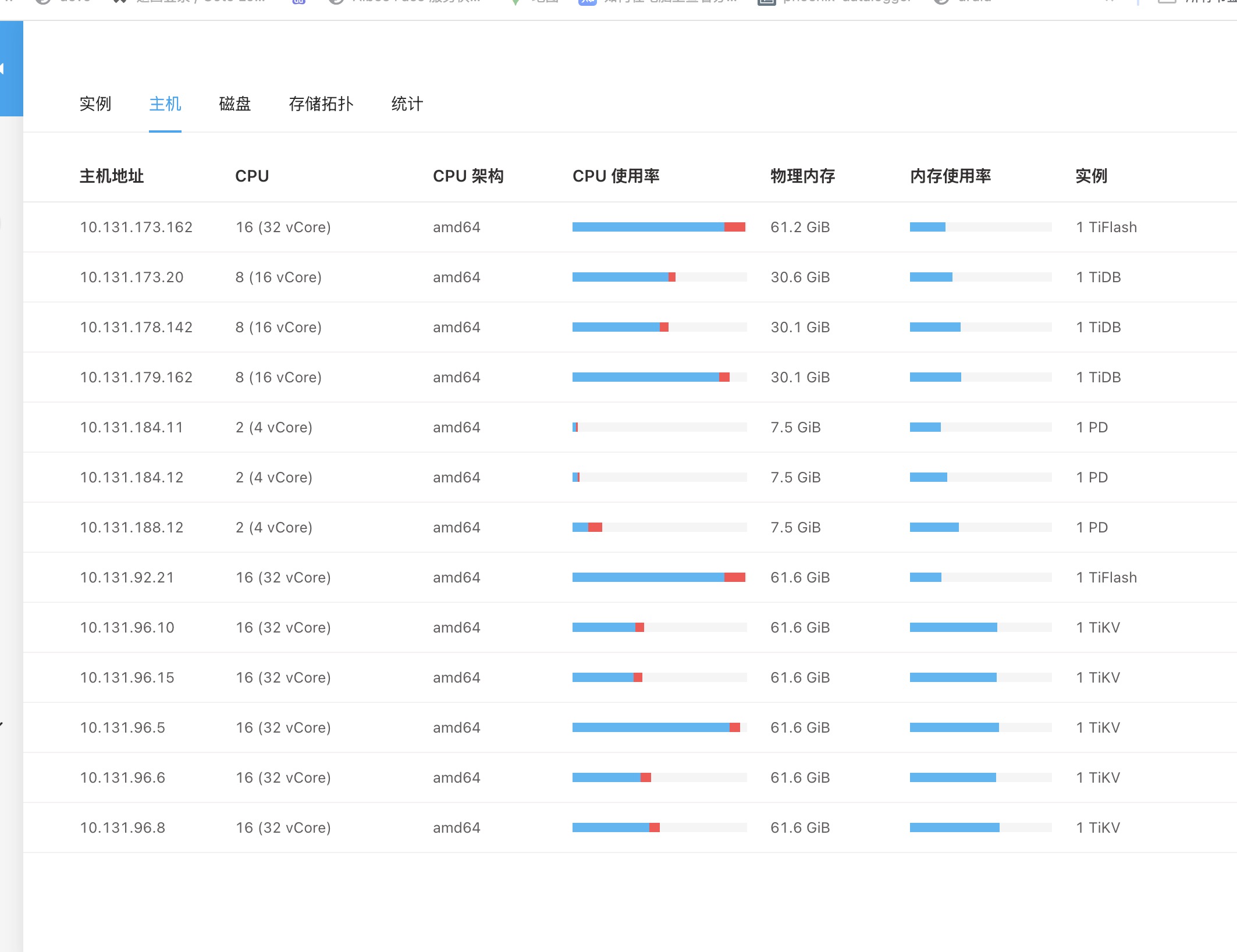
【机器部署详情】CPU大小/内存大小/磁盘大小
【集群数据量】
【集群节点数】
0点reload重启集群后就各种问题,耗时变长,cpu占用率很高,执行计划不稳定,tiflash cpu占满
【复制黏贴 ERROR 报错的日志】

出现大量错误日志
2026-02-27 13:32:40 (UTC+08:00)
TiDB 10.131.173.20:4000
[distsql.go:1250] [“tableWorker in IndexLookUpExecutor panicked”] [conn=1074622224] [session_alias=] [recover=“[executor:3024]Query execution was interrupted, maximum statement execution time exceeded”] [stack=“github.com/pingcap/tidb/pkg/executor.(*tableWorker).pickAndExecTask.func1\n\t/workspace/source/tidb/pkg/executor/distsql.go:1250\nruntime.gopanic\n\t/usr/local/go/src/runtime/panic.go:791\ngithub.com/pingcap/tidb/pkg/util/memory.(*Tracker).Consume\n\t/workspace/source/tidb/pkg/util/memory/tracker.go:507\ngithub.com/pingcap/tidb/pkg/executor.(*tableWorker).executeTask\n\t/workspace/source/tidb/pkg/executor/distsql.go:1564\ngithub.com/pingcap/tidb/pkg/executor.(*tableWorker).pickAndExecTask\n\t/workspace/source/tidb/pkg/executor/distsql.go:1268\ngithub.com/pingcap/tidb/pkg/executor.(*IndexLookUpExecutor).startTableWorker.func1\n\t/workspace/source/tidb/pkg/executor/distsql.go:864”]
2026-02-27 13:32:44 (UTC+08:00)
TiDB 10.131.178.142:4000
[select_result.go:598] [“invalid cop task execution summaries length”] [expected=1] [received=0]
2026-02-27 13:32:44 (UTC+08:00)
TiDB 10.131.178.142:4000
[select_result.go:598] [“invalid cop task execution summaries length”] [expected=1] [received=0]
2026-02-27 13:32:44 (UTC+08:00)
TiDB 10.131.178.142:4000
[distsql.go:1250] [“tableWorker in IndexLookUpExecutor panicked”] [conn=529340294] [session_alias=] [recover=“[executor:3024]Query execution was interrupted, maximum statement execution time exceeded”] [stack=“github.com/pingcap/tidb/pkg/executor.(*tableWorker).pickAndExecTask.func1\n\t/workspace/source/tidb/pkg/executor/distsql.go:1250\nruntime.gopanic\n\t/usr/local/go/src/runtime/panic.go:791\ngithub.com/pingcap/tidb/pkg/util/memory.(*Tracker).Consume\n\t/workspace/source/tidb/pkg/util/memory/tracker.go:507\ngithub.com/pingcap/tidb/pkg/executor.(*tableWorker).executeTask\n\t/workspace/source/tidb/pkg/executor/distsql.go:1564\ngithub.com/pingcap/tidb/pkg/executor.(*tableWorker).pickAndExecTask\n\t/workspace/source/tidb/pkg/executor/distsql.go:1268\ngithub.com/pingcap/tidb/pkg/executor.(*IndexLookUpExecutor).startTableWorker.func1\n\t/workspace/source/tidb/pkg/executor/distsql.go:864”]
【其他附件:截图/日志/监控】
logs (2).zip (8.8 KB)