一个好的问题描述有利于社区小伙伴更快帮你定位到问题,高效解决你的问题
【TiDB 使用环境】生产环境
【复制黏贴 ERROR 报错的日志】
小青年er
2026 年3 月 3 日 01:27
3
我觉得Go Runtime垃圾回收(GC)在高负载下可能频繁触发STW(Stop-The-World),然后导致CPU使用率飙升,GC触发频率与CPU波动周期85秒可能相关,尤其是当内存使用接近tidb_server_memory_limit时,GC压力会显著增加,调整参数试试呢
@rubynle 嗯,发一下 tidb 的监控看板吧,不行收集一个 clinic 整体看看,有可能是 grouting 的 gc 回收问题。最简单的验证方式就是扩容 tidb sever, dashboard 截图 tidb sever 的实例的 CPU 不是很均衡,tidb sever CPU 高是个别现象还是都有这个问题。
独善其身
2026 年3 月 3 日 02:03
5
dashboard里找到慢sql之后,用trace工具看看在哪个组件耗时较久,然后看看执行计划在那个组件里面的耗时最久
感谢各位大佬@hey-hoho 没有明显的慢查询@小青年er 我们集群没有使用的是默认tidb_server_memory_limit,您的建议是调小这个参数吗
@Lucien-卢西恩 tidb重启后恢复了,集群的整体负载不高,应该不需要扩容tidb节点,不均衡是因为有部分节点我重启后恢复了
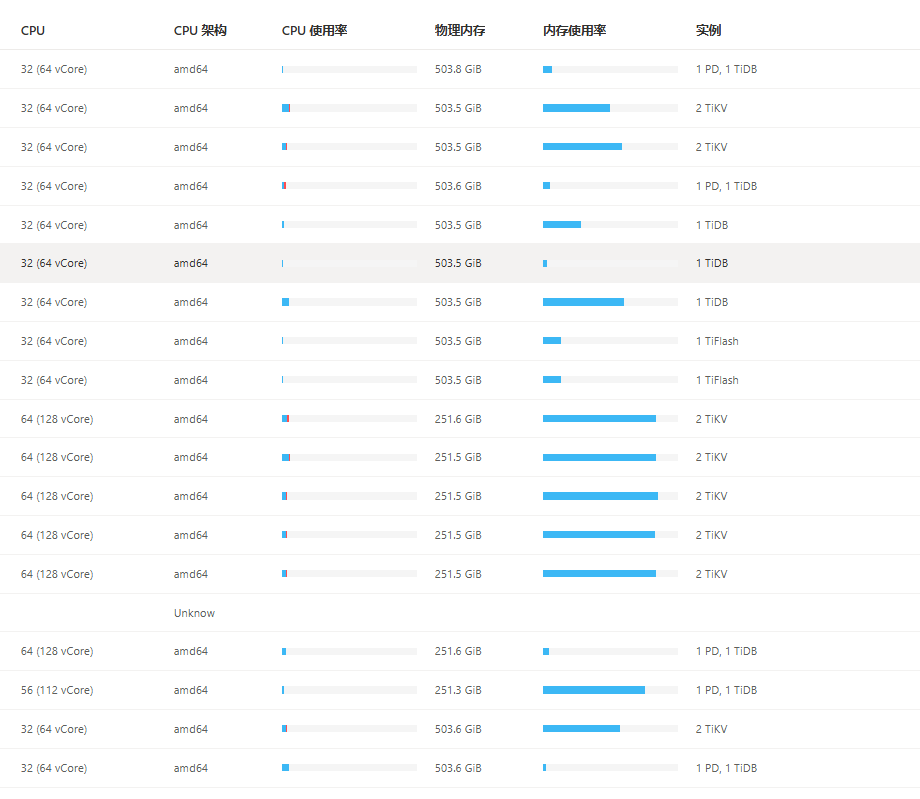
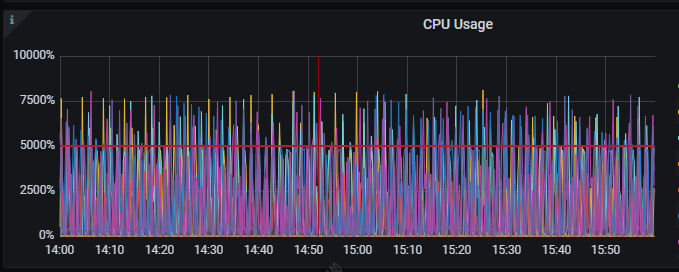
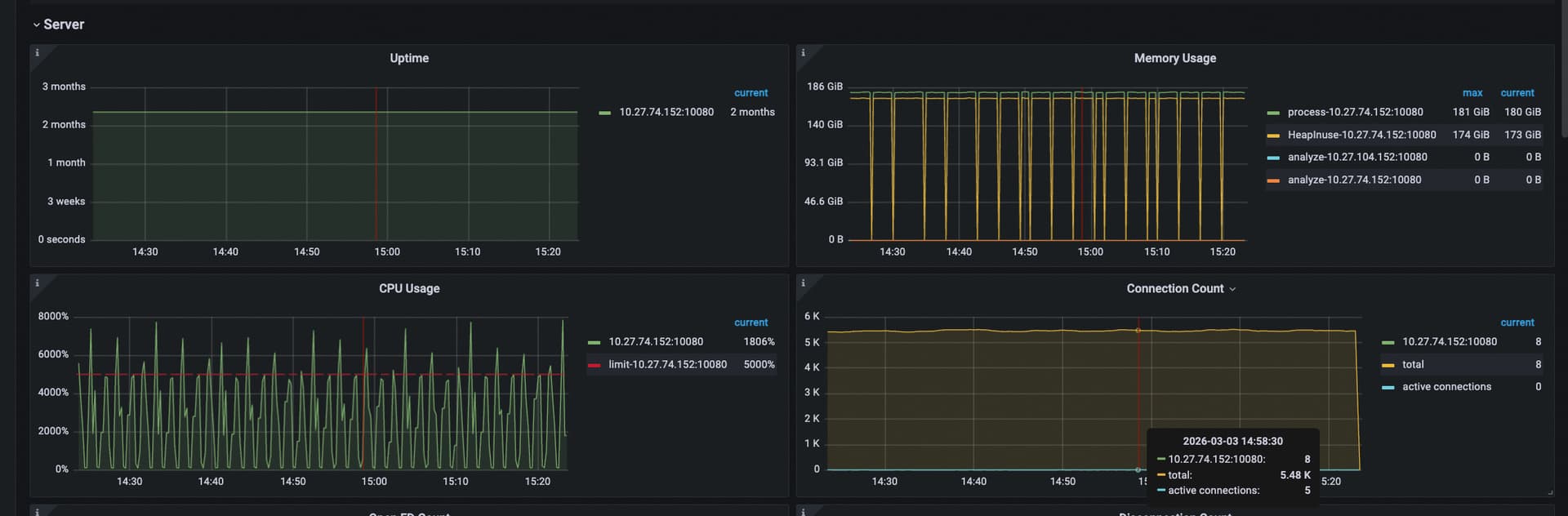
这个是问题时间段的所有TiDB Server的CPU监控
WalterWj
2026 年3 月 5 日 02:34
8
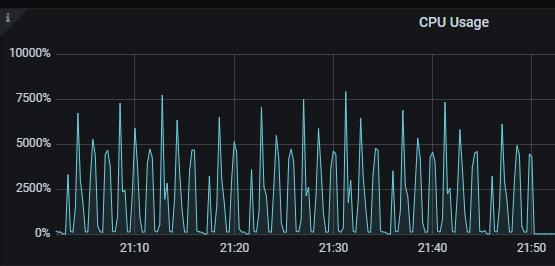
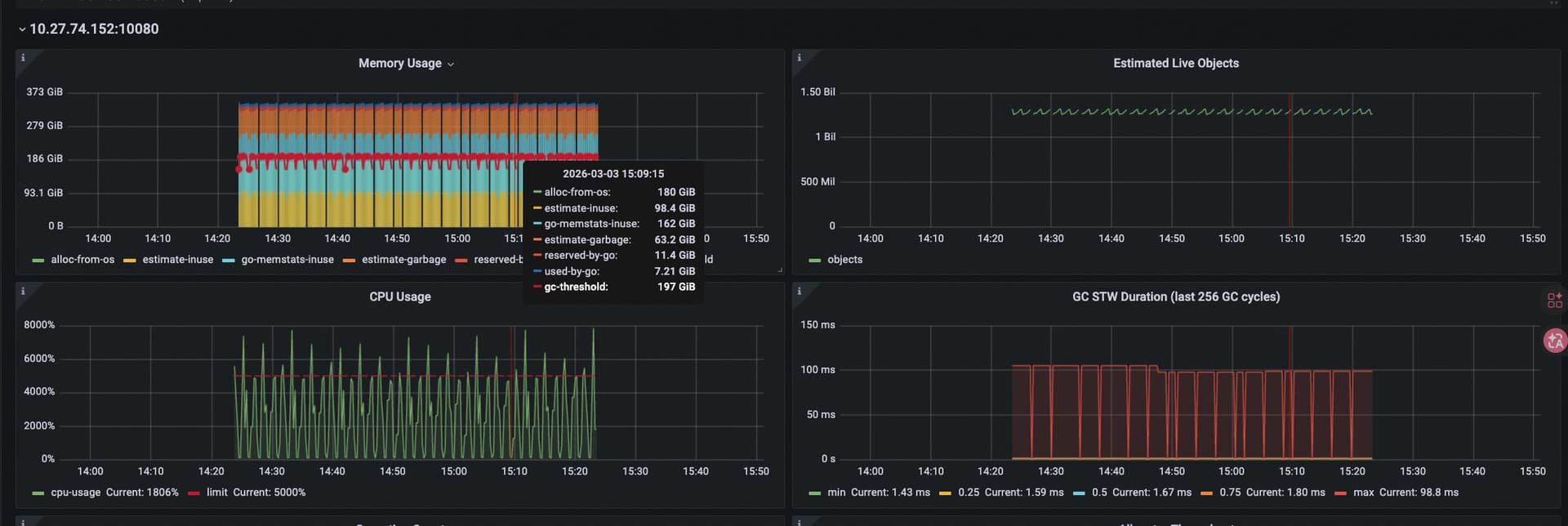
mem 当时用的也很多。
对应 tidb 有一些流量:
结合贴上面:
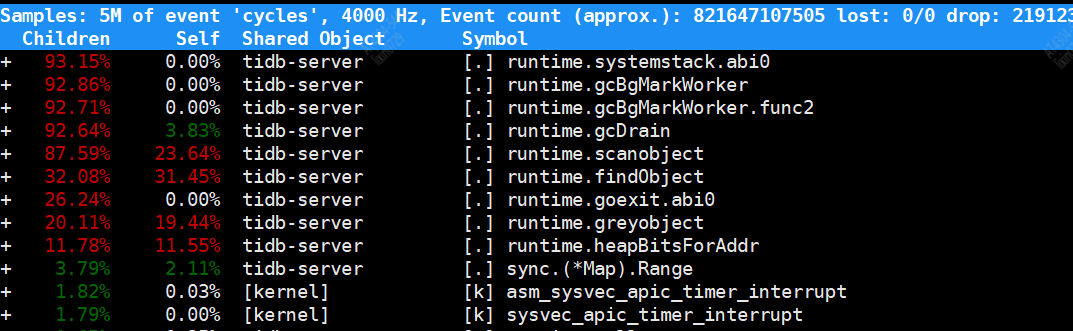
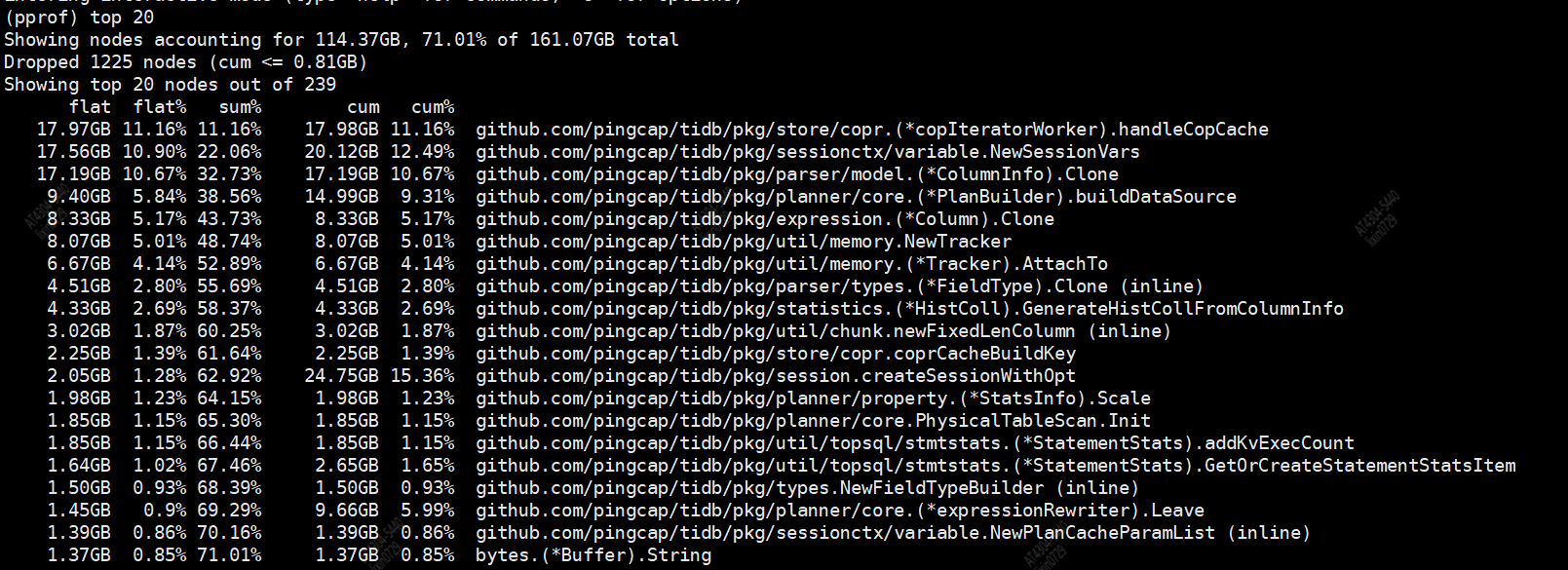
主要 CPU 消耗函数 :
runtime.gcBgMarkWorker (93.15%):后台标记工作线程,负责标记需要保留的对象
runtime.gcBgMarkWorker.func2 (92.86%):标记过程的内部函数
runtime.gcDrain (92.71%):处理标记队列的函数
runtime.scanobject (87.59%):扫描对象并标记引用
runtime.findobject (32.08%):查找对象的函数
runtime.heapBitsForAddr (11.11%):处理堆内存位信息的函数
感觉当时活跃对象数量(10 亿) 直接导致了 GC 压力剧增
看了上传的慢日志,也没看出啥。
看到 tidb 日志:
[memoryusagealarm.go:215] ["tidb-server has the risk of OOM because of memory usage exceeds alarm ratio. Running SQLs and heap profile will be recorded in record path"] ["is tidb_server_memory_limit set"=true] [tidb_server_memory_limit=215888851760] ["tidb-server memory usage"=172934062040] [memory-usage-alarm-ratio=0.7] ["record path"=/data/tidb_deploy/tidb-4000/log/oom_record]
你可以去对应节点,看下 oom_record 下内容,有没有什么留存。
1 个赞
WalterWj
2026 年3 月 5 日 02:37
9
rubynle:
7.5.3
7.5.4 有个修复: * 修复由于查询超出 tidb_mem_quota_query 设定的内存使用限制,导致终止查询时可能卡住的问题 #55042 @yibin87
https://docs.pingcap.com/zh/tidb/stable/release-7.5.4/#错误修复
推荐集群做下升级吧。可以升级到 7.5.7
kang
2026 年3 月 5 日 02:39
10
应该是GC 导致的把GC时间调大 ,看看是不是有缓解
乾坤大挪移
2026 年3 月 5 日 02:41
11
① 看 Grafana
关注:
tidb_server_memory_usage
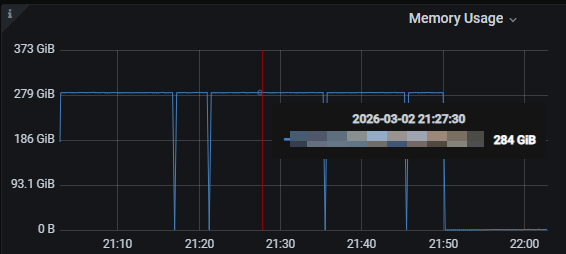
如果看到:
内存缓慢上升
到某点突然下降
同时 CPU 峰值
那就是 GC 抖动。
1 个赞
@WalterWj running_sql.zip (3.7 MB)
@kang 感谢大佬,GC调大应该会缓解cpu的问题,但是gc触发应该还是会导致cpu的波动
@乾坤大挪移 感谢大佬回复,内存的波动几乎一直在上限左右,触发gc会下降很少,然后上升到上限,再次gc,循环
这 3 种原因概率最高:
Go GC 周期性抖动(最常见)
统计信息 Auto Analyze 周期触发
Plan Cache / Session 暴涨导致内部资源抢占
top -Hp pidof tidb-server # 找到%CPU最高的线程ID(十进制)
printf “%x\n” 线程ID # 示例:1234 → 4d2
gdb -p pidof tidb-server -ex “thread apply 0x4d2 bt” -ex “quit” > tidb_cpu_stack.log
curl http://TiDB节点IP:10080/debug/pprof/profile?seconds=30 -o tidb_cpu.pprof
纯白镇的小智
2026 年3 月 7 日 04:11
21
重启 TiDB 节点仅临时恢复,可先通过以下操作快速压制 CPU 飙升,保障业务可用