在上一期的【TiDBer 唠嗑茶话会 193】开工大吉,新的一年,你希望 TiDB 有哪些新的功能!
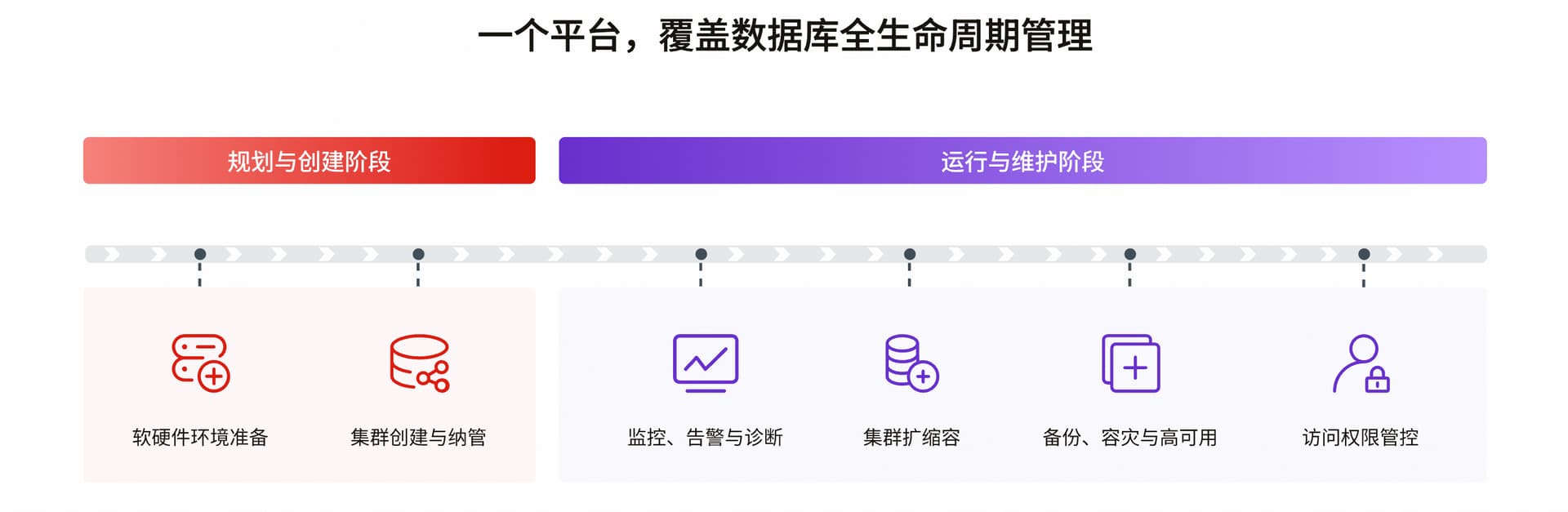
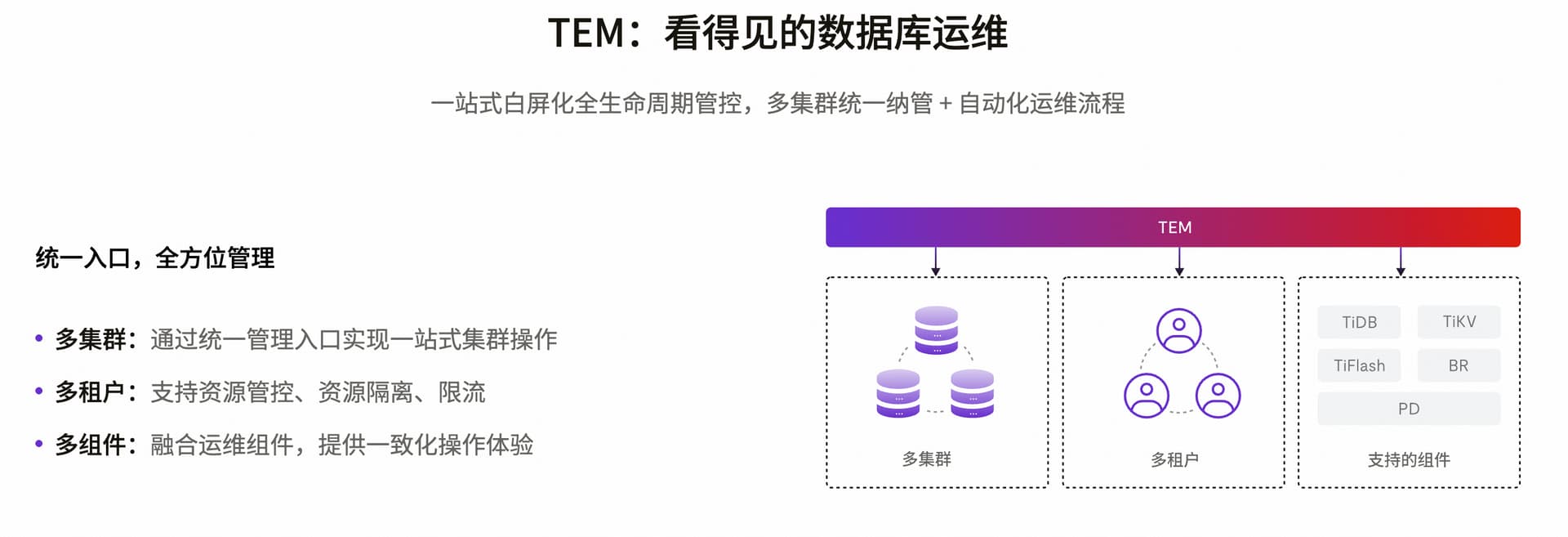
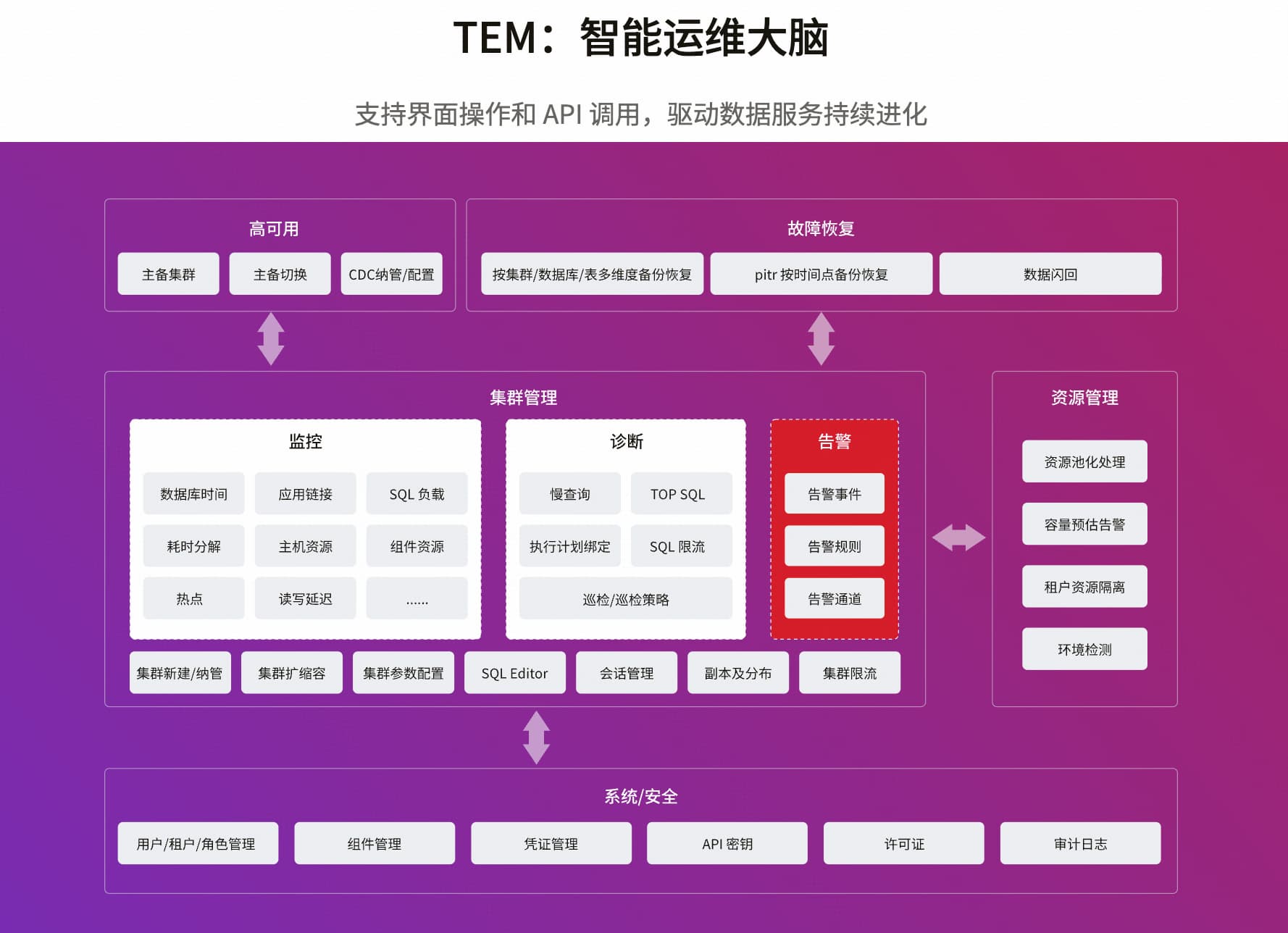
TEM(TiDB Enterprise Manager)平凯数据库(TiDB 企业版) 企业级运维管理平台 。它通过智能化、统一化、规范化、可视化、自动化的资源纳管、运维编排、监控告警、备份恢复、故障恢复、性能诊断等端到端的管控能力,提供高效、便捷且可靠的运维管控解决方案,解决在管理 TiDB 集群过程中面临的各类复杂挑战。
TEM 可纳管平凯数据库所有发行的商业版及社区版本 v6.5 以上版本集群
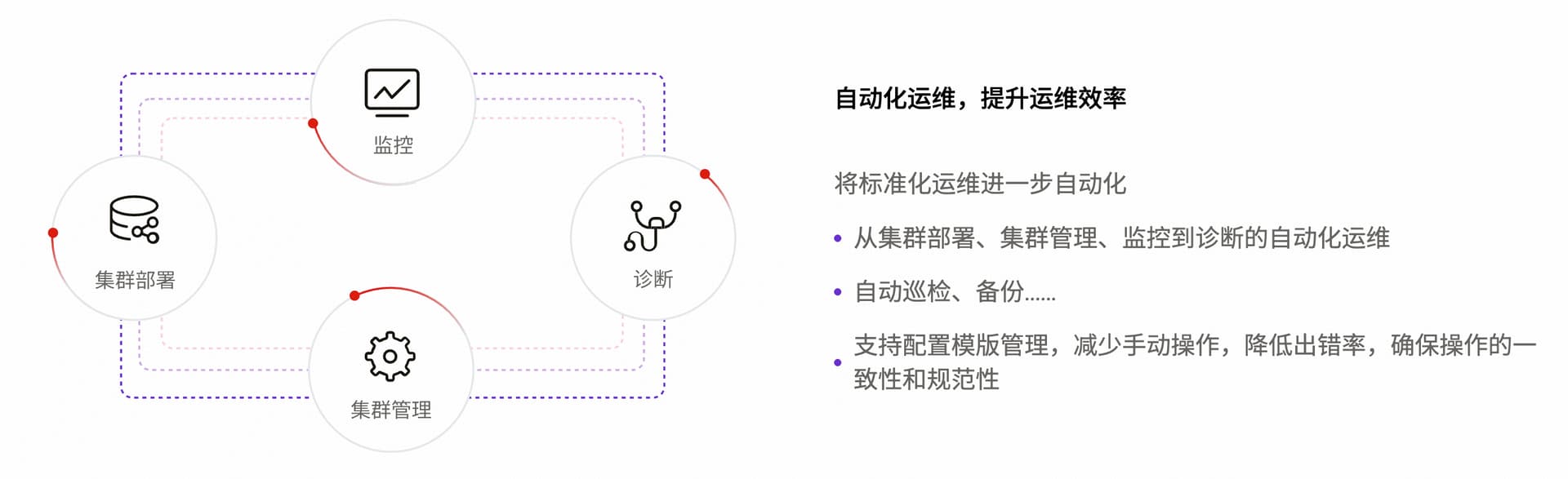
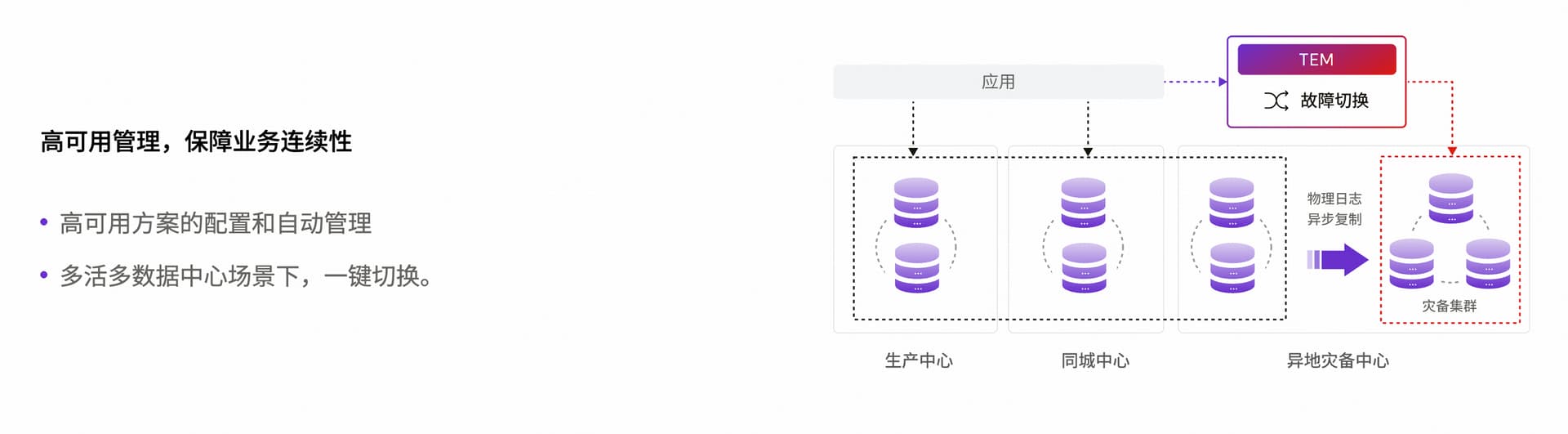
TEM 目前主要包含任务子系统和 TEM 核心服务,并通过 TiUP、Agent、SSH 对部署在物理机或 VM 上的 TiDB 集群进行管理。任务子系统主要负责管理 TEM 系统需要执行的各类任务,包括周期性任务、一次性任务等。在 TEM 核心服务中,包含了集群管理、备份恢复管理、告警管理、主机管理等功能模块。用户可以通过图形化用户界面来访问 TEM,完成对 TiDB 集群和其各个组件的管理。
[image]
现在,平凯数据库(TiDB 企业版)为您带来了全新的解决方案—— 敏捷模式 。它是基于同一套强大内核衍…
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
例如自动识别故障类型、定位问题根源、提供解决方案等。
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
例如自动识别慢查询模式、提供 SQL 优化建议、预测潜在性能瓶颈等。
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
例如 7x24 小时无人值守巡检、异常指标智能预警、资源使用趋势预测等。
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
例如组件健康度评分、潜在故障风险预警、性能瓶颈预测等。
认真回复以上问题,可获得 50 积分 & 经验值!
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
自动识别节点宕机、网络分区、Raft 异常、Region 不可用、事务阻塞、数据同步延迟、磁盘 IO 瓶颈、内存溢出并发信息过来
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
识别 Top N 慢查询、周期性慢查询、突发慢查询
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
自动检查备份任务状态、备份完整性、恢复点有效性;巡检 Raft 副本数、Leader 分布、高可用配置,确保灾备能力达标
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
自动识别问题根源
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
慢查询,死锁
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
wfxxh
2026 年3 月 6 日 00:47
5
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
自动定位并解决故障
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
慢查询sql的具体原因,并给出优化方案
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
异常指标预警。
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
潜在故障风险预警、性能瓶颈预测
纯白镇的小智
2026 年3 月 6 日 01:01
6
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
自动定位并解决故障、定位问题根源
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
慢查询
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
资源使用趋势预测。
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
潜在故障风险预警
Sakura6680
2026 年3 月 6 日 01:10
7
如果你是开发工程师,你觉得你会动手结合 AI 及 TEM 运维平台,去做哪些“简单且有效果、容易实现 ”智能运维的功能开发?
3 个赞
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
DBRE
2026 年3 月 6 日 01:18
9
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
提供大模型配置,辅助做故障的根因定位
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
识别根因SQL,给出优化建议
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
自动识别高风险高负载SQL,自增值溢出巡检,提前告知风险
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
大模型问题诊断能力,并给出分析过程。
koby
2026 年3 月 6 日 01:22
11
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
自动识别问题,并从知识库获取解决方案提供建议。
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
慢sql分析点位和优化
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
从可用性、性能、资源、稳定性、风险多维度计算健康分,提前给出处置建议
如果你是开发工程师,你觉得你会动手结合 AI 及 TEM 运维平台,去做哪些“简单且有效果、容易实现 ”智能运维的功能开发?
1 个赞
yg_2024
2026 年3 月 6 日 01:29
13
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
快速完成全量指标的采集与分析,AI给出初步的可能故障原因判断,随后根据初步根因收集详细日志(tikv、tidb报错日志、通过pd-ctl接口才能采集到的信息),再结合历史知识库内的问题匹配(特别是bug),给出综合判断的故障原因,每个原因后面呈现出具体的报错信息(用于人工复核),最后同步给出解决措施建议。
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
1、进行ai分析时,关联SQL内涉及的对象的统计信息情况、历史执行计划绑定情况,综合判断是否需要hint绑定,并直接给出绑定的语句。
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
通过自然语音完成对应系统及模块的快速巡检,比如:
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
1、请判断XX系统,当前存储空间还可支持多少天?
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题
故障智能诊断
故障恢复建议:提供具体的操作步骤
故障复盘辅助:自动生成故障发生前后的完整时间线(指标异常点 → 告警触发 → 业务影响出现)
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
慢查询智能识别
优化建议生成
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
无人值守智能巡检:自动检查集群所有组件的关键指标,生成每日巡检报告
智能预警:自动发现指标的异常波动(如 QPS 突降、延时突增),而非仅依赖固定阈值
趋势预测:预测未来 7/30 天的磁盘、CPU、内存使用趋势
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
健康度评估体系
风险预警能力
诊断建议
MrSylar
2026 年3 月 6 日 02:19
15
问题 1 TiDB 集群故障时,我最希望 TEM AI 智能运维能帮助解决这些具体问题:
是否没走索引
是否大表全表扫
是否数据倾斜 / 热点
是否 TiDB 优化器选错索引
是否事务过大、锁等待
给出可直接执行的优化建议:
建议加什么索引
建议改写 SQL
建议调整会话变量 / 统计信息
预测慢查询:提前发现即将变慢的 SQL,提前优化。
慢查询影响面分析:自动告诉哪些接口、哪些业务在调用,影响多大。
集群健康巡检自动化:每日 / 每周自动巡检 TiDB、TiKV、PD、监控组件状态,自动出报告。
容量预测自动化:自动预测磁盘、CPU、内存、连接数未来 7/30 天是否会爆。
配置合规巡检:自动检查参数不合理、版本不一致、磁盘风险、副本异常。
热点自动巡检:自动发现表热点、行热点、索引热点。
备份有效性自动校验:自动检查备份是否成功、是否可恢复。
异常指标自动降噪:自动识别突刺、抖动、周期性异常、渐变异常,不用人盯屏。
预测节点即将宕机
预测 Raft 同步可能卡住
预测磁盘即将满 / 性能下降
建议调整调度策略
1 个赞
智能监控:基于 AI 的异常检测与趋势预测
参与方式 一 开放性问题:
问题 1:在 TiDB 集群出现故障时,您最希望 TEM 的 AI 智能运维功能能够帮助您解决哪些具体问题?
问题 2:对于 TiDB 集群中的慢查询问题,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的分析和优化能力?
识别出慢查询,并且给出建议,即使说sql已经没得优化了,可以参考表结构建议加一些索引,或者sql拆一下,换个写法之类的,说不定业务方就是脑残,随意写了个垃圾sql呢。
问题 3:在日常运维工作中,您最希望 TEM 的 AI 智能运维功能能够自动化哪些巡检和监控任务?
实时对比监控,实际上也就是监控基线,识别出集群健康状态正在恶化,一般恶化的诱因是有新的业务变更,在业务刚上线没压力之前就识别出来,做出提示。
问题 4:对于 TiDB 各组件的健康状况管理,您希望 TEM 的 AI 智能运维功能能够提供哪些具体的诊断和预测能力?
以上,就够了