1. 引言
在现代分布式数据库系统中,尤其是在处理海量数据和高并发写入场景时,存储引擎的选择至关重要。TiDB 作为一款流行的分布式关系型数据库,其底层存储引擎 TiKV 广泛采用了 RocksDB,而 RocksDB 的核心正是 LSM-tree (Log-Structured Merge-tree) 结构。LSM-tree 是一种专为写密集型工作负载优化的数据结构,它通过将随机写入转换为顺序写入,显著提升了写入性能,但同时也带来了一些读放大、写放大和空间放大的挑战。本文将深入浅出地剖析 LSM-tree 的工作原理,结合 TiDB/RocksDB 的实现细节,并通过图示帮助读者理解这一复杂而高效的存储机制。
2. LSM-tree 核心组件
LSM-tree 的设计哲学是将数据分为内存部分和磁盘部分,并利用分层合并的策略来管理数据。其主要组件包括:
2.1. WAL (Write-Ahead Log) - 预写日志
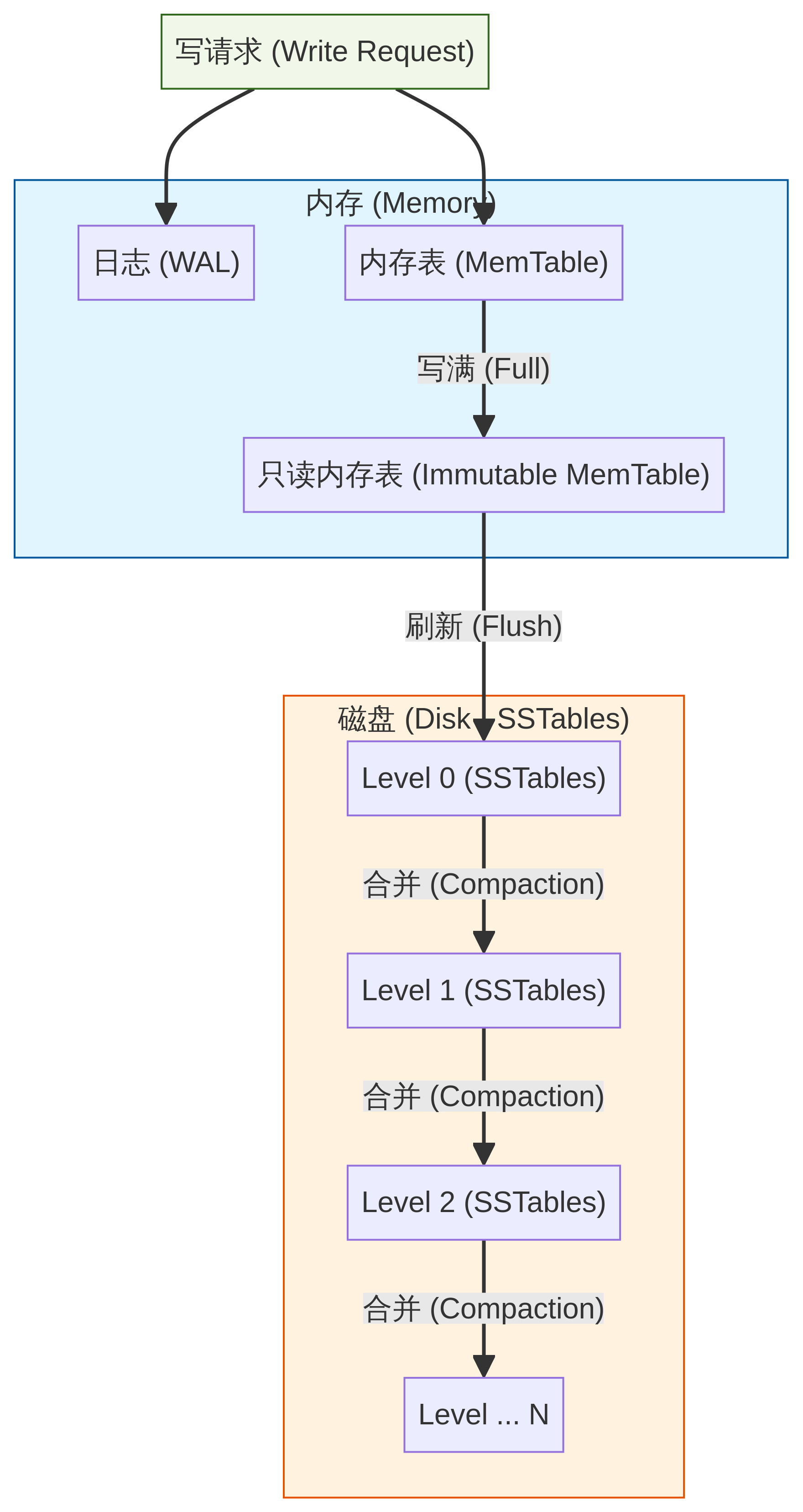
WAL 是 LSM-tree 的第一道防线,所有写入操作首先会被追加到 WAL 中。WAL 是一种顺序写入的日志文件,它的主要作用是保证数据持久性。即使系统在数据写入内存后、刷新到磁盘前发生崩溃,也可以通过重放 WAL 中的日志来恢复数据,避免数据丢失。
2.2. MemTable - 内存表
MemTable 是内存中的一个有序数据结构(通常是跳表或红黑树),用于存储最新的写入数据。所有新的写入操作在写入 WAL 后,也会被插入到 MemTable 中。由于 MemTable 位于内存中,写入速度非常快。当 MemTable 达到一定大小或满足特定条件时,它会变为不可变(Immutable MemTable),并准备刷新到磁盘。
2.3. SSTable (Sorted String Table) - 有序字符串表
SSTable 是磁盘上的一个不可变、有序的键值对文件。它由 MemTable 刷新而来,或者由多个 SSTable 合并(Compaction)生成。SSTable 内部的数据是按键有序排列的,这使得范围查询非常高效。为了进一步优化存储和查询,SSTable 通常会包含索引块和布隆过滤器,以快速判断某个键是否存在于文件中。
LSM-tree 通常将磁盘上的 SSTable 组织成多个层级(Level),例如 Level 0 (L0), Level 1 (L1), Level 2 (L2) … Level N (LN)。
- L0 层: 直接由 Immutable MemTable 刷新而来,L0 层的 SSTable 之间可能存在键范围重叠。
- L1 到 LN 层: 这些层级的 SSTable 之间键范围不重叠,每个层级内的 SSTable 也是有序的。层级越高,数据越“老”,文件越大,数量越多。
3. 写入流程
LSM-tree 的写入流程充分利用了磁盘顺序写入的优势,具体步骤如下:
- 接收写入请求: 当数据库接收到一个写入(插入、更新、删除)请求时。
- 写入 WAL: 首先将该操作记录到 WAL 中。这一步确保了数据的持久性。
- 写入 MemTable: 成功写入 WAL 后,将键值对写入内存中的 MemTable。MemTable 维护数据的有序性。
- MemTable 切换: 当 MemTable 达到预设大小阈值时,它会变为 Immutable MemTable(只读),并创建一个新的空 MemTable 来接收后续的写入请求。
- Flush (刷新): 后台线程会将 Immutable MemTable 中的数据顺序写入磁盘,生成一个新的 L0 层的 SSTable 文件。写入完成后,Immutable MemTable 即可被回收。
整个写入过程主要涉及内存操作和 WAL 的顺序追加,因此具有非常高的写入吞吐量。
4. 读取流程
LSM-tree 的读取流程相对复杂,因为它需要从多个地方查找数据:
- 查询 MemTable: 首先在当前的 MemTable 中查找数据。如果找到,则返回。
- 查询 Immutable MemTable: 如果当前 MemTable 中没有,则在 Immutable MemTable 中查找。如果找到,则返回。
- 查询 SSTable (L0 层): 如果内存中都没有,则从 L0 层的 SSTable 文件中查找。由于 L0 层文件可能存在键范围重叠,需要检查所有可能包含该键的 L0 文件。
- 查询 SSTable (L1 到 LN 层): 如果 L0 层也没有,则从 L1 层开始,逐层向下查找。由于 L1 及以上层级的 SSTable 键范围不重叠,可以利用索引和布隆过滤器快速定位到可能包含该键的 SSTable 文件,然后进行查找。
- 返回结果: 找到最新版本的数据后返回。如果所有地方都未找到,则表示数据不存在。
这种多层查找机制可能导致读放大,即一个读取请求可能需要访问多个文件才能找到最终结果。
5. Compaction (合并) 机制
Compaction 是 LSM-tree 的核心后台操作,它负责将磁盘上不同层级的 SSTable 文件进行合并、清理和优化,以维持系统的性能和空间效率。Compaction 的主要目标包括:
- 减少文件数量: 降低读取时需要检查的文件数量,从而减少读放大。
- 删除过期/被覆盖数据: 清理旧版本数据和已标记删除的数据,回收存储空间。
- 优化数据布局: 确保高层级 SSTable 的键范围不重叠,提高查询效率。
Compaction 通常从 L0 层开始,将 L0 层的 SSTable 与 L1 层的 SSTable 进行合并,生成新的 L1 层 SSTable。如果 L1 层的文件数量或大小超过阈值,则会触发 L1 层与 L2 层的合并,以此类推,直到最高层级。这个过程是渐进式的,在后台异步进行,避免阻塞前台的读写操作。
Compaction 过程会涉及数据的读取、合并和重新写入,因此会产生写放大(实际写入磁盘的数据量大于用户写入的数据量)和空间放大(由于旧版本数据和合并过程中的临时文件,实际占用的磁盘空间可能大于有效数据量)。LSM-tree 的设计者需要在这些放大效应之间进行权衡。
6. LSM-tree 优缺点总结
优点:
- 高写入吞吐量: 主要通过顺序写入 WAL 和 MemTable 实现,避免了磁盘随机 I/O 的性能瓶颈。
- 适用于写密集型场景: 在大量写入操作的数据库中表现出色。
- 数据持久性: WAL 保证了数据在系统崩溃时的恢复能力。
缺点:
- 读放大 (Read Amplification): 读取数据可能需要查询多个 MemTable 和 SSTable 文件。
- 写放大 (Write Amplification): Compaction 过程会多次重写数据,导致实际写入磁盘的数据量大于逻辑写入量。
- 空间放大 (Space Amplification): 由于存在多版本数据和 Compaction 过程中的临时文件,实际占用的磁盘空间可能大于有效数据量。
7. LSM-tree 在 TiDB/RocksDB 中的应用
TiDB 的核心存储引擎 TiKV 使用 RocksDB 作为其本地存储。RocksDB 是 Facebook 基于 LevelDB 改进而来,是一个高性能的持久化键值存储引擎,其内部正是基于 LSM-tree 结构。TiDB 通过 TiKV 利用 RocksDB 的 LSM-tree 特性,实现了以下目标:
- 高并发写入: RocksDB 的 LSM-tree 结构使得 TiKV 能够高效处理大量并发写入请求。
- 多版本并发控制 (MVCC): LSM-tree 的多版本特性天然支持 MVCC,这对于 TiDB 事务隔离和快照读至关重要。
- 数据压缩: SSTable 可以进行数据压缩,节省存储空间。
TiDB 在 RocksDB 的基础上,通过 Raft 协议实现数据复制和高可用,并通过 Placement Driver (PD) 进行数据分片和负载均衡,构建了一个完整的分布式数据库系统。
8. 架构图
下图展示了 LSM-tree 的核心组件及其数据流转过程:
9. 总结
LSM-tree 是一种强大而复杂的存储结构,它通过巧妙地利用磁盘顺序写入的优势,解决了传统 B-tree 在写密集型场景下的性能瓶颈。尽管它带来了读放大、写放大和空间放大的挑战,但通过精心的 Compaction 策略和参数调优,LSM-tree 仍然是许多高性能数据库(如 TiDB/RocksDB)的首选存储引擎。理解 LSM-tree 的工作原理,对于深入理解 TiDB 等分布式数据库的内部机制具有重要意义。