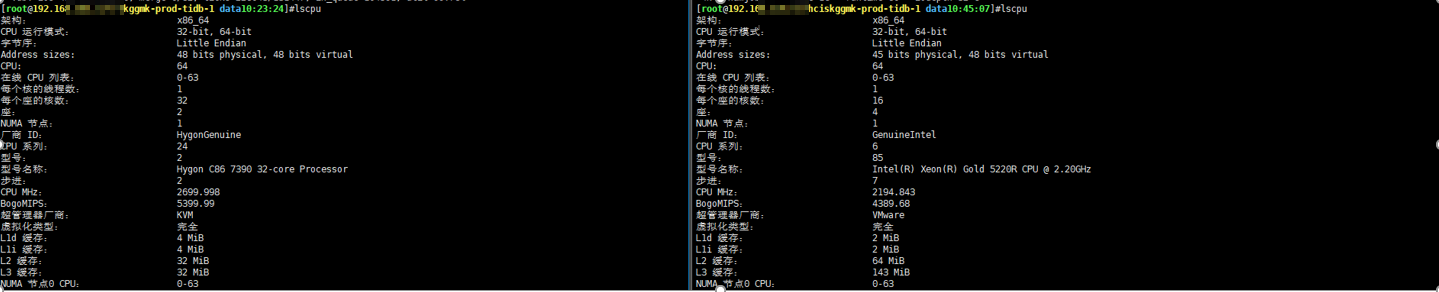
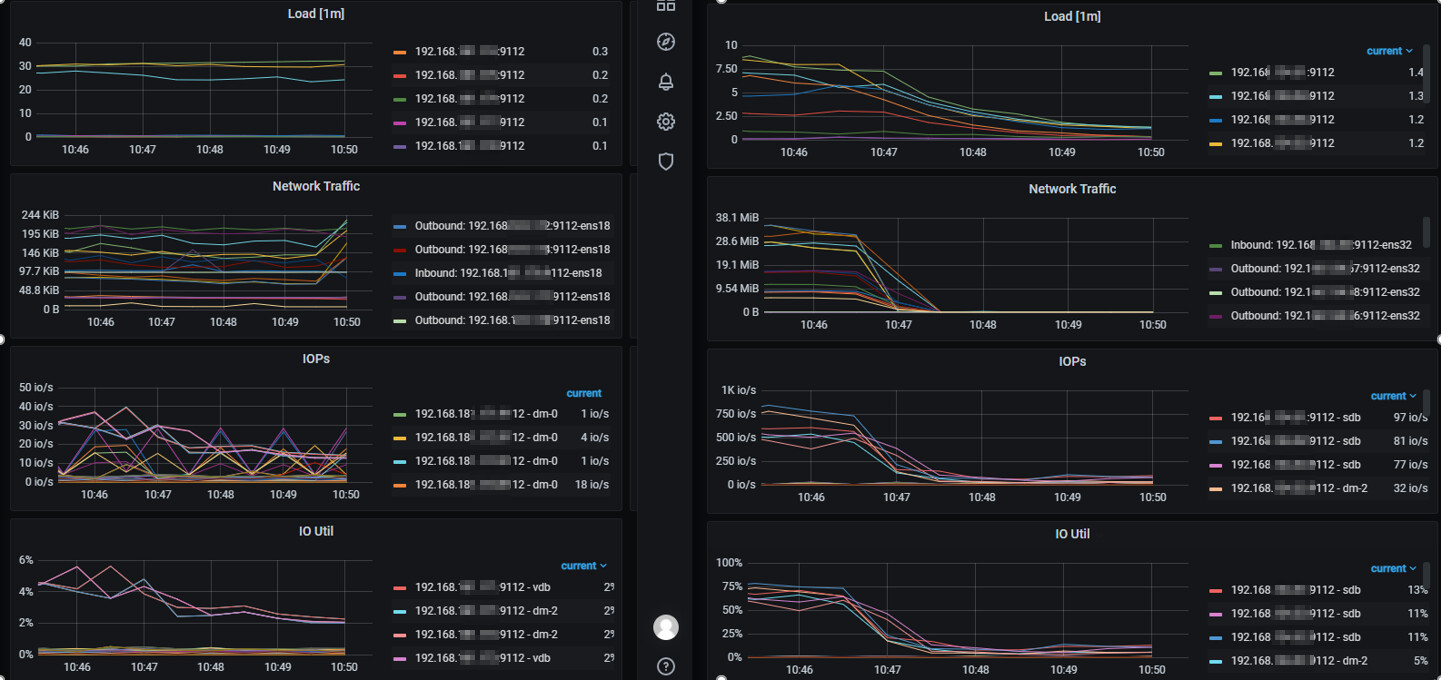
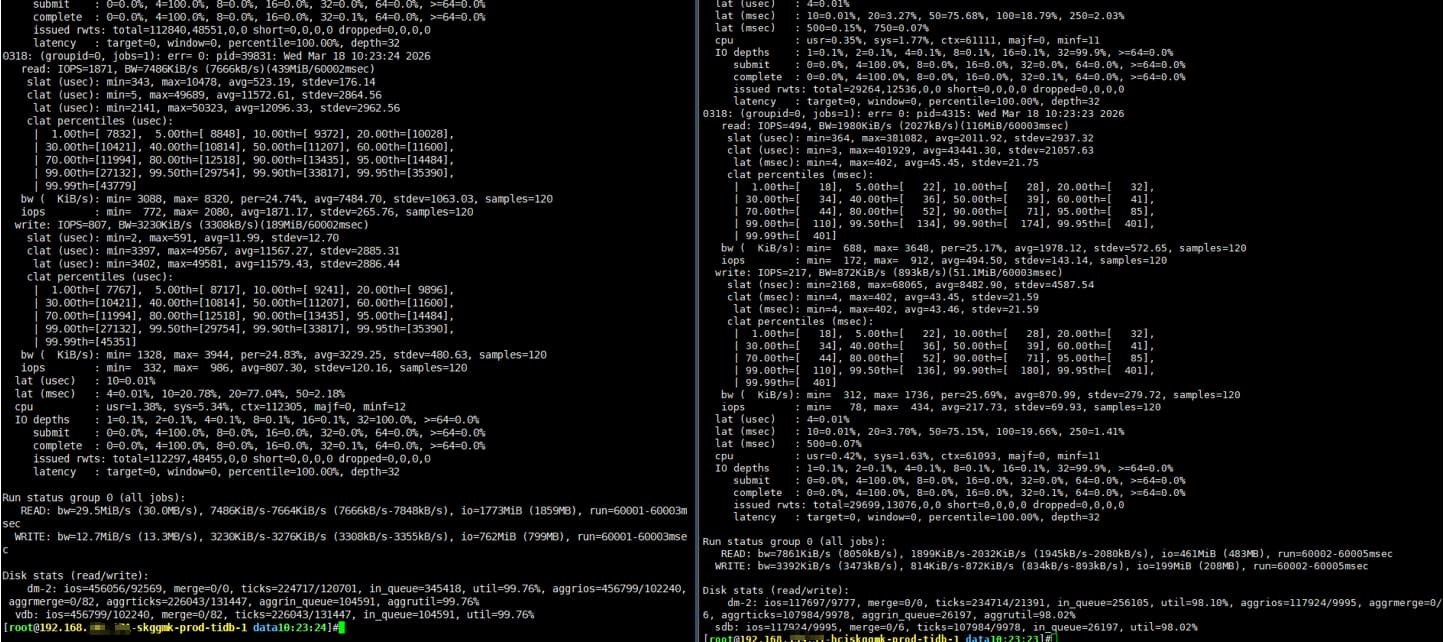
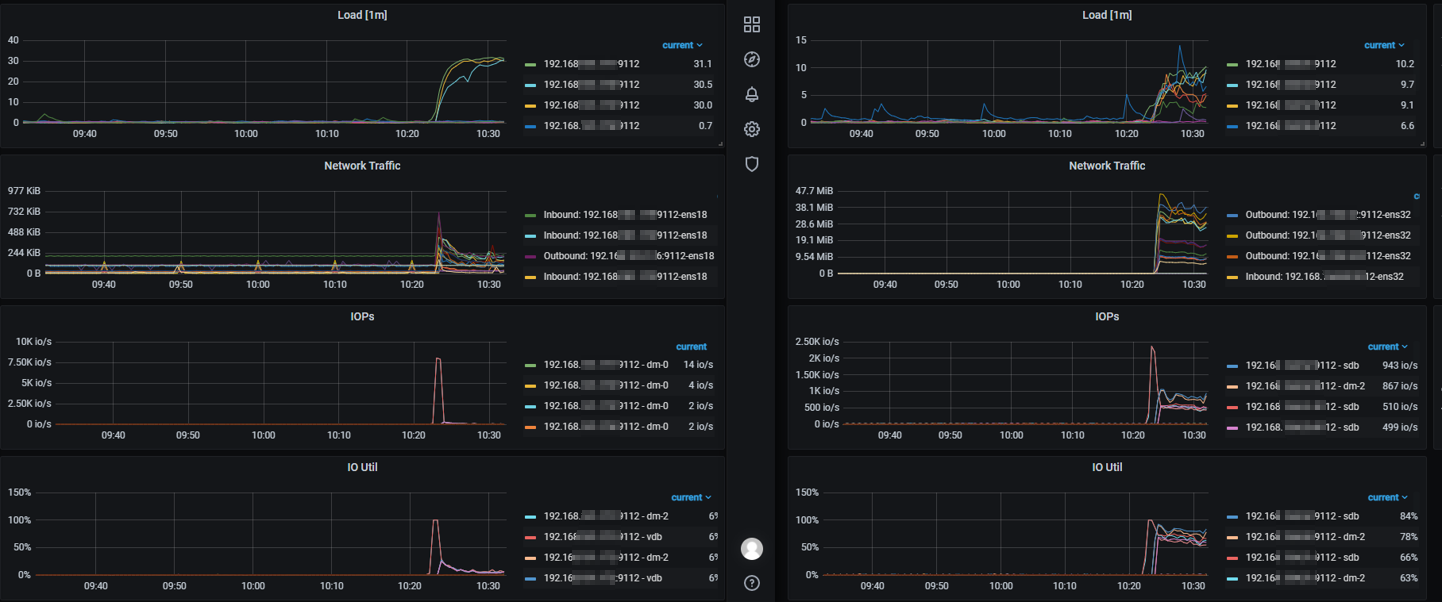
现象:
1、从vmware平台克隆至信创平台后出现明显卡顿现象,数据库配置相同
2、信创环境运行tpcc测试每分钟完成tpmC低于200,旧环境约为60000、(信创环境日志中有err1205超时报错)
3、观察iops监控发现tpcc压测时信创环境约为40 io/s,旧环境可以达到750io/s
4、在单独对磁盘进行fio测试时、信创环境的读写和iops表现更好
##所有截图左侧为信创环境、右侧为旧环境
环境截图:
Tpcc压测时截图:
tiup bench tpcc -H 192.168.xxx.xx4,192.168.xxx.xx5,192.168.xxx.xx6 -P4000 -Uroot -p’XXXXXX’ -D tpcc --warehouses 1000 --threads 100 --time 10m run
fio压测时截图:
fio --name=0318 --ioengine=libaio --rw=randrw --rwmixread=70 --bs=4k --numjobs=4 --size=1G --runtime=60 --iodepth=32
乾坤大挪移
(Ti D Ber A8r Uup Mr)
2
数据库日志刷盘/fsync 在信创平台异常慢
这是我认为优先级最高的排查点。
数据库 TPCC 性能很依赖:
redo/binlog/事务日志写入
fsync 延迟
O_DIRECT / fdatasync 行为
虚拟磁盘控制器对 flush/barrier 的支持
很多虚拟化平台会出现:
fio 测吞吐很好
但 fsync 极慢
或 flush 被虚拟化层放大
或 cache policy 不合适
或写屏障/barrier 导致每次提交都卡住
典型表现
CPU 不高
磁盘带宽不高
IOPS 很低
但事务响应时间极差
锁等待明显增加
建议重点检查
MySQL / MariaDB / openGauss / Oracle 之类都类似,重点看:
redo log 写入等待
log file sync
log file parallel write
fsync 次数和平均耗时
commit latency
binlog sync 延迟
如果是 MySQL 类,可以重点看:
innodb_flush_log_at_trx_commit
sync_binlog
innodb_io_capacity
innodb_flush_method
performance_schema 中 wait/io/file 相关等待
SHOW ENGINE INNODB STATUS
慢日志/事务提交耗时
2 个赞
乾坤大挪移
(Ti D Ber A8r Uup Mr)
3
虚拟磁盘控制器 / 磁盘缓存策略 / 驱动类型不匹配
从 VMware 克隆到信创平台后,磁盘控制器类型变化 非常常见,比如:
VMware 原来是 PVSCSI / LSI Logic
新平台变成了其他虚拟 SCSI / VirtIO / SATA 模式
或启用了低性能兼容模式
也可能是:
write through 导致每次写都真实落盘
cache=none / writethrough / directsync 组合不合理
开启了某些“数据安全优先”的同步策略
存储侧有复制/压缩/去重,导致小写入高延迟
要核对的点
虚拟机磁盘总线类型
磁盘驱动是否装了最佳化驱动
是否使用 virtio-scsi / pvscsi 类半虚拟化驱动
是否启用 write back cache
是否有存储侧同步复制
是否 thin provision 严重碎片化
是否有 QoS 限速
是否开启快照链
尤其注意快照链、精简置备、存储 QoS 限速。
这些都可能让数据库随机写性能雪崩,但 fio 单测不一定完全暴露。
3 个赞
独善其身
(Ti D Ber Bi Rqfz5 K)
4
并发测试的量挺大啊,操作系统端top结果情况怎么样呢
Royce1220
(Ti D Ber Kwxb3 N7 I)
5
看起来tpcc中新环境的磁盘性能和负载完全没有调动起来,可以看看新的平台是不是默认磁盘操作参数比较保守
sonomx
(Ti D Ber Ny Pjt054)
6
贴一下数据库情况的监控,log sync的情况,lock的情况
内存、CPU什么的观察是没什么瓶颈、海光确实和因特尔有差距、但不是主要原因啊
yg_2024
(yangguang)
9
海光芯片配置numa后,性能可以提升10~20%。
yg_2024
(yangguang)
10
看下来,还是怀疑超融合的io存在瓶颈,试试跳过缓存测试io能力呢?
–direct=1:direct=1表示绕过机器自带的缓存,0表示使用缓存