一个好的问题描述有利于社区小伙伴更快帮你定位到问题,高效解决你的问题
【TiDB 使用环境】生产环境
【TiDB 版本】v8.5.4
【部署方式】云上部署(腾讯云)/机器部署
【操作系统/CPU 架构/芯片详情】rocky linux x86
【机器部署详情】CPU大小/内存大小/磁盘大小 32c64g *2
【集群数据量】 600g+
【集群节点数】2
【问题复现路径】跑耗资源的sql
【遇到的问题:问题现象及影响】tidb卡死,找不到导致死机的sql,需要找到影响tiflash死机的sql
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
本集群专门用来做olap,同步mysql的数据过来,定时跑分析任务,或者实时跑分析任务,会有多张大表join再聚合分析,
开启了资源管控(resource control),
开启了中间结果落盘(https://docs.pingcap.com/zh/tidb/stable/tiflash-spill-disk/)
(SET tiflash_mem_quota_query_per_node = 32 << 30;
SET tiflash_query_spill_ratio = 0.8;)
有一定几率导致tiflash卡死,需要找到那条sql,请大佬指导一下吧
ps:不知道是不是和健康度相关,大表健康度可能在90-95之间
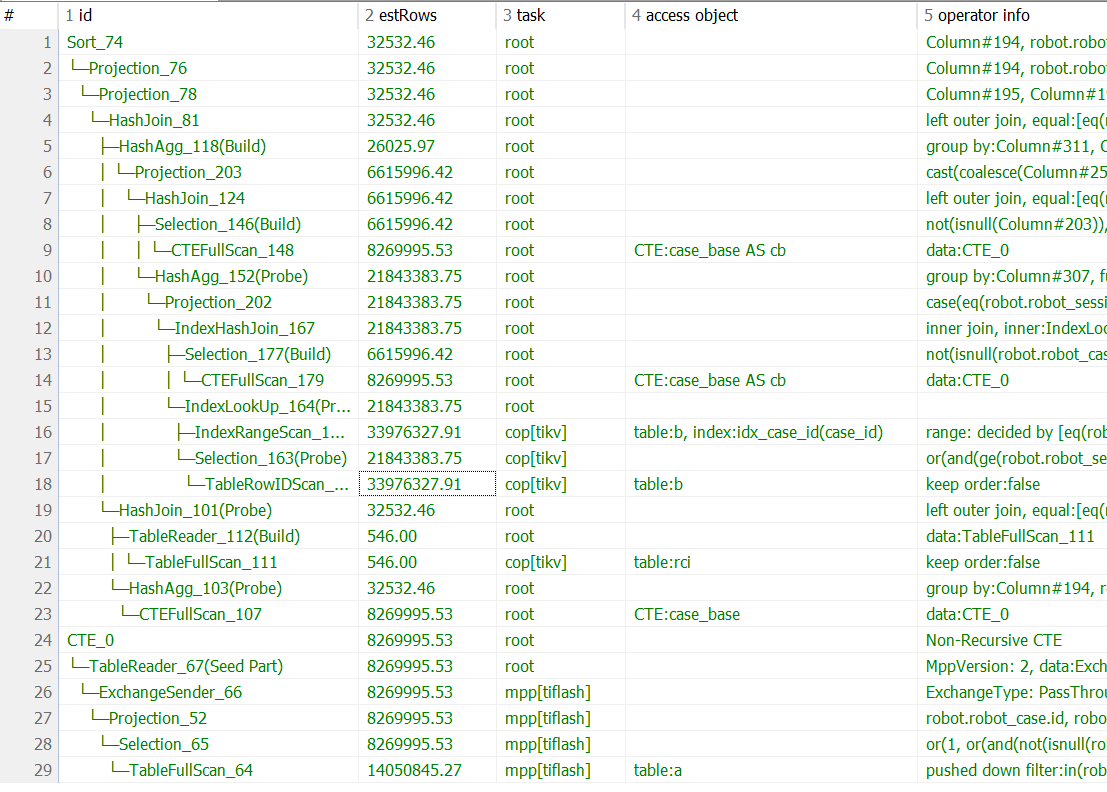
有类似这样的执行计划
你是tiflash 卡死?去dashboard界面慢查询里面找对应时间段的慢sql吧
先扩节点
单节点没办法保证高可用
先用闲置机器把有问题的节点先扩多两个
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
看下节点和资源
TiDBer_SSUU
(Ti D Ber Ssu Uw M5d)
5
去 dashboard 上找对应时间点的长耗时的 sql
lmdb
( : " One day my life will end, and you will wear the crown.")
6
集群节点的配置是不合理的, tiflash 做单独的部署吧
独善其身
(Ti D Ber Bi Rqfz5 K)
7
top SQL语句情况呢,看看执行计划是不是耗时异常了
乾坤大挪移
(Ti D Ber A8r Uup Mr)
10
一般出现 TiFlash 卡死,通常是以下几种情况:
1)TiFlash CPU 100%
特征:
tiflash 进程 CPU 高
查询一直不结束
spill 到磁盘
IO 高
某条 SQL 长时间 running
本质:
大表 Join + 聚合 + Spill 导致执行时间极长
2)TiFlash 内存耗尽或频繁 Spill
特征:
SET tiflash_mem_quota_query_per_node = 32 << 30;
SET tiflash_query_spill_ratio = 0.8;
意味着:
每个查询最多用 32G
80% 就开始 spill
如果:
多个 SQL 同时运行
就会出现:
大量 spill
磁盘 IO 打满
查询卡住
看起来像 TiFlash 卡死。
3)TiFlash 被资源组限制
你开启了:
Resource Control
可能出现:
SQL被限速
线程拿不到资源
表现:
running
但不动
类似卡死。
2 个赞
乾坤大挪移
(Ti D Ber A8r Uup Mr)
11
看看历史慢 SQL
执行:
SELECT
time,
query_time,
digest,
query
FROM information_schema.cluster_slow_query
WHERE query LIKE ‘%tiflash%’
ORDER BY time DESC
LIMIT 50;
2 个赞
Royce1220
(Ti D Ber Kwxb3 N7 I)
12
查查cluster_slow_query看看那个时间点有没有慢查询
Royce1220
(Ti D Ber Kwxb3 N7 I)
15
定位 SQL:过滤 TiFlash 高耗内存查询
立即可用:全局禁用 TiFlash 自动选择,彻底杜绝故障复现
长期方案:2 节点混部必须扩容,否则无法稳定支撑生产