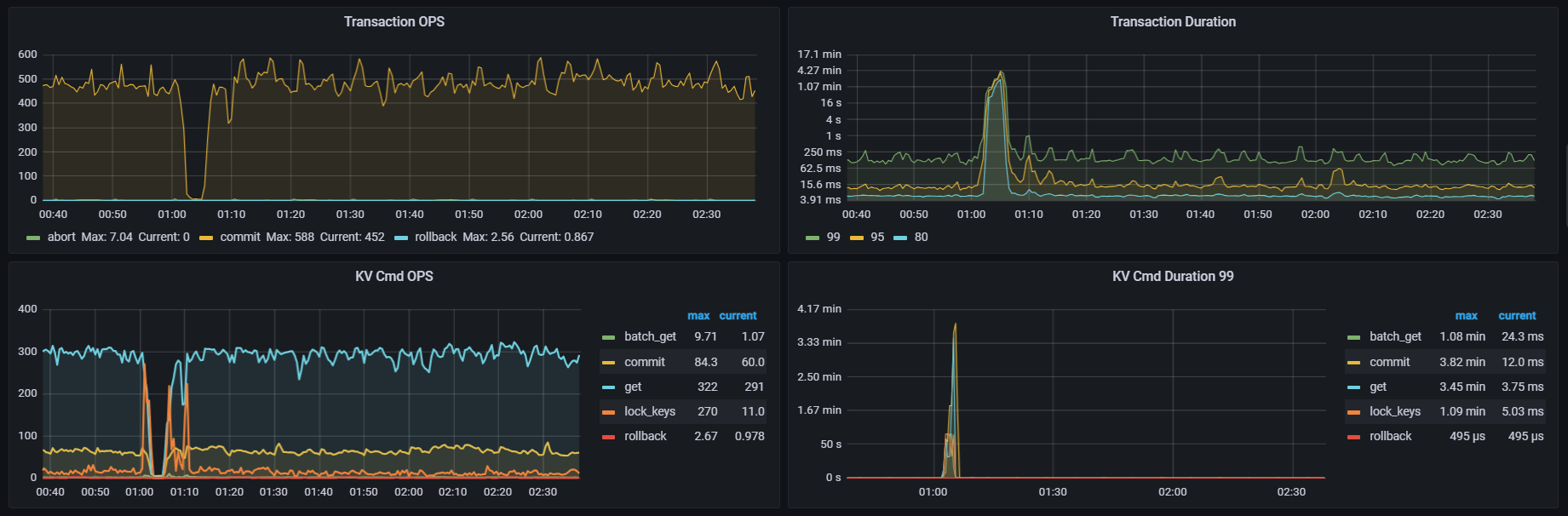
在1点到1点05分的时候客户反馈系统出现故障,排查的时候发现QPS为0,此时的update、delete、select语句执行超过3分钟,该如何排查。
【TiDB 使用环境】生产环境
【TiDB 版本】V5.4.0
【部署方式】物理机
【操作系统/CPU 架构/芯片详情】
【机器部署详情】CPU大小/内存大小/磁盘大小
【集群数据量】
【集群节点数】3tidb 3pd 3tikv
【问题复现路径】此时显示有update、select 、delete语句,慢语句查询超过3分钟,不到3.5分钟。
【遇到的问题:问题现象及影响】此时发现QPS为0,延迟高,如何所示:
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
你先看下那个时候整个集群的资源,是不是cpu什么的都打高了,看上去是有慢语句啊
xfworld
(魔幻之翼)
3
查下磁盘的 IO 情况
然后,查下正在运行的 SQL 是哪些? 看下执行计划和对照扫描的资源,就知道了
yg_2024
(yangguang)
8
QPS掉为0,duration上升,还是怀疑tidb本身组件有问题(特别是PD、TiKV,假如是应用和HA出问题断流,不会导致duration上升)。
一、看看TiDB集群本身可能的问题:
1、普罗米修斯监控里,检查下各个组件的启动时间,排除pd或者tikv异常重启的可能性。
2、普罗米修斯监控里,看看各tikv的region数是否在对应时刻用突然的上升、下降?排除掉region的可能性。
3、通过dashboard再看下对应时刻是否有大SQL。(可能性不高,即便是有大SQL,QPS会下降但不会掉为0)
4、对应时刻是否有定时任务?(备份等,可能性不高,即便是有,QPS会下降但不会掉为0)
二、基础环境层,可能的问题:
5、如果是云环境,可以再看看操作系统日志,排除下云平台对应时刻有大调整。
6、最好在问下客户,对应时刻基础环境是否有变更?排除下网络层的问题(例如:防火墙、核心交换机)
托马斯滑板鞋
(托马斯滑板鞋)
9
直接看那个时间段的主机监控,特别是tikv的(cpu、内存、网络、磁盘)
看截图是整个集群卡住了,导致sql执行时间特别慢
感觉是TiKV 层的 IO 或 CPU 资源耗尽,导致事务提交被阻塞,进而引发整个系统的雪崩。
会不会是有一个超大的事务(例如一次性删除 1000 万行数据)正在运行,它可能会锁住整张表或大量 Region,导致后续所有的 Update/Delete 语句都在排队等待锁释放
每天晚上每隔7分钟删除250000条数据,从20点到第二天3点,就1点5分钟这个时候出问题。
每天凌晨1点5分开始,三个tikv节点的系统盘sda的io达到或者接近100%,持续5分钟左右
克里克里克
(Ti D Ber H052ej9m)
14
可以看看日志和监控,是不是在批量合并region,把IO打满了。
如果你的数据量是海量的,DELETE 操作永远是性能杀手。
- 建议: 对表进行分区(Partitioning) ,按时间(如按月)分区。
- 操作: 清理数据时,直接
DROP PARTITION 。这是毫秒级的操作,瞬间完成且不产生碎片,也不会占用大量IO。
用crontab设置一个定时top任务, 每一分钟一次,看下这时候是哪个进程在跑
可以 登录服务器使用 df -h 和 iostat -x 1 检查磁盘空间和 IO 状况