一个好的问题描述有利于社区小伙伴更快帮你定位到问题,高效解决你的问题
【TiDB 使用环境】生产环境
【TiDB 版本】8.1.0
【部署方式】云上部署腾讯云
【操作系统/CPU 架构/芯片详情】
【机器部署详情】16C32G
【集群数据量】
【集群节点数】pd3节点,db5节点,kv3节点
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
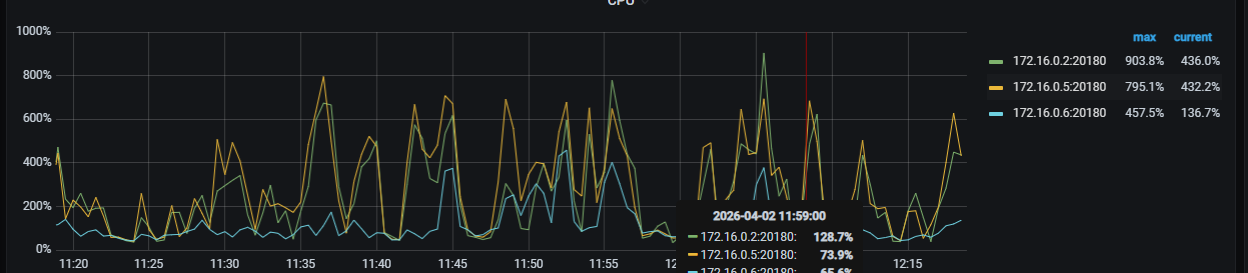
TIKV-SERVER的三个节点均出现在短时间内CPU暴涨超过800%,主要单表数据量在3亿左右,按日分区,日均数据量大概在300万以内,region现在是8530个,每个region小于10M,慢查询sql也看了不多,也处理了,还是会这样,这是grafana的截图:
请教下怎么排查问题,TIDB新手,接手上一任的工作,之前没用过
1 个赞
yg_2024
(yangguang)
2
这块的cpu使用率800%,指的是用了8核,如果服务器是32核,那么实际的cpu使用率相当于是top里的25%,其实资源还有很大富余量。
感谢回答。问题解决了,是因为一个slow query导致的阻塞(错误的用了like导致未走索引,查询一次需要20S左右),不是AI说的region个数的问题,但是我比较奇怪的是这个版本发布已经有10来天了,直到今天才爆出问题,是表示这个sql本身的慢查询并不是直接致命,而是慢慢堆起来的结果吗,因为我看了下这个slow query有10000多个了
Royce1220
(Ti D Ber Kwxb3 N7 I)
6
其实也要看业务的情况,如果使用的多,sql执行的次数多,每次执行都很慢,可能就慢慢堆积了
你是不是混部了?
这种看上去很像和某个组件互相影响~
进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
koby
(Ti D Ber Bk7apg Dl)
11
我也刚刚遇到这个情况,不过我的是偶发,也没看到有slow sql
确实是混布的,一共5台机器,其中三台pd、db、kv都布了,另外两台布了db
dashboard这个交接给我的人说没开
现在跑了10个月左右,现在数据量大概23亿,也就4G左右,但是我看region已经有15K了,我不知道这个是不是正常,昨天AI有给出修改region分裂的阈值,但是没敢操作,请问这个影响很大吗
system
(system)
关闭
16
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。