【业务模型】
业务侧,客户端直接通过tikv go client进行tikv事务读写,不经过tidb;
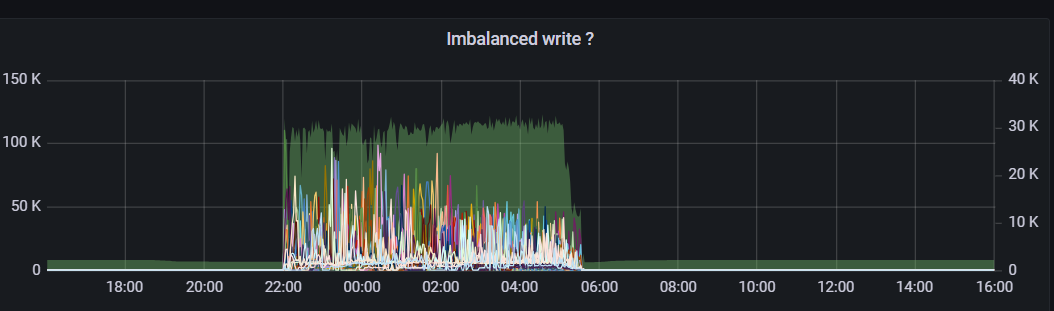
每天晚上到凌晨(22:00-6:00),客户端有集中tikv请求,且QPS是周期脉冲型(即,请求集中期间,交替出现约3min的高QPS和约3min的低QPS)
整个集群里的Region数量不多,约5K
【遇到的问题:问题现象及影响】
在上述集中请求期间,PD Leader的CPU也随着tikv请求大幅波动,占用率最高可达7000%到8000%。通过pprof和perf定位到futex内部自旋占的CPU时间占比最大,pprof定位到futex调用方是go runtime的gc和调度器,没能直接和tso、心跳、operator等pd业务路径建立联系
这个集群按照官方文档修改过tso生成参数,但官方文档目前的写法是这种改法只会影响【10%】的CPU占用率。另外一个无法解释的现象是,另一个硬件条件相同、采取同样参数修改方式但负载形态不同的集群(tikv请求数目高且恒定,非脉冲)没有出现cpu占用的异常升高。参数如下所示:tso-update-physical-interval: 1ms
TSO 配置文件描述 | TiDB 文档中心
【部署方式】
物理机。受到客观条件限制,PD Leader所在节点上还有2个tikv服务,pd和tikv都部署在nvme磁盘上。此外,该节点上还有若干个内置tikv go client的服务,该服务的QPS也和PD/TiKV QPS有同样的周期。集群的其他每个节点也有2个tikv服务和这些tikv client(与问题节点的区别就是没有PD Leader),其CPU占用情况可参考监控截图。
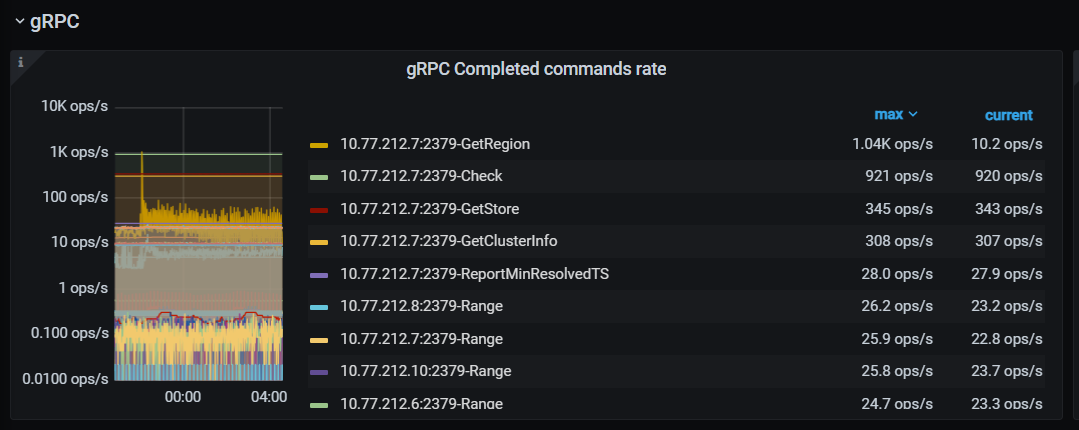
【监控有关截图-有问题的集群】

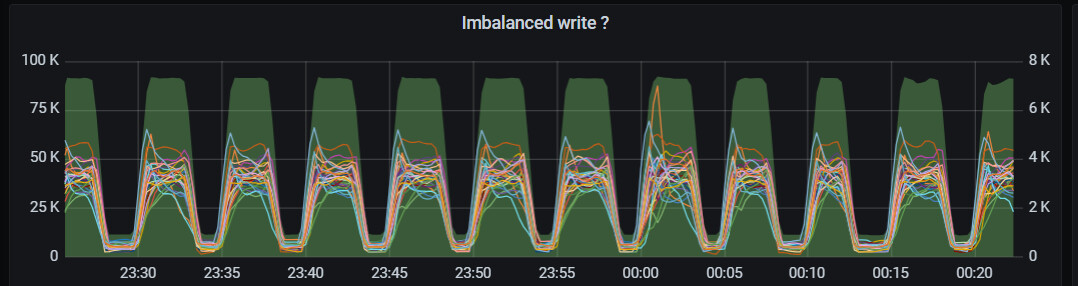
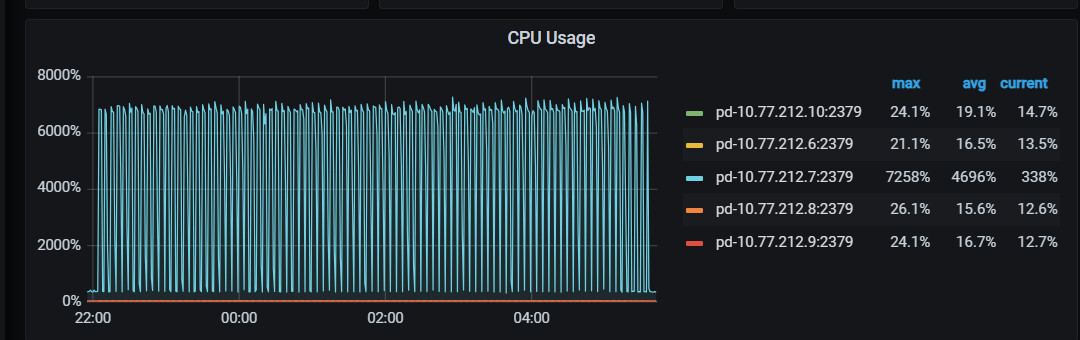
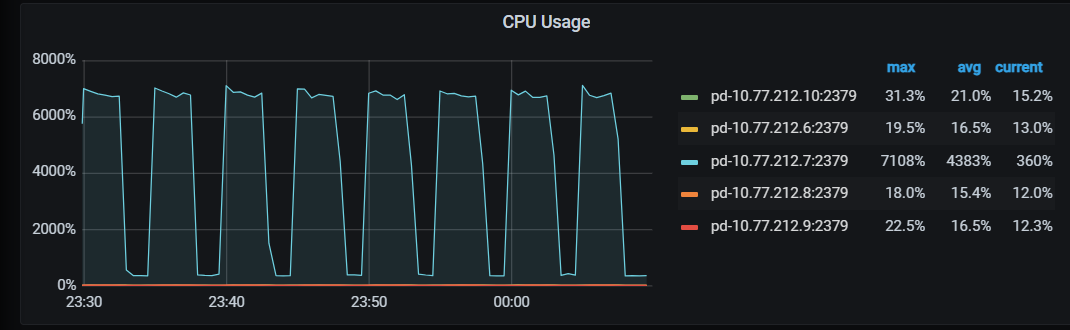
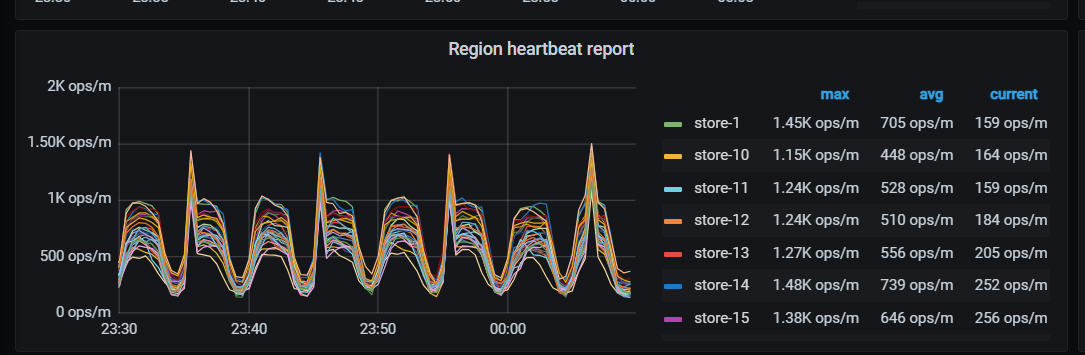

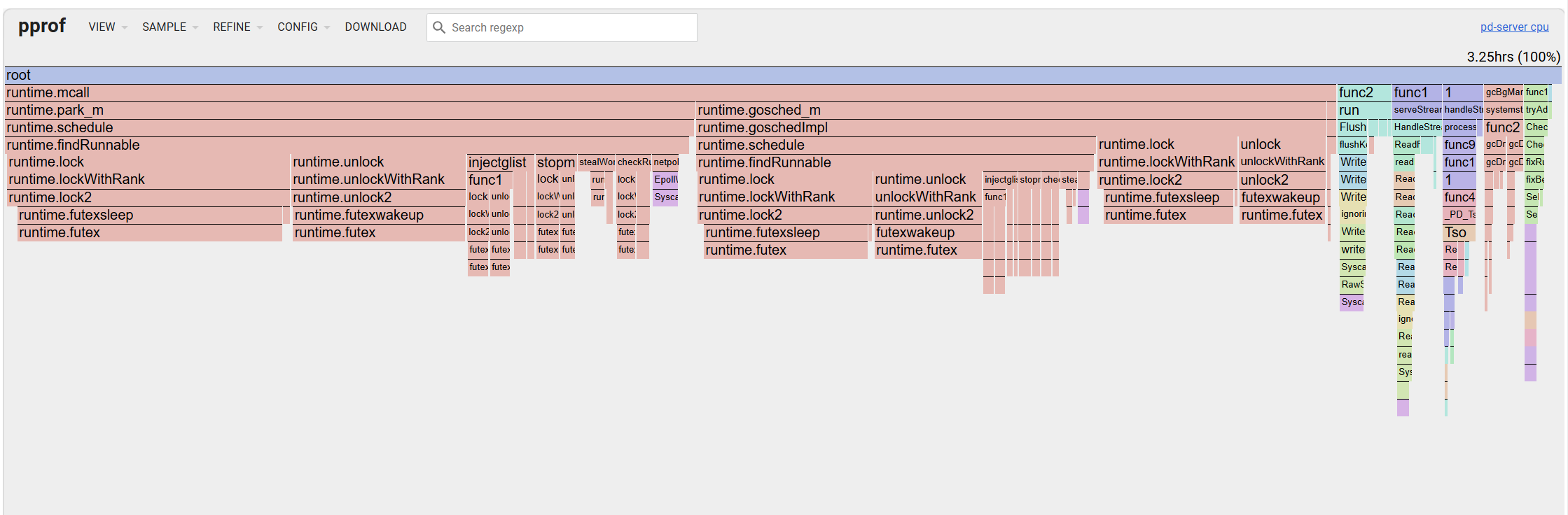
【pprof火焰图】
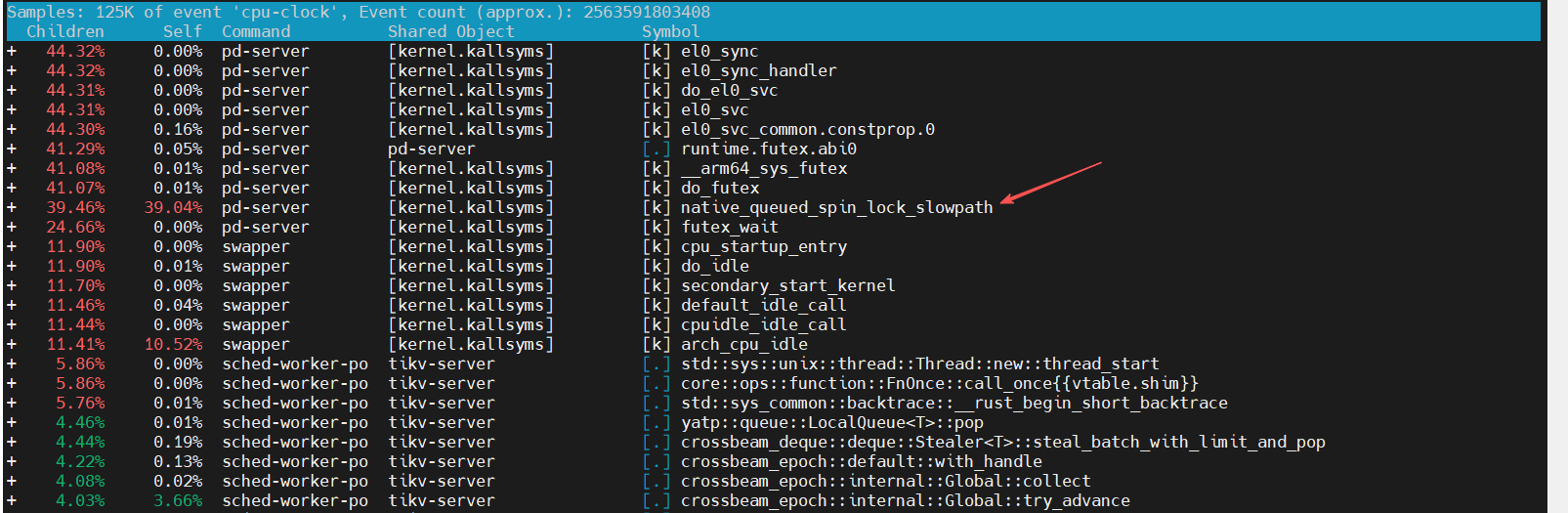
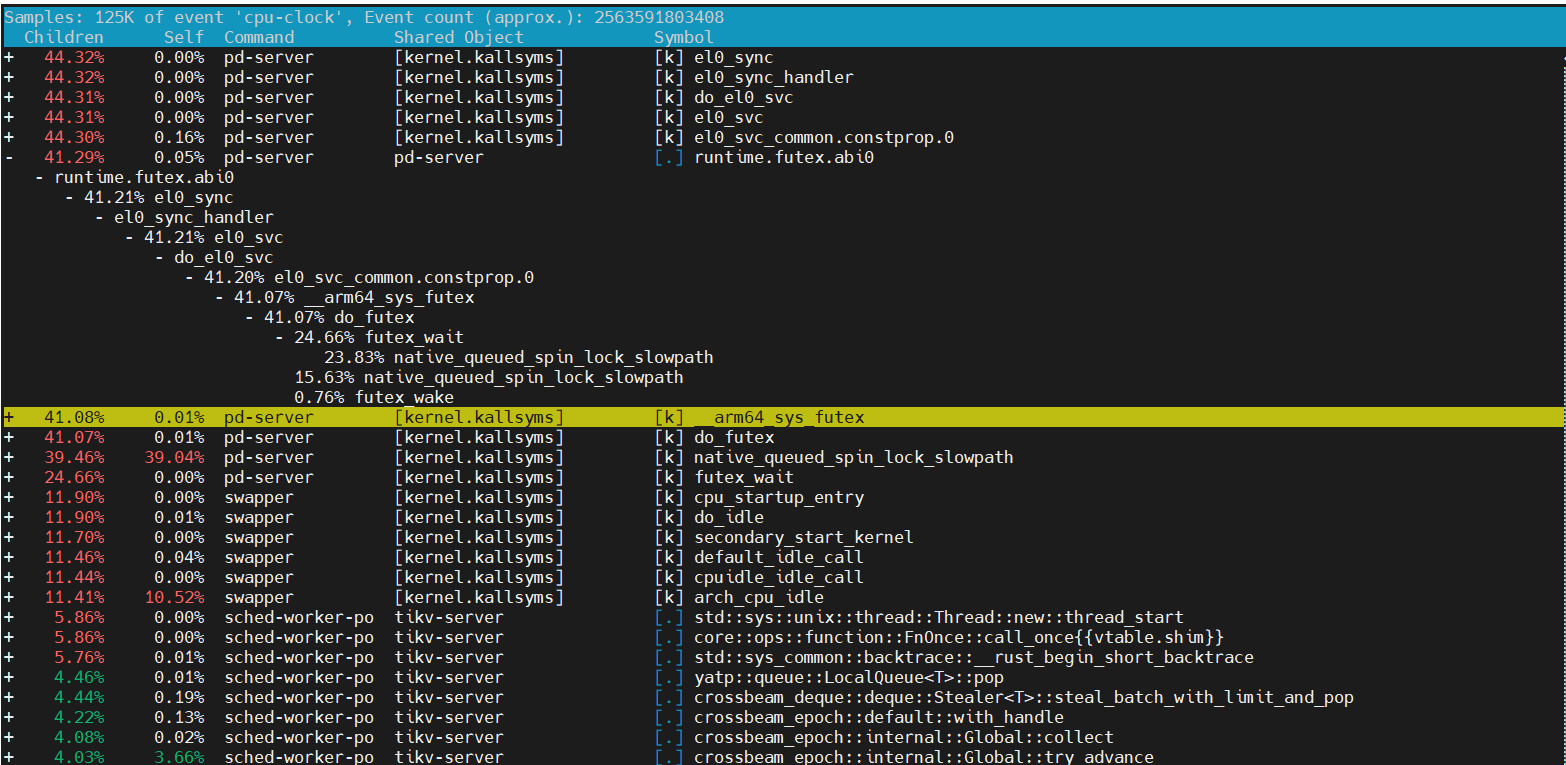
【perf符号表】
【TiDB 使用环境】生产环境
【TiDB 版本】v8.5.3
【kernel版本】
5.10,定制发行版
【CPU】
Architecture: aarch64
CPU op-mode(s): 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Vendor ID: HiSilicon
BIOS Vendor ID: HiSilicon
Model name: Kunpeng-920
BIOS Model name: HUAWEI Kunpeng 920 7260
Model: 0
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
Stepping: 0x1
BogoMIPS: 200.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop asimddp asimdfhm
Caches (sum of all):
L1d: 8 MiB (128 instances)
L1i: 8 MiB (128 instances)
L2: 64 MiB (128 instances)
L3: 128 MiB (4 instances)
NUMA:
NUMA node(s): 4
NUMA node0 CPU(s): 0-31
NUMA node1 CPU(s): 32-63
NUMA node2 CPU(s): 64-95
NUMA node3 CPU(s): 96-127
【内存大小】376GB
【集群数据量】2.1T
【集群节点数】10台物理机,每个物理机上2个tikv实例
【问题复现路径】见业务模型描述
【附:上下游另一个比较正常的集群】
该集群8个节点,每个节点上有6个tikv。同样不使用tidb。tikv配置(含tso)、CPU型号和系统版本与之前的集群相同。该集群有约45K个Region。和上面的集群接入的是不同的tikv go client,但这些tikv client请求之间有上下游关系。(注:该集群同样设置了tso-update-physical-interval: 1ms)

想问下各位是否有可排查的方向,非常感谢!
UPD:破案了,region对pd的心跳间隔调的太小了