【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.5.6
【复现路径】
【遇到的问题:问题现象及影响】
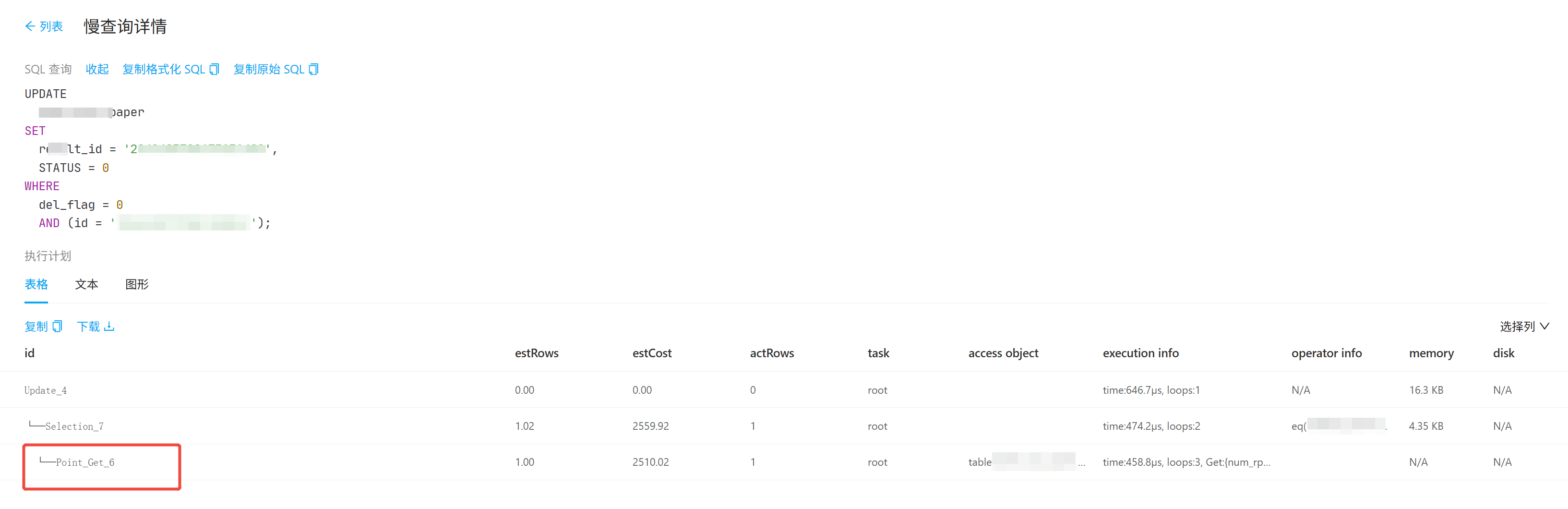
一个point_get操作执行时间超过3秒,伴随的现象,有一个事务重试
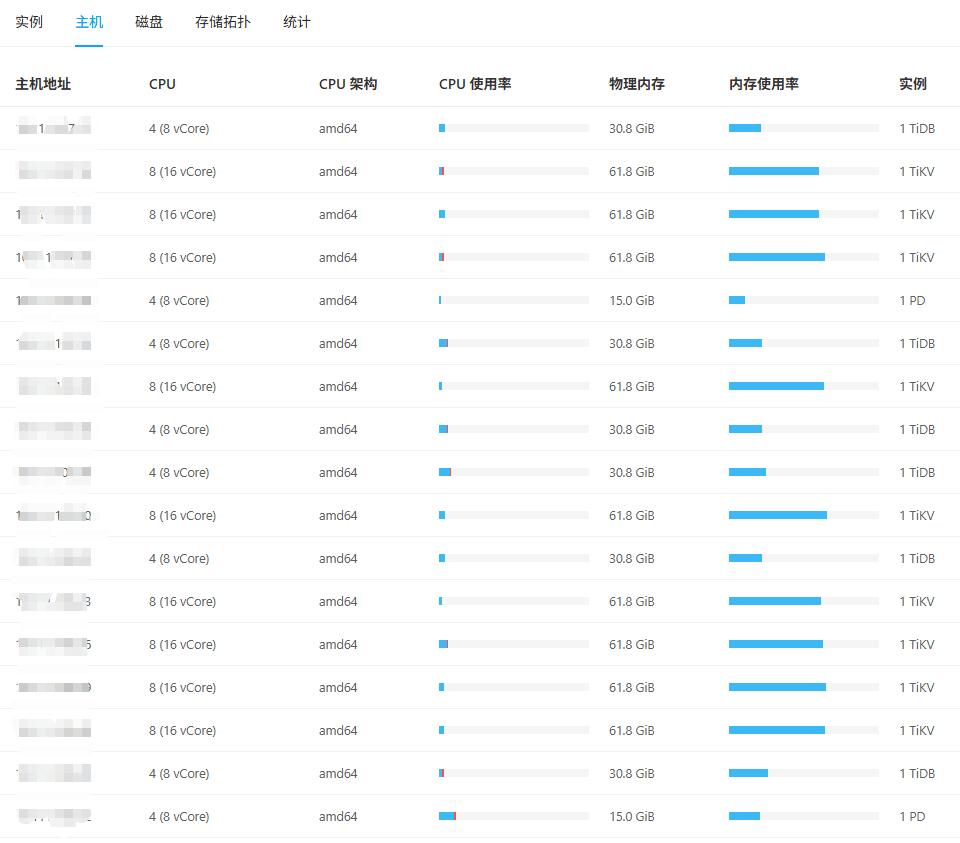
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.5.6
【复现路径】
【遇到的问题:问题现象及影响】
一个point_get操作执行时间超过3秒,伴随的现象,有一个事务重试
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
看一下你的部署情况
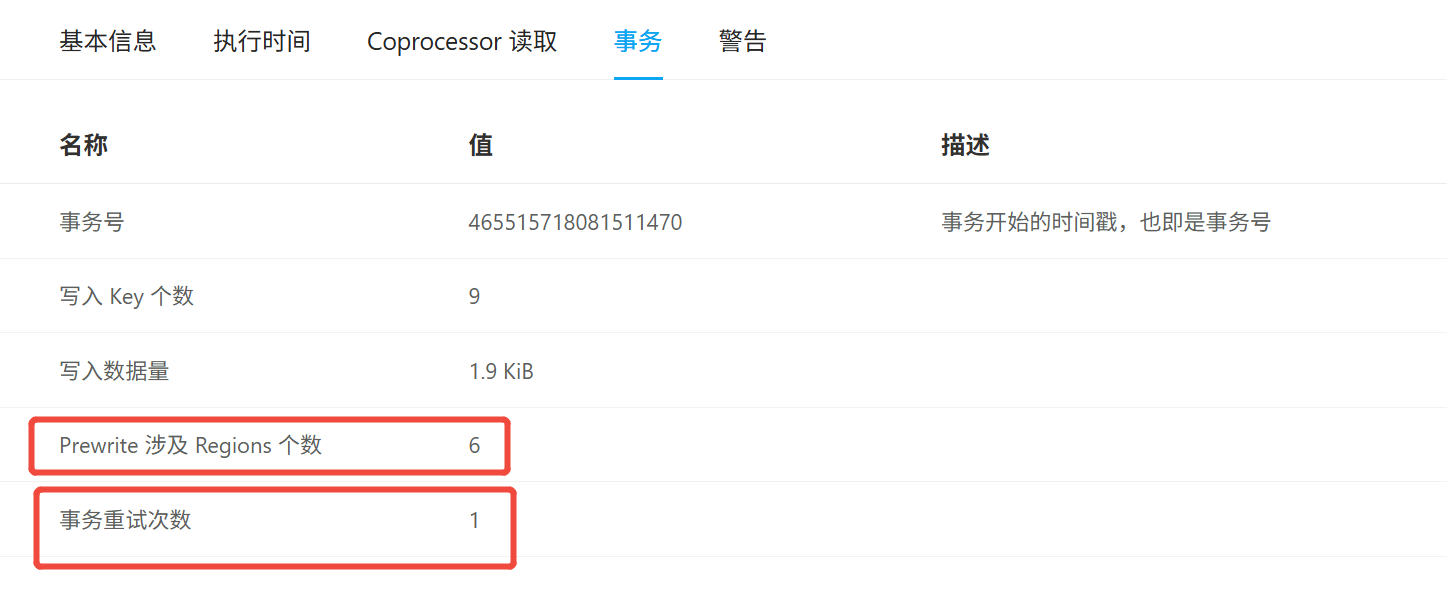
Prewrite 阶段本身耗时极高:大概率是事务涉及的 TiKV 节点数量多、数据分布分散、网络延迟高,或 TiKV 负载过高
Commit 阶段多次重试:Prewrite 完成后,Commit 请求持续失败,导致大量 Backoff 等待,最终拖慢整个 SQL
tikv负载不高,每次出现这个问题,都会有一个事务重试
基本可以判断是 TiDB 事务冲突或锁等待导致的 point_get 延迟 。
典型场景:
update user set age=20 where id=1;
同时另一个事务:
select * from user where id=1;
或
update user set age=21 where id=1;
TiDB 会发生:
Write Conflict
或
Lock Conflict
流程:
事务A锁住key
↓
事务B point_get
↓
等待锁
↓
超时
↓
事务重试
就会看到:
point_get 3秒
txn retry
因为 TiDB 有:
锁等待机制
默认:
wait 3s
所以表现为:
point_get执行3秒
实际上是:
等锁3秒
不是查询慢。
例如:
订单表
库存表
账户表
大量:
update account set balance=balance-1 where id=100;
多个事务同时操作。
结果:
锁冲突
事务重试
point_get变慢
例如:
begin;
update order set status=1 where create_time<‘2024-01-01’;
commit;
修改:
10万行
期间:
select * from order where id=1;
也可能等待锁。
因为:
事务未提交
锁未释放
如果是:
pessimistic transaction
流程:
point_get
↓
加锁
↓
等待
↓
冲突
↓
重试
容易出现:
3秒
例如:
自增ID
所有请求集中:
region1
TiKV 压力大。
表现:
point_get慢
事务重试
如何确认是哪种原因
需要看系统表。
select *
from information_schema.slow_query
where query like ‘%point_get%’
order by time desc
limit 10;
关注:
Write Conflict
Lock wait
Backoff
TxnRetry
select *
from information_schema.cluster_tidb_trx;
看:
waiting_start_time
state
select *
from information_schema.data_lock_waits;
可以看到:
谁在等锁
谁持有锁
这是最关键的。
select *
from information_schema.cluster_tidb_trx;
关注:
retry_count
TiDB 日志:
txn retry
write conflict
lock wait
backoff
例如:
txnRetry
backoff: tikvLockFast
或
Write conflict
这就能确认。
锁等待严重?
这个慢查询的本质不是 SQL 执行慢,而是单条更新触发了跨 6 个 Region 的分布式事务,Commit 阶段重试等待 3.6 秒导致耗时爆炸,核心优化方向是减少索引、对齐分区、优化事务模式,从根源上避免跨 Region 事务和重试。