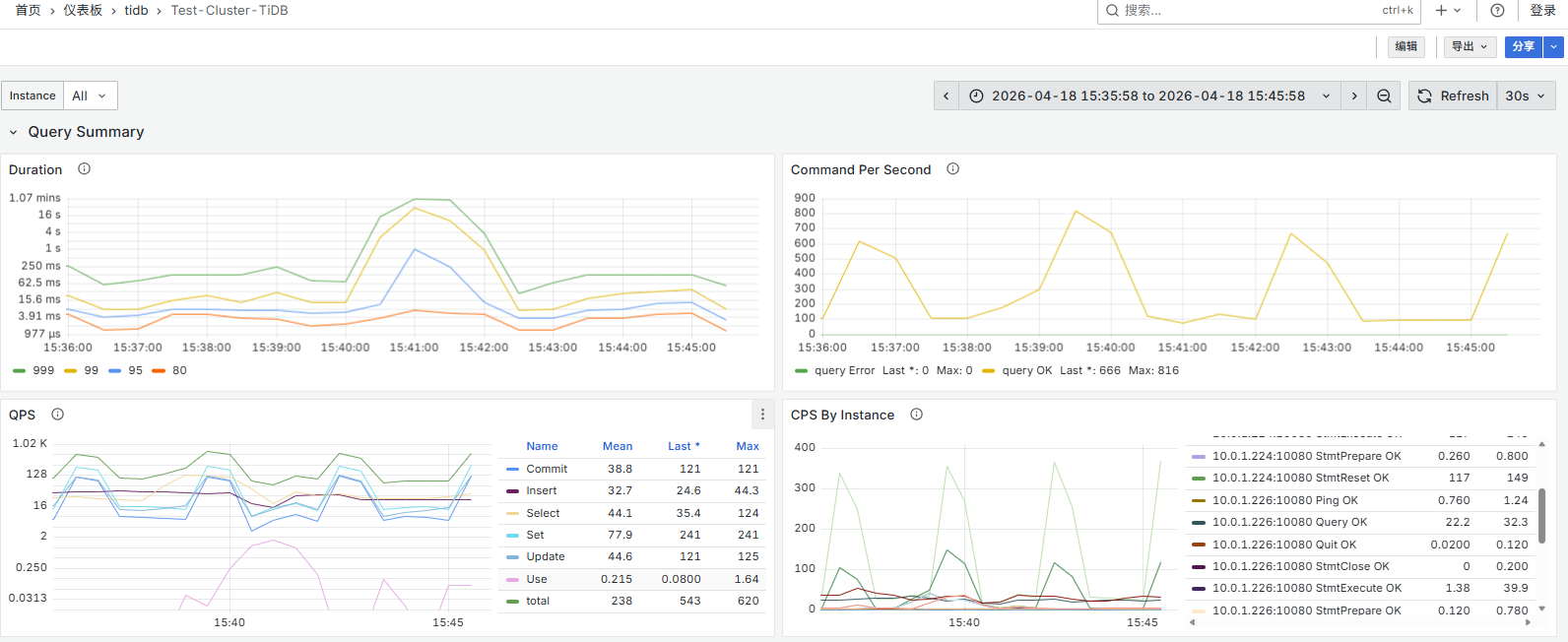
一个好的问题描述有利于社区小伙伴更快帮你定位到问题,高效解决你的问题
【TiDB 使用环境】生产环境
【TiDB 版本】8.85.5
【部署方式】机器部署
【操作系统/CPU 架构/芯片详情】
【机器部署详情】PD+TIDB: cpu16核/48G,tikv 16核/64G
【集群数据量】9台,PD+TIDB共用3台, tikv3台,其他是tiflash,ticdc
【遇到的问题:问题现象及影响】突然大量Insert和update变慢,都有30-40秒,引发报警,2分钟后恢复
【资源配置

】
【复制黏贴 ERROR 报错的日志】
超时sql
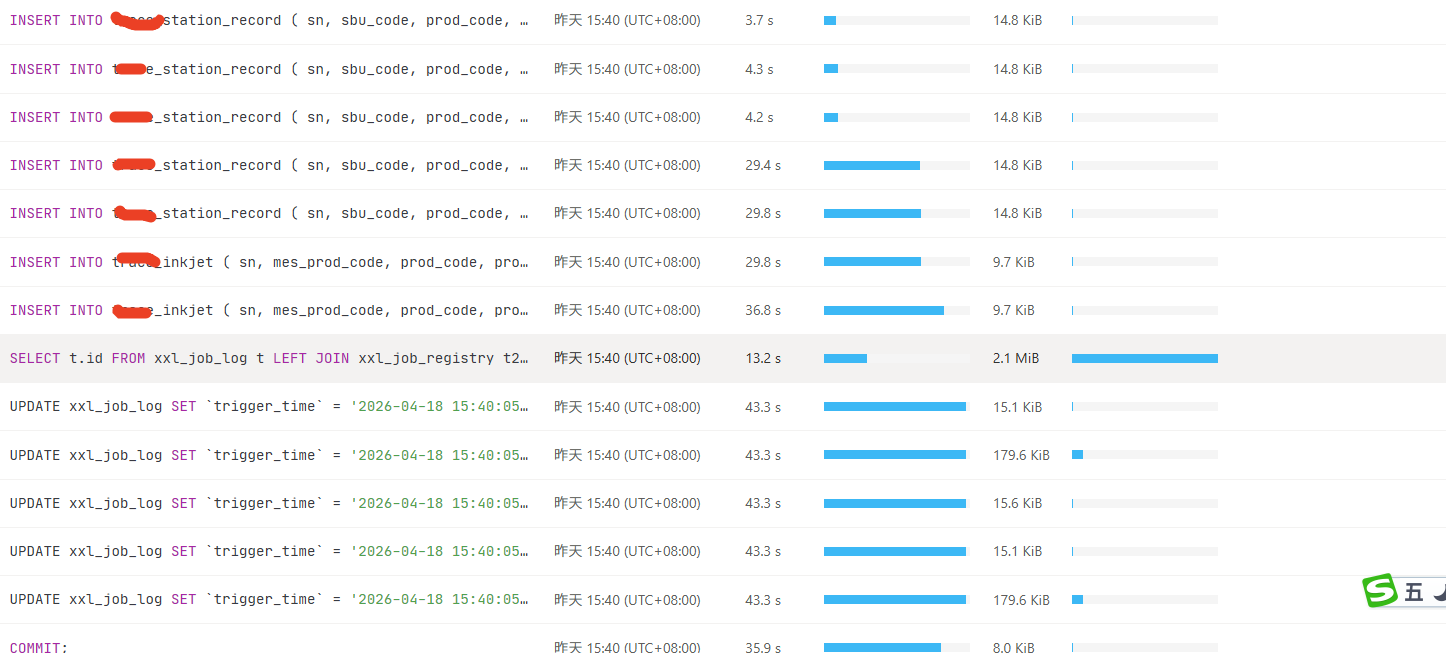
其中一条分析,这条是insert into ON DUPLICATE KEY UPDATE格式:
time:30.2s, loops:5, prepare: 53.7s, check_insert: {total_time: 30.1s, mem_insert_time: 436.4µs, prefetch: 30.1s, rpc:{BatchGet:{num_rpc:244, total_time:539ms}, rpc_errors:{stale_command:132, not_leader:103},regionScheduling_backoff:{num:36, total_time:14.5s},regionMiss_backoff:{num:24, total_time:8.51s}, time_detail: {total_kv_read_wall_time: 733.8µs, tikv_wall_time: 857.8µs}, scan_detail: {total_process_keys: 2, total_process_keys_size: 279, total_keys: 3, get_snapshot_time: 64.6µs, rocksdb: {block: {cache_hit_count: 29}}}}}, commit_txn: {prewrite:714.4µs, region_num:1, write_keys:1, write_byte:181, txn_retry:1}, lock_keys: {time:2.25ms, region:2, keys:2, slowest_rpc: {total: 0.002s, region_id: 1895, store: 10.0.1.229:20160, time_detail: {tikv_wall_time: 1.29ms}, scan_detail: {get_snapshot_time: 11.8µs, rocksdb: {block: {cache_hit_count: 9}}}, }, lock_rpc:2.210754ms, rpc_count:2}
【其他附件:截图/日志/监控】

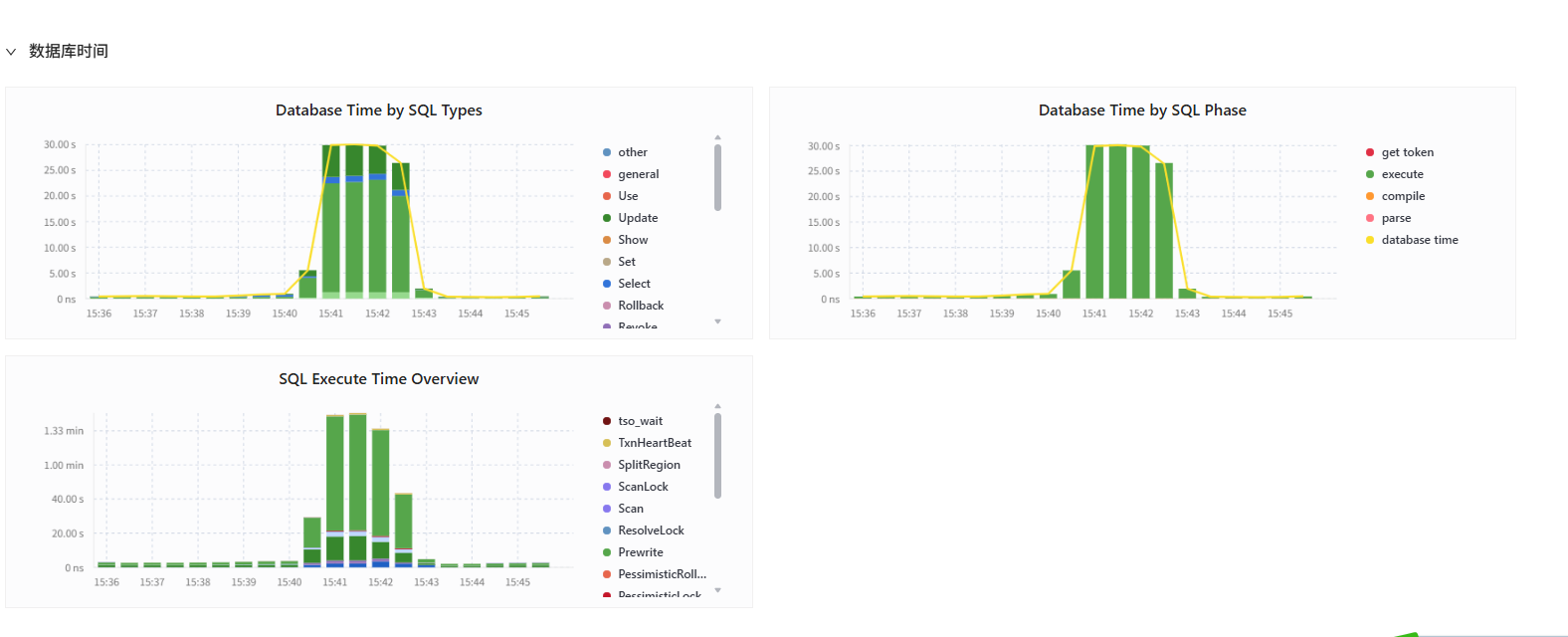

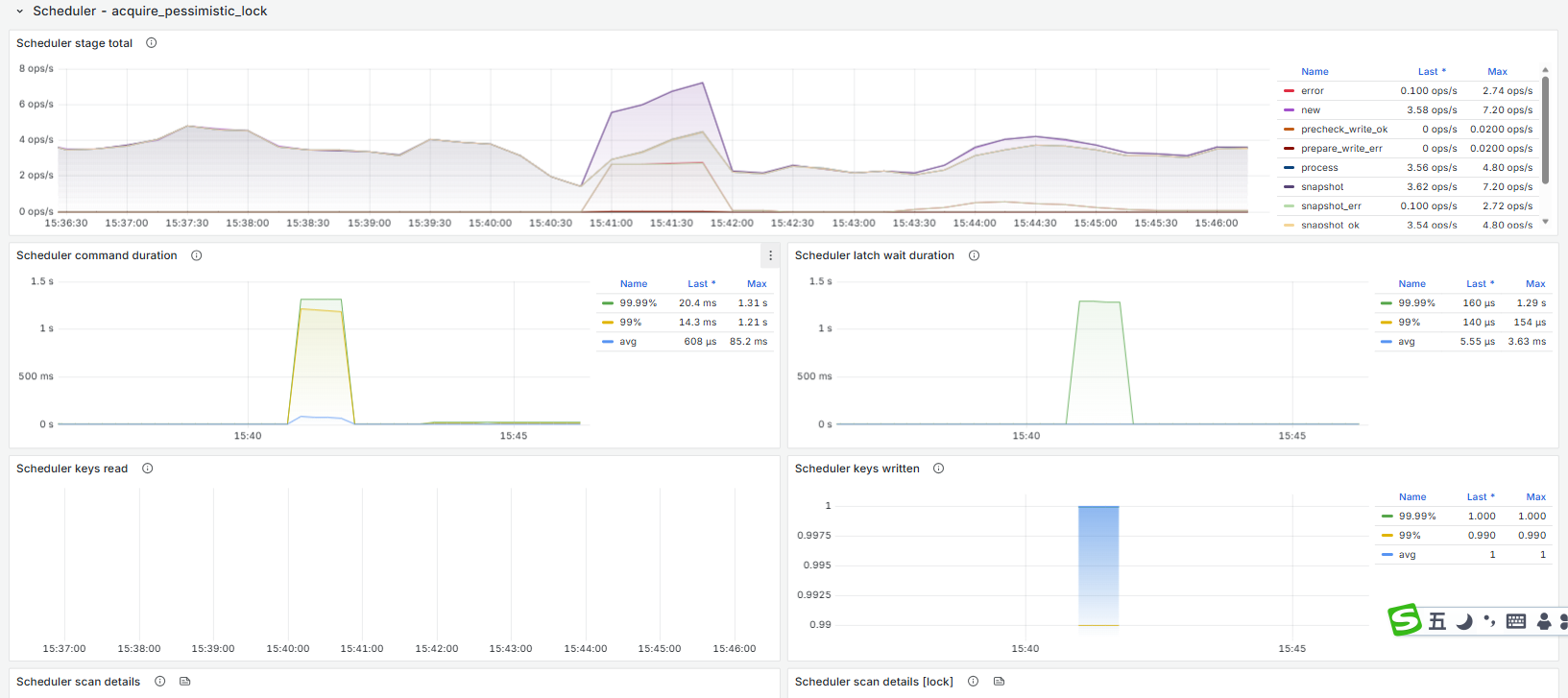
指标太多,完全不知道从何查起. 另外有没类似自动化定位的工具?