backgroud:
阿里云的ecs搭建的tidb集群,使用dm实时同步polardb数据到tidb,连接使用的阿里云的clb。
1、开启br log增量日志备份
tiup br log status --task-name=pitr --pd “192.168.0.124:2379” --storage "***“
2、检查status状态正常,但是一直没有进度
name: pitr
status: ● NORMAL
start: 2026-04-21 22:44:33.607 +0800
end: 2090-11-18 24:44:45.624 +0800
storage: ***
speed(est.): 0.00 ops/s
checkpoint[global]: 2026-04-21 22:44:33.607 +0800; gap=36m41s
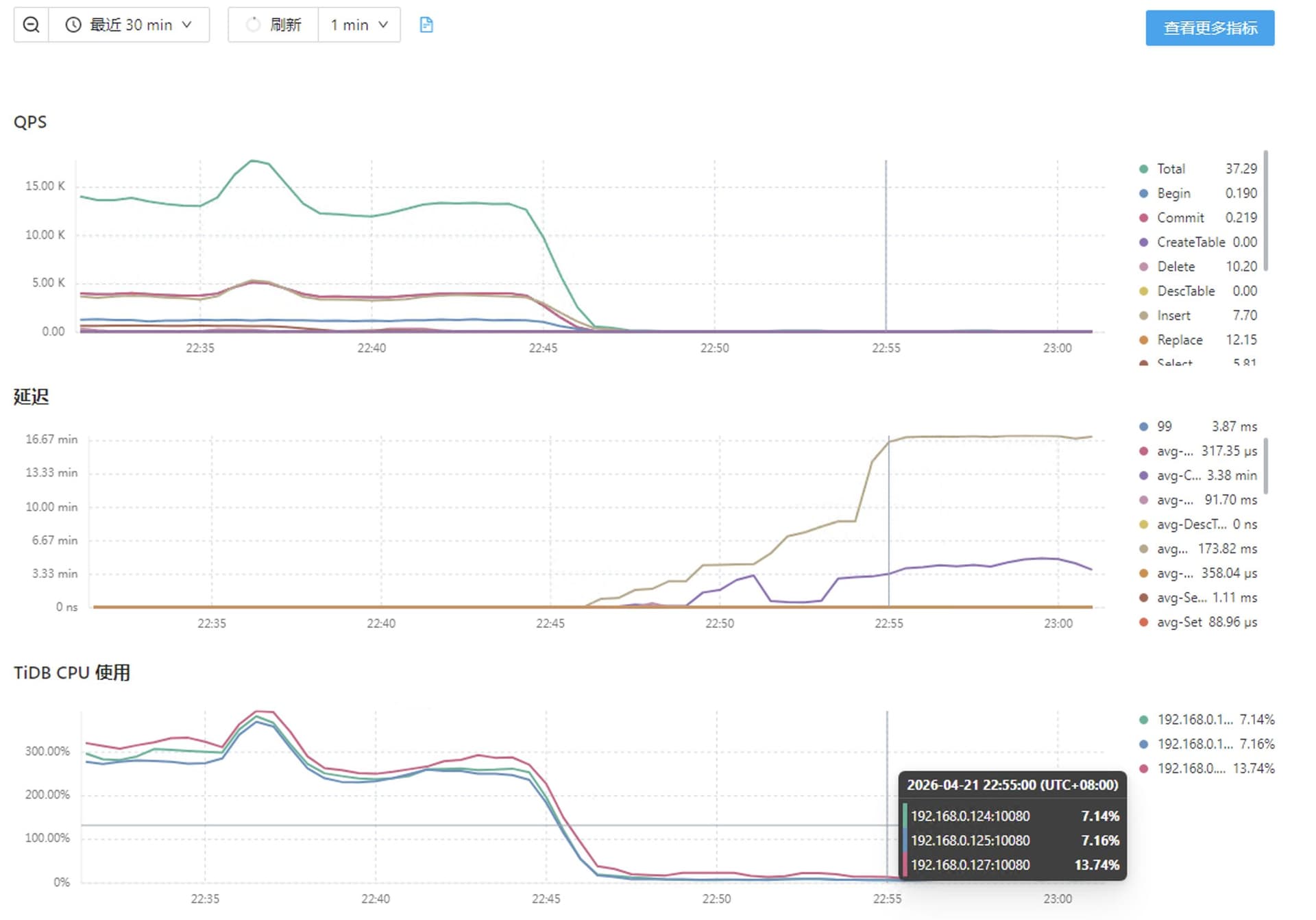
3、开启br log日志备份后集群所有写都阻塞了
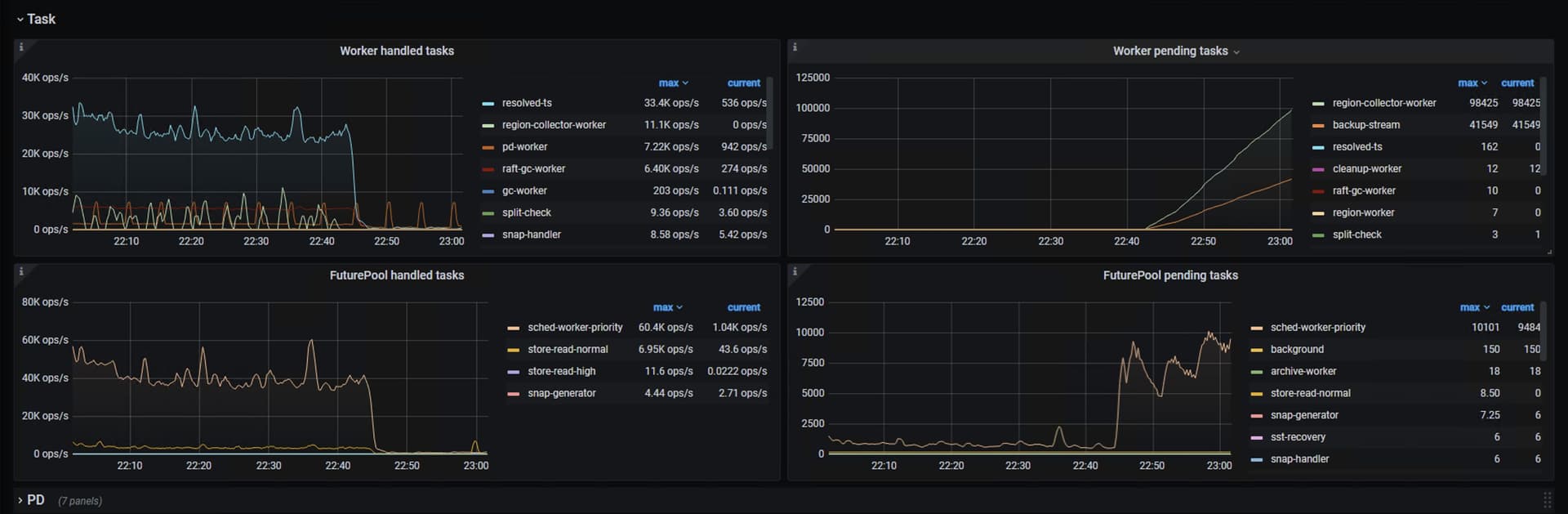
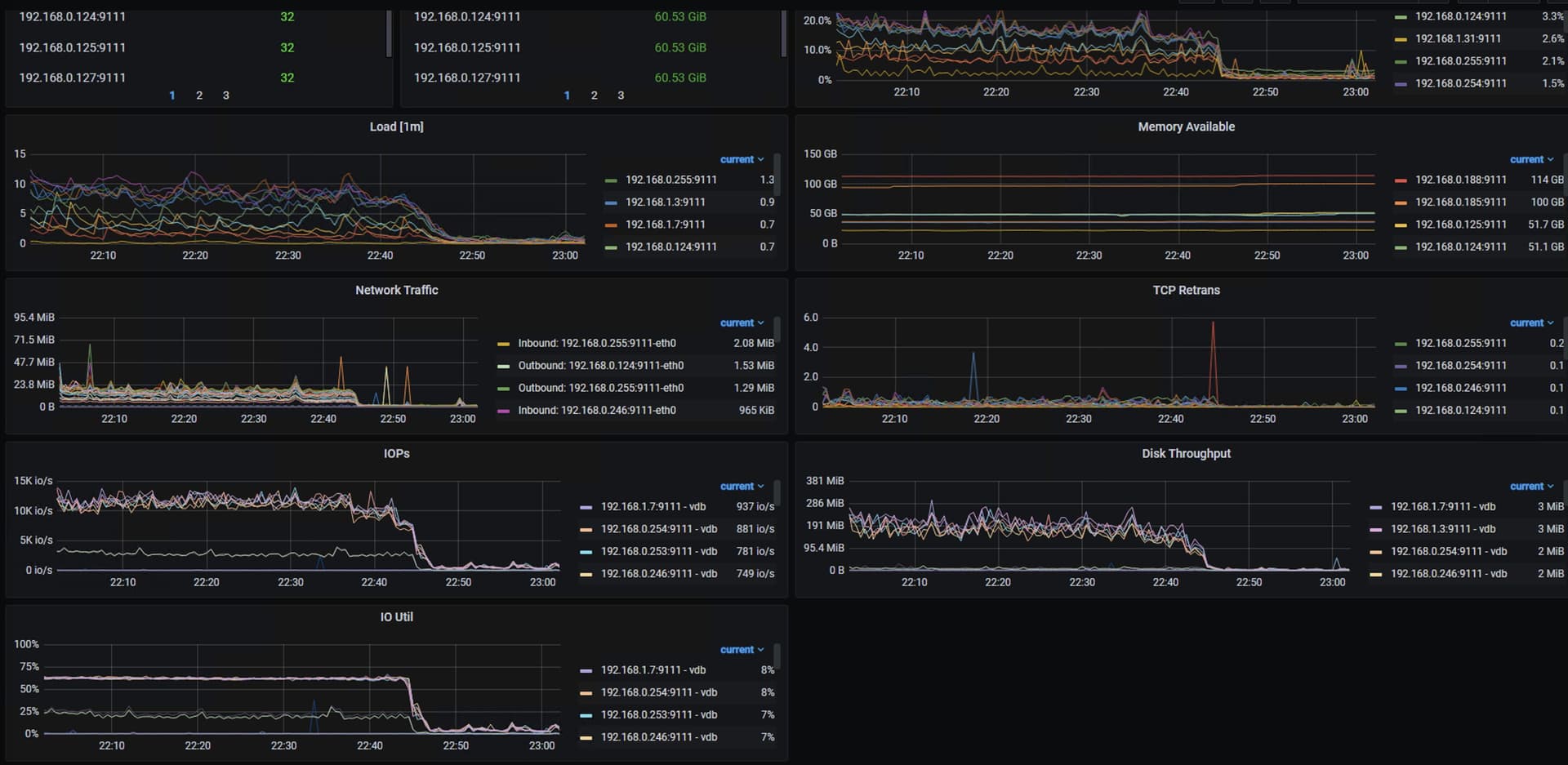
所有机器负载都降下来了,但是schedul pending command和tikv的task都积压起来了。此时stop br log备份也降不下来,不知道是哪儿的问题。重启集群后才恢复
独善其身
(Ti D Ber Bi Rqfz5 K)
2
log操作的IO资源跟不上了吗,有iostat监控信息吗
没有截图,当时看了一下基本没有写了,上面监控截图也可以看出来,基本没有io进来了。
觉得可能是磁盘问题。看看备份的路径有没有写权限,能不能访问到,磁盘有没有满了
写到oss上的,访问都没问题,本地测试都是通的。而且重启集群,集群就正常了,pitr备份也正常推进了
wbslxw
(Ti D Ber Cl S0j Eng)
6
br log 备份任务在 TiKV 侧僵死,占满了 backup-stream 线程池,导致写请求无法调度,即使停止任务也无法自动清理,最终阻塞整个集群。
其实大概率是bug,我们之前开启br log后,也是tikv 的pending task都是backupstream,也是重启集群就好了,但是我们当时遇到tikv 内存升高的问题,我去github 上找到了bug,你也可以去找找
是的,从监控结果看,这个逻辑是对的,有解决办法吗?第一次遇到这个问题都只能重启解决
菩提老祖
(菩提老祖)
10
原因是在tikv测。停掉br log stop 》问题还存在,感觉是没清干净,比如pd 有些pd backup 元数据。
不重启整个集群,滚动重启kV 应该就可以吧
重启kv 就行,这种肯定是遇到什么BUG了,要不然怎么会阻塞呢