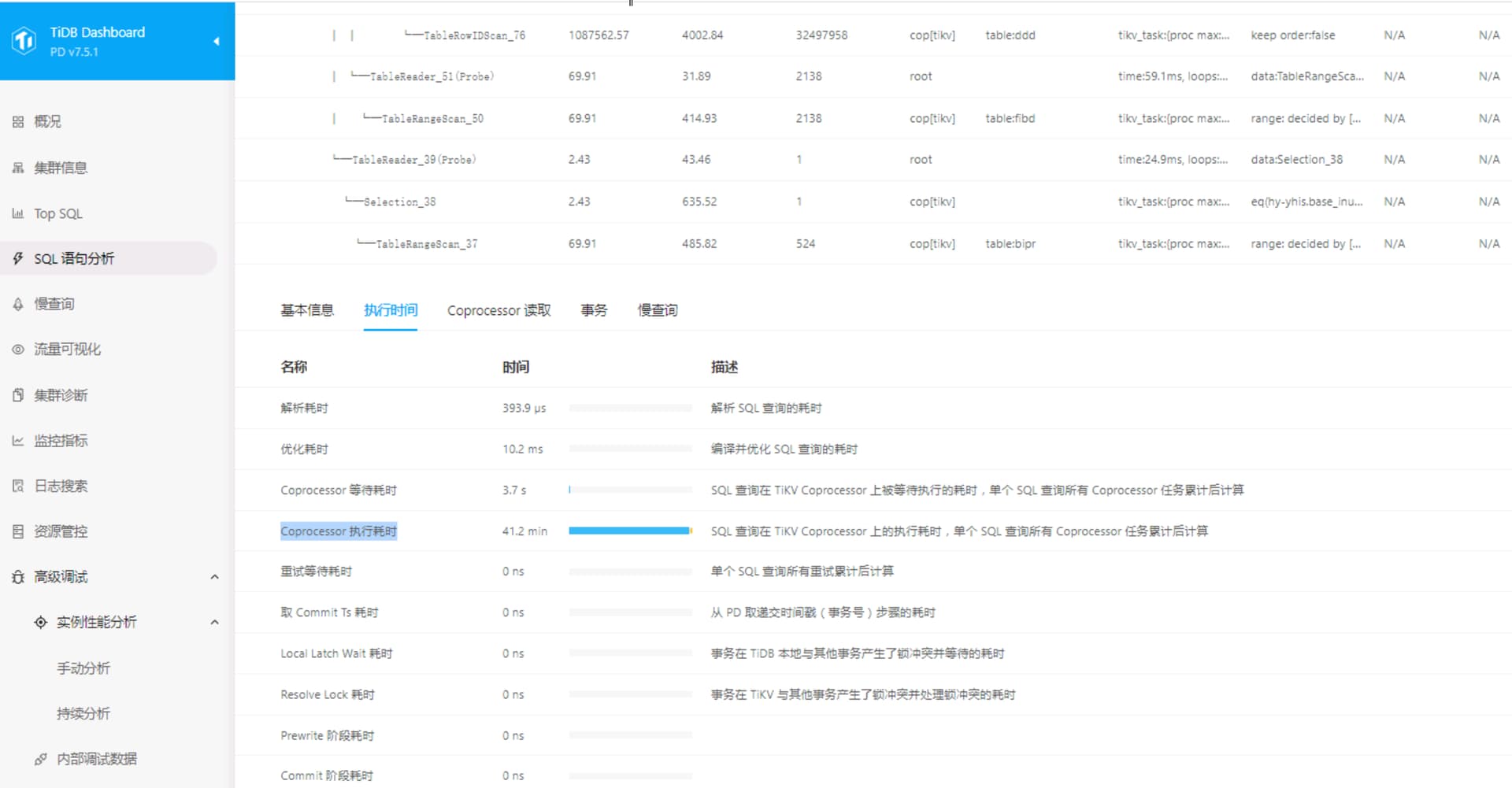
有条SQL显示SQL查询在TIKV Coprocessor上的执行耗时达到41.2min,SQL使用多个left join…where…group by…order by…, 请问这种SQL怎么优化呢?
- 过滤条件优先建索引:
WHERE子句的字段(尤其是等值条件)必须建索引,避免全表扫描。 - 关联字段建索引:
LEFT JOIN的被驱动表关联字段必须建索引,优先使用HashJoin而非Nested Loop。 - 覆盖索引优化聚合排序:如果
GROUP BY/ORDER BY字段和过滤条件可以组成联合覆盖索引,能避免回表,大幅减少 Coprocessor 计算量。
完整的语句和执行计划发下吧,
优化 SQL 就好了,初步看你的执行计划中回表比较多呢
发下完整的SQL和执行计划吧。
优先考虑索引,但是得先看看执行计划情况才好
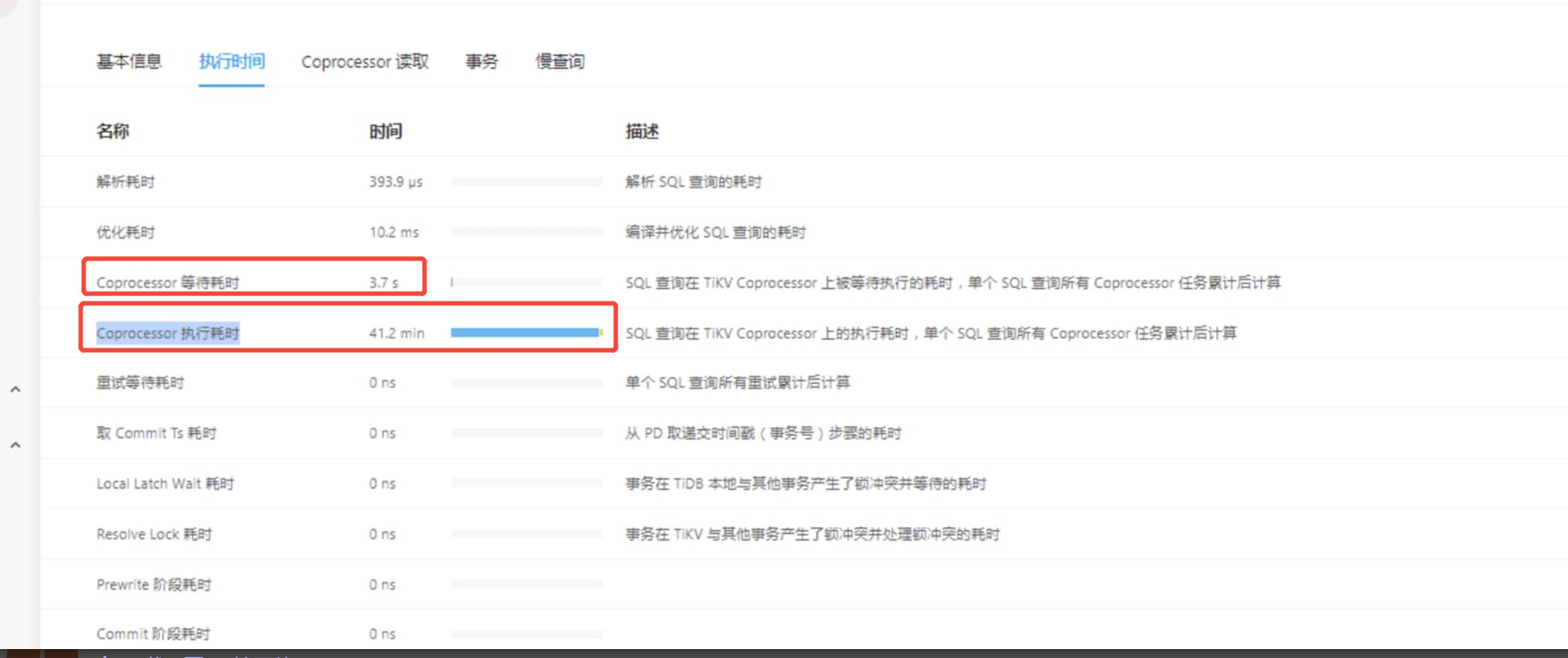
Coprocessor 执行耗时”高达 41.2 分钟 ,而 “Coprocessor 等待耗时”仅为 3.7 秒 。这意味着查询的大部分时间都花在了 TiKV 节点的实际数据处理上,而不是排队等待。sql本身需要优化,尤其是多个left join,当表数据量较多时,对性能影响较大。建立合适索引,以及减少回表次数,或者sql拆分
SQL和执行计划发出来看看