最近 TiKV_scheduler_latch_wait_duration_seconds 频繁告警,期间插入数据和更新数据很慢,时间都在prewrite 上

大家帮忙看下
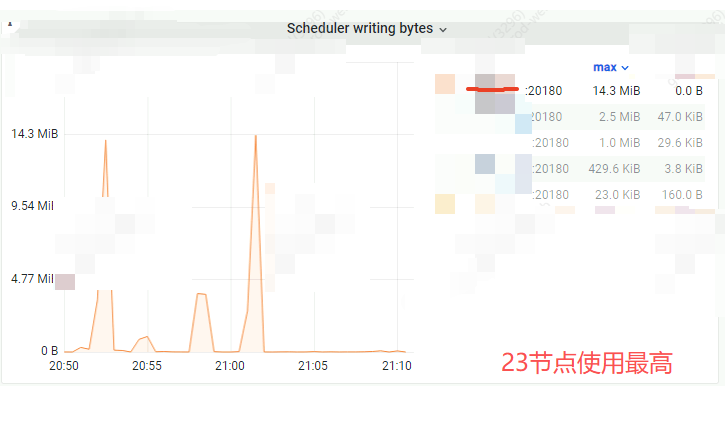
背景是:有5个tikv,告警的时候,发现其中23这个tikv的毛刺特别突出,怀疑是锁冲突,
tikv-details-scheduler->scheduler writing bytes
![5275d3f25f56366f0c735fcedf4942e4|690x408]
(upload://9XVMIgRFU4SEfomCOiiP1thnRTQ.png)
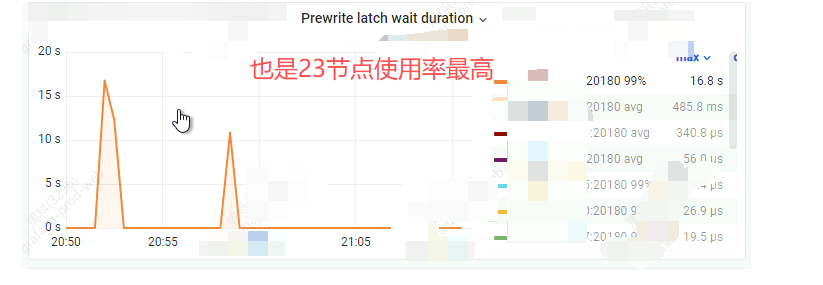
tidb-TiKV-Trouble-Shooting–>Write Too Slow–>Prewrite latch wait duration
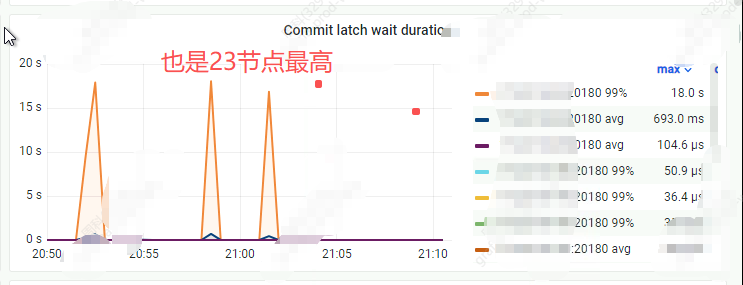
tidb-TiKV-Trouble-Shooting–>Write Too Slow–>Commit latch wait duration
疑问
1、我个人是倾向于是大批量并发写入造成锁争抢导致的,不太认为是热点
依据

因为raftstore 各个tikv 看起来还算是均衡
从tikv-details-grpc的监控图来看,更像是锁的争抢
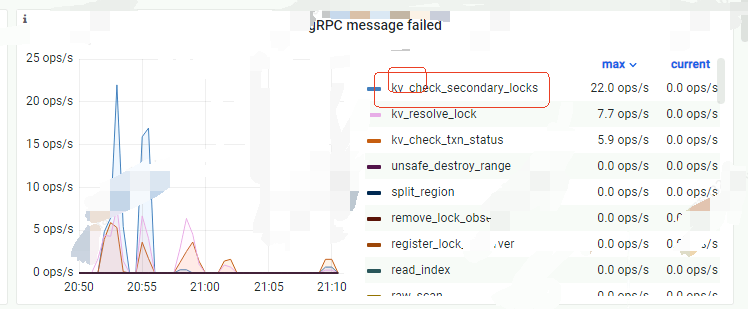
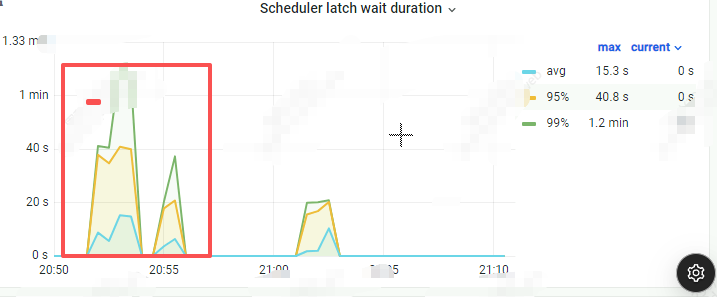
tikv-details-Scheduler - check_secondary_locks->Scheduler latch wait duration
上面scheduler latch wait duration 值很高
tikv-details-Scheduler->Scheduler - check_txn_status
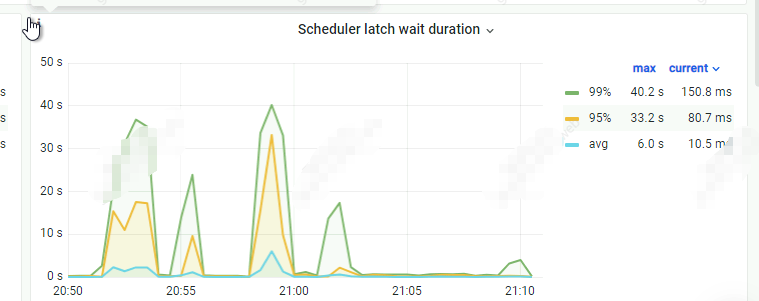
上面scheduler latch wait duration 值也是很高
并且告警时间段内的tikv 日志频繁刷这些
1157:[2026/04/29 20:51:12.510 +08:00] [WARN] [prewrite.rs:832] ["commit_ts is too large, fallback to normal 2PC"] [lock="Lock { lock_type: Put, primary_key: 748000000000059E4F5F6980000000000000030419B9BACCBA00000003800000EF7F6C3F4D0419B9BACCBA000000, start_ts: TimeStamp(465952327099482215), ttl: 3012, short_value: 017D0131, for_update_ts: TimeStamp(0), txn_size: 2, min_commit_ts: TimeStamp(465952327112327203), use_async_commit: true, secondaries: [748000000000059E4F5F6980000000000000030419B9BACCBB00000003800000EF7F6C3FF10419B9BACCBB000000, 748000000000059E4F5F6980000000000000040380000000027FBEE903800000EF7F6C3F4D0419B9BACCBA000000, 748000000000059E4F5F6980000000000000040380000000027FBEE903800000EF7F6C3FF10419B9BACCBB000000, 748000000000059E4F5F7203800000EF7F6C3F4D0419B9BACCBA000000, 748000000000059E4F5F7203800000EF7F6C3FF10419B9BACCBB000000], rollback_ts: [], last_change: Unknown, txn_source: 1, is_locked_with_conflict: false, generation: 0 }"] [max_commit_ts=465952327627178087] [min_commit_ts=465952328252915718] [start_ts=465952327099482215] [key=748000000000059EFF4F5F698000000000FF0000030419B9BACCFFBA00000003800000FFEF7F6C3F4D0419B9FFBACCBA0000000000FD] [thread_id=169]
从现有证据表明,我还是倾向于是锁冲突导致的