是的,正常情况下正在执行的sql可以查到,但是慢sql监控面板统计的都是已经执行完的sql,尚在进行中的只能到日志文件中查看
看一下TOPSQL,不过看起来有热块
看上去是遇到了热点问题

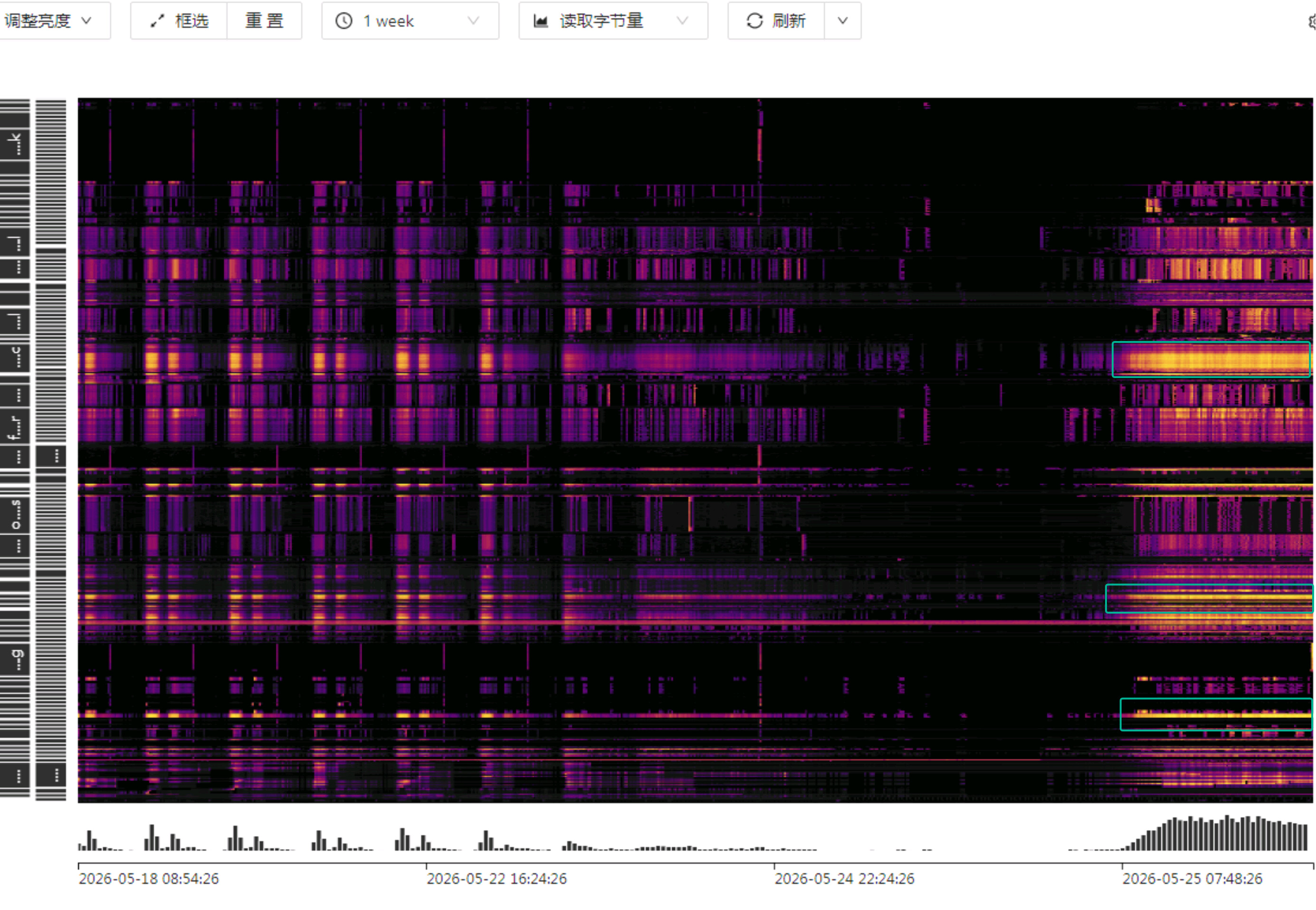
都有嫌疑。
这个图亮条,多了反倒抓不到重点。有一些表什么时候都是亮的(业务快的时候也亮),这些可以先排除。主要还是看,业务慢的时候,那些亮条是新出现的。
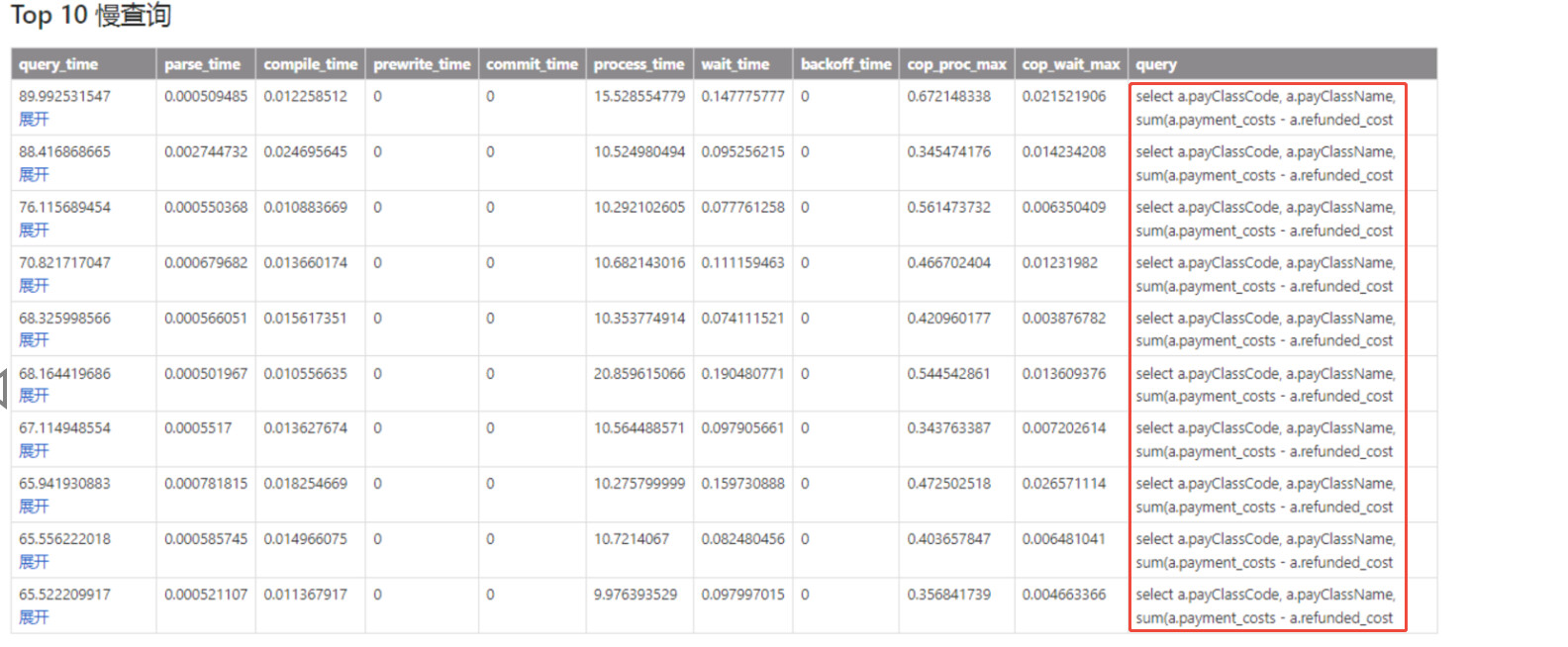
看看最热的sql执行计划
看上去没有明显的慢sql,是不是流量突然上长,延时有没有增加?
最后总结一句,tidb监控真娘的是鸡勒,完全无法确定是哪条SQL是导致CPU增长的,什么慢查询,什么SQL语句分析,什么TOP SQL,扯蛋,最终你会发现,这3个东西不能捕猎到一致点,最后你自己都迷糊了。
这句话说的比较贴切,出问题只能做问题定性,仔细分析还得靠内部字典
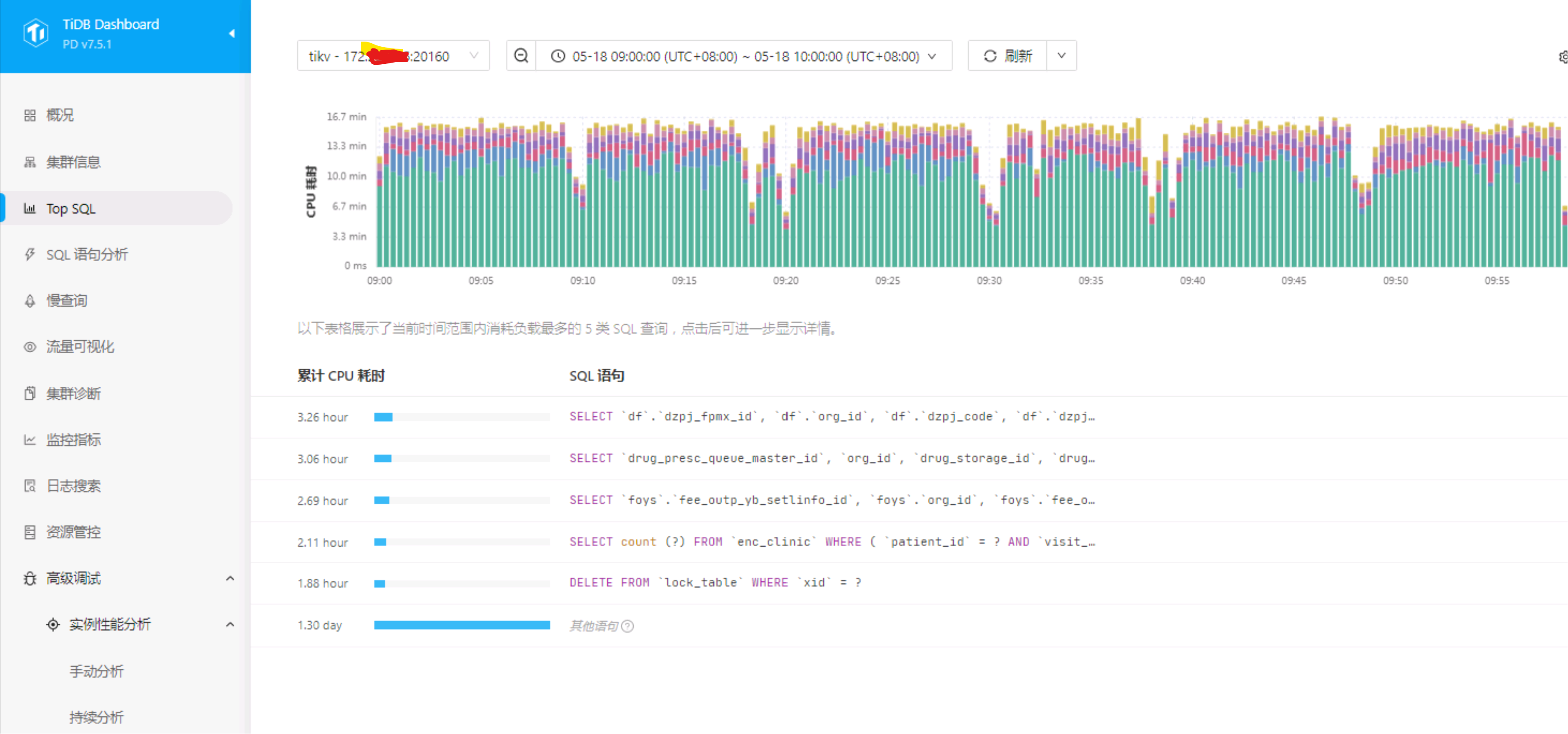
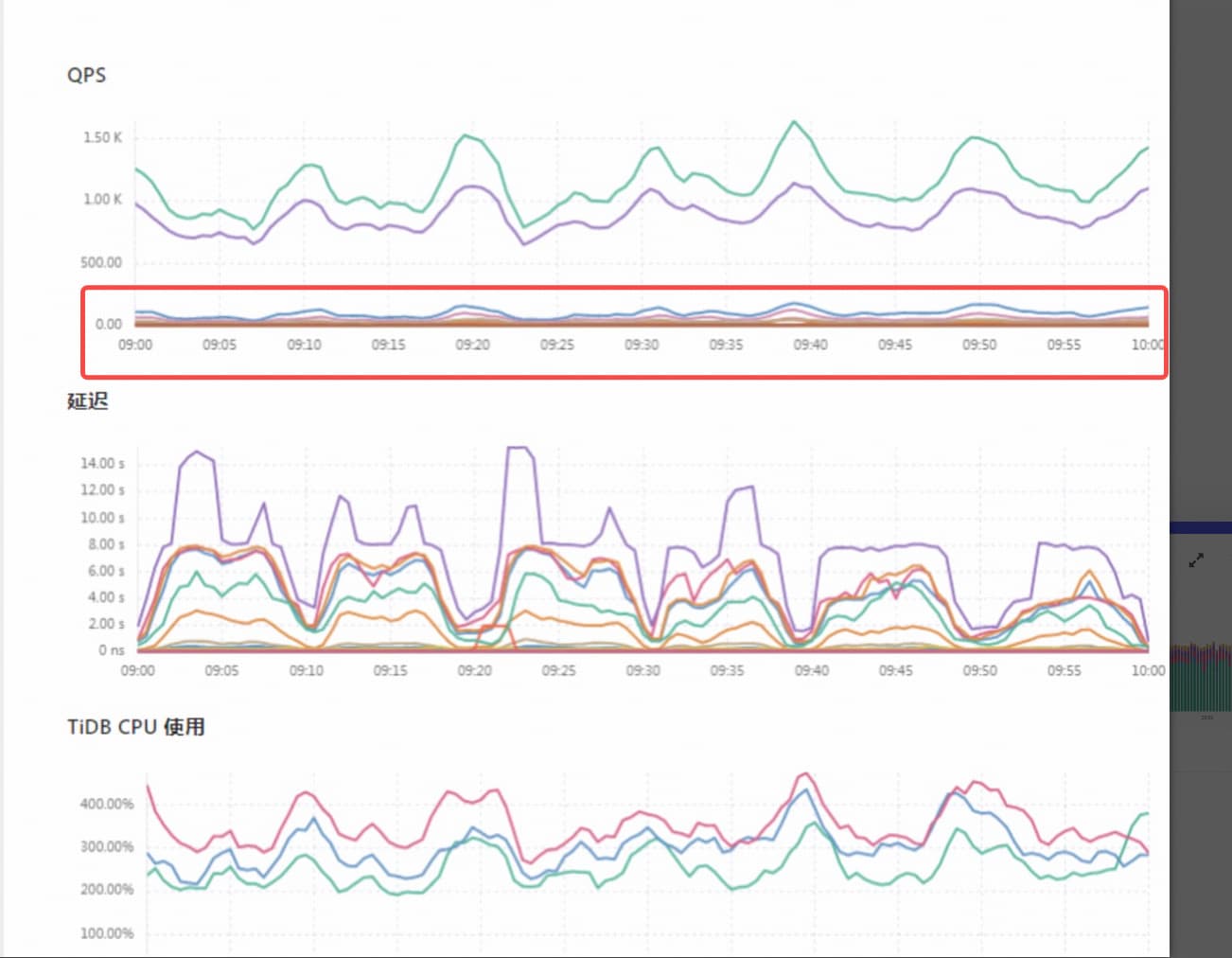
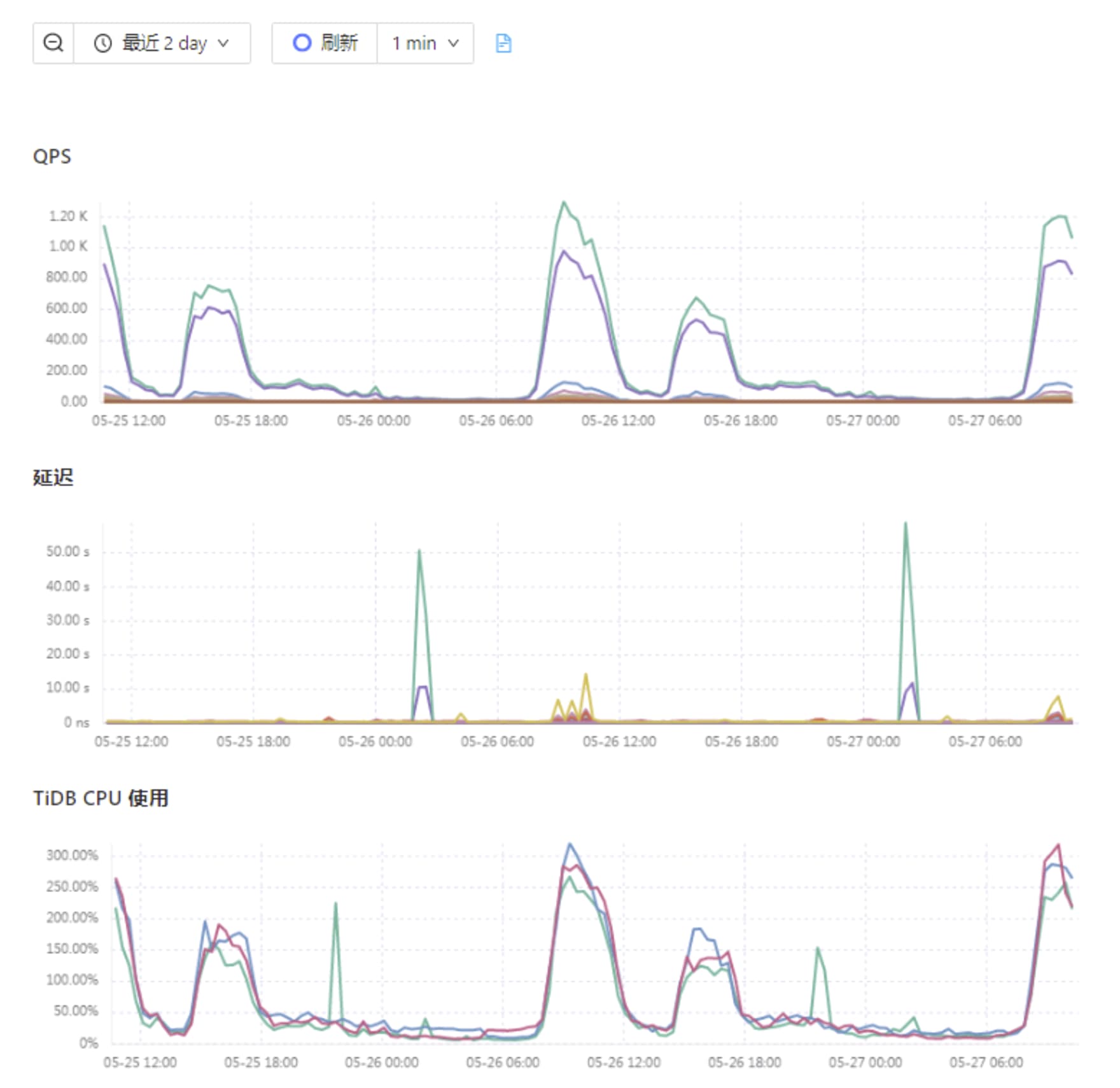
我是想问你,在 tikv cpu 飙高的对应时间前后,QPS 有明显上涨么。
如果有可能就是单纯 QPS 高导致的压力大。
监控上看一个 tikv cpu 高,而且是 read pool。那说明是读热点。
top sql 的图,tikv 选择的是 cpu 高的节点么,截图上来看,other 的含义是非 TOP 5 SQL,其他 SQL 占比 CPU 高。说明多数压力来自很多 SQL ,不是一个模式的 SQL。
有个老方法,你去对应 tikv 节点看日志,匹配关键字 slow-query .里面有一些 region 信息,看看 region 属于什么表的,反找对应表对应时间的 SQL。
看看查询条件和业务模型什么样的。
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues/
下次遇到这个情况,热力图选择频次看看能不能看出啥。